Auto-Encoder (AE)
1)Auto-encoder概念
自编码器要做的事:将高维的信息通过encoder压缩到一个低维的code内,然后再使用decoder对其进行重建。“自”不是自动,而是自己训练[1],即无监督学习。
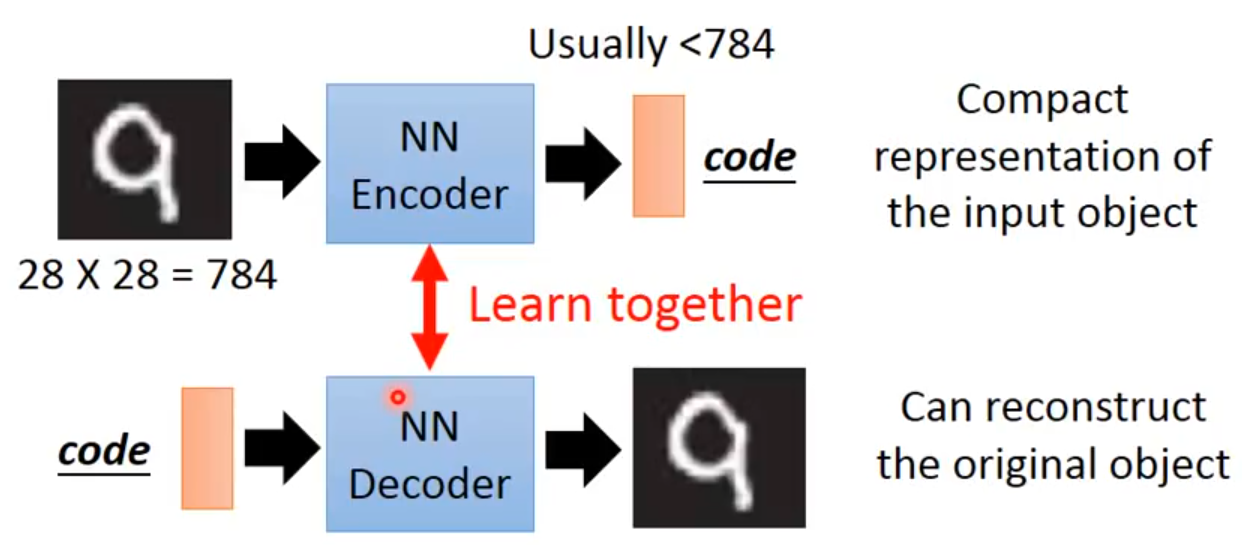
PCA要做的事其实与AE一样,只是没有神经网络。对于一个输入x,PCA通过一个转换矩阵W将x转换为c,因为是线性的过程,就可以再通过WT将其转换为x^,目的是使x和x^尽可能一致。而AE要做的就是,在这样一个过程中,将PCA的转换矩阵W,WT换成encoder和decoder。

在这样一个过程中,将input layer, bottleneck, output layer 换做深度神经网络,就变成了deep auto-encoder,最开始由hinton 在2006年提出,这一替换的明显好处是,引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像(X)的维度低非常多。

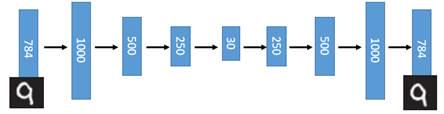
在一个手写数字图像的生成模型中,这样的一个简单的Deep Auto-Encoder模型能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)[2]。
2)Auto-encoder的应用
Auto-encoder可以用于解决小样本学习,预训练 DNN:当labeled data比较少的时候,对前几层网络进行合适的initialization是有必要的(目的就是找到比较好的特征),这是可以先用 unlabelled data 使用AE技术分别train并fix W1,W2,W3,最后只需要使用label data训练W4即可。如果是分类任务,就是先使用AE技术以无监督学习的方式预训练好编码器部分,目的是使得提取的初始特征比较好,然后在最后加上一个检测头(全连接)来预测类别,使用少量标签数据以有监督的方式去微调即可。

