一、sklearn代码
from sklearn.linear_model import LogisticRegression
'''
(1)penalty:使用指定正则化项(默认:l2)
(2)dual: n_samples > n_features取False(默认)
(3)C:正则化强度,值越小正则化强度越大
(4)fit_intercept: 是否需要常量
'''
model = LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver=’liblinear’, max_iter=100, multi_class=’ovr’,
verbose=0, warm_start=False, n_jobs=1)
二、LG基本概述
- 在线性回归的基础上,再经过sigmoid这个非线性函数,将值转化为分类的概率。
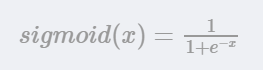
- 伯努利分布来分析误差
- 二分类问题
- 最大似然估计,是模型w必须让已出现样本出现的概率最大化
- 梯度下降来最小化损失函数
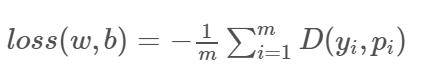
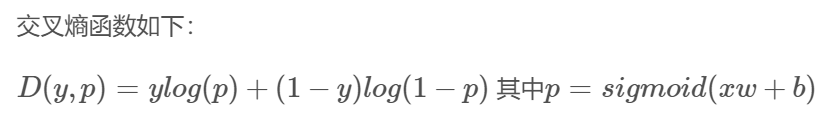
三、多分类问题
- softmax函数处理,归一化的指数函数
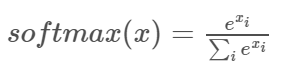
- 进行one-hot编码
