多分类问题主要使用拆解法,即如何通过将问题拆分成多个二分类问题和将各个分类器的分类结果进行集成得到最终的多分类结果。
经典的拆分策略有三种:
OvO,即一对一,即将训练集的N个类别两两分类得到N(N-1)个二分类器,测试的时候将样本都交给分类器,预测的类别最多的作为结果。
OvR,是每一次将一个类的样例作为正例,其他类的样例作为反例训练分类器,会产生N个分类器。测试的时候若仅有一个分类器预测为正类,则对应的类别标记 作为最终分类结果。若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。

MvM 是每次将若干个类作为正类,若干个其他类作为反类。
对于类的划分不能随意选取,通常采用“纠错输出码”,Error Correcting Output Codes,简称 ECOC)。
ECOC主要分为两部分:

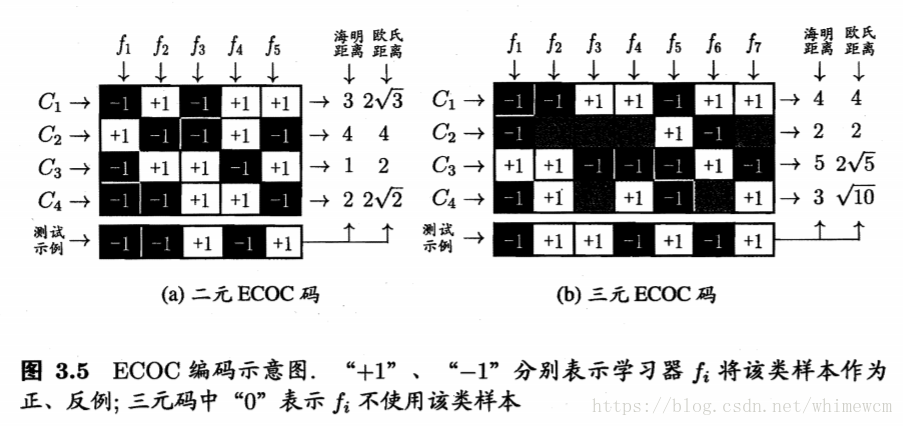
ECOC编码对分类器的错误有一定的容忍和修正能力。假如一个分类器出错了,在大多数分类器正常的情况下,基于“最近”这个原则,我们还是能够得出正确的分类。所以,编码越长,我们的分类器就越多,或者说分类的更细致,容错能力也更高。当然,训练的计算和存储代价也会提高。对有限类别数可能的组合数目是有限的,码长超过一定范圃后也就失去了意义。