但是以上这种思路是较早之前的做法,近些年来在逐渐开源了一些大规模预训练模型,上述的效果不如直接在这些模型(比如VGG)上去做微调。
在判别模型,比如说分类任务,最重要的是找特征,而且是找到有判别的特征。
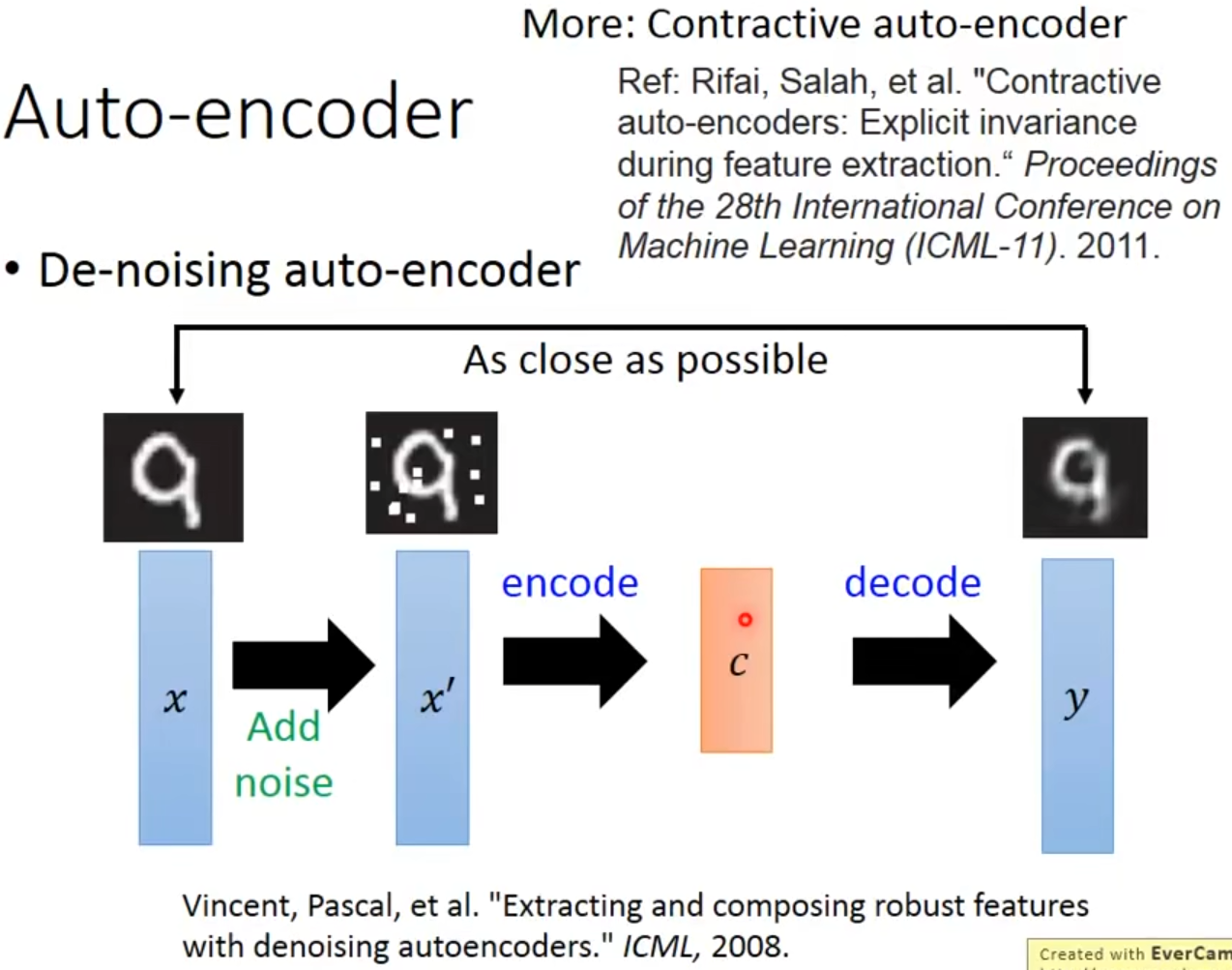
Auto-encoder还可以用来降噪:首先加噪,然后进行AE,目的是使网络不仅可以重构,还可以过滤其中的noise。这种方法叫做DAE,过程如下。
3)Auto-encoder for CNN
在CNN中应用auto-encoder,主要是先使用convolution和pooling降维,然后再使用deconvolution和unpooling升维。deconvolution叫做逆卷积,也是一个卷积操作,其对feature map恢复的原理核心就是(k-1-p)扩展(padding),详细可以阅读:Deconvolution(逆卷积)。unpooling与upsampling还是有点区别,unpooling是在CNN中常用的来表示max pooling的逆操作,简单来说,记住做max pooling的时候的最大item的位置,比如一个3x3的矩阵,max pooling的size为2x2,stride为1,反卷积记住其位置,unpooling的操作就是让其余位置至为0就行。

参考:
[1] https://www.bilibili.com/video/av15889450/?p=33
[2] http://www.gwylab.com/note-vae.html
Variational Auto-Encoder (VAE)
主成分分析(PCA)和自编码器(AutoEncoders, AE)是无监督学习中的两种代表性方法。两者都是非概率方法。
TODO: 看https://zhuanlan.zhihu.com/p/356516670中涉及到的概念,串起来。
1)为什么会有VAE?
AE的解码器,只能对码空间中遇到过的码去恢复图像,对于码空间中之前没有涵盖过的地方,AE没办法去decode。因为神经网络只能去做学习过的事情。
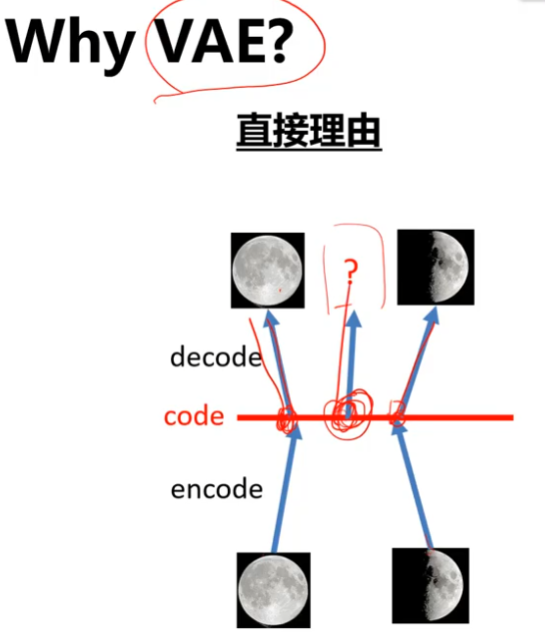
进一步的说,无论是AE,DAE,还是MAE,本质上都是学习bottleneck处的这个特征,然后拿它去做目标检测、分割、分类等这些下游任务。但这样的方式不叫做生成,原因就是中间特征c是一个用于重建的固定的特征,即使DAE或MAE等技术可以使得特征c更多地探索码空间,但他们永远不可能占满整个空间,因为它并不是一个概率分布,若是分布后,我们就可以进行采样,从而touch到整个码空间再生成图像,这样才能称为真正的生成。基于此,就出现了VAE,它中间不再生成一个特征,而是生成一个分布(高斯)。本质上是强迫中间这个表征在码空间中随机去取都会有意义。
2)VAE具体是怎么做的
具体地,VAE要做的就是:编码器生成的不再是一个固定的编码,而是生成一个分布。然后在训练解码器时,通过去在这样一个分布中随机采样,使得解码器能access整个码空间,从而能够拥有图像生成的能力。
编码器学习到的是一个分布(n维高斯分布),这个分布用均值m和标准差exp(σ)来表示。 用exp(σ)是为了保障标准差为正,因为标准差不可能为负。

编码器生成了分布(m和exp(σ))后,采样的过程是:
在训练时,除了最小化重构损失之外,还设计了另外一个损失: 。前两项的目的是:使σ_i趋于0,也就是exp(σ_i)趋于1。最后一项(mi)^2的目的是:L2正则化,希望产生的几个m值尽量分散点。
。前两项的目的是:使σ_i趋于0,也就是exp(σ_i)趋于1。最后一项(mi)^2的目的是:L2正则化,希望产生的几个m值尽量分散点。

3)从贝叶斯角度看VAE
高斯混合模型(GMM)
对于生成模型而言,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。高斯混合模型是指:任何一个数据的分布,都可以看作是若干高斯分布的叠加。
VAE的名字中“变分”,是因为它的推导过程用到了KL散度及其性质。
为什么要用正态分布?大部分部分其实并不符合正态分布,但是根据高斯混合模型可以得知,任何一个数据的分布,都可以看作是若干高斯分布的叠加。

但是混合高斯模型是有限个高斯,在VAE中,需要无限个高斯。
4)从贝叶斯角度看VAE
最后,从贝叶斯的角度来看,前面给定x生成z的过程相当于求后验概率p(z|x)的过程,学习出的z就是一个先验分布,最后有z了之后求x的过程,就是似然p(x|z)。这个网络要做的就是最大化后验的似然概率。

参考:
[1] https://www.youtube.com/watch?v=1aQtj8mTuF4
[2] http://www.gwylab.com/note-vae.html
[6] Doersch C. Tutorial on variational autoencoders[J]. arXiv preprint arXiv:1606.05908, 2016.