1 什么是Auto-Encoder
自编码器Auto-Encoder是无监督学习的一种方式,可以用来做降维、特征提取等。它包括两部分
- Encoder:对原始样本进行编码
- Decoder:对经过编码后的向量,进行解码,从而还原原始样本
如下图所示,对原始图片,先经过Encoder,编码为一个低维向量。然后利用这个低维向量,经过decoder,还原为原始图片。单独训练encoder和decoder,都是无法做到的。但把它们联合起来训练,是可以得到encoder和decoder的。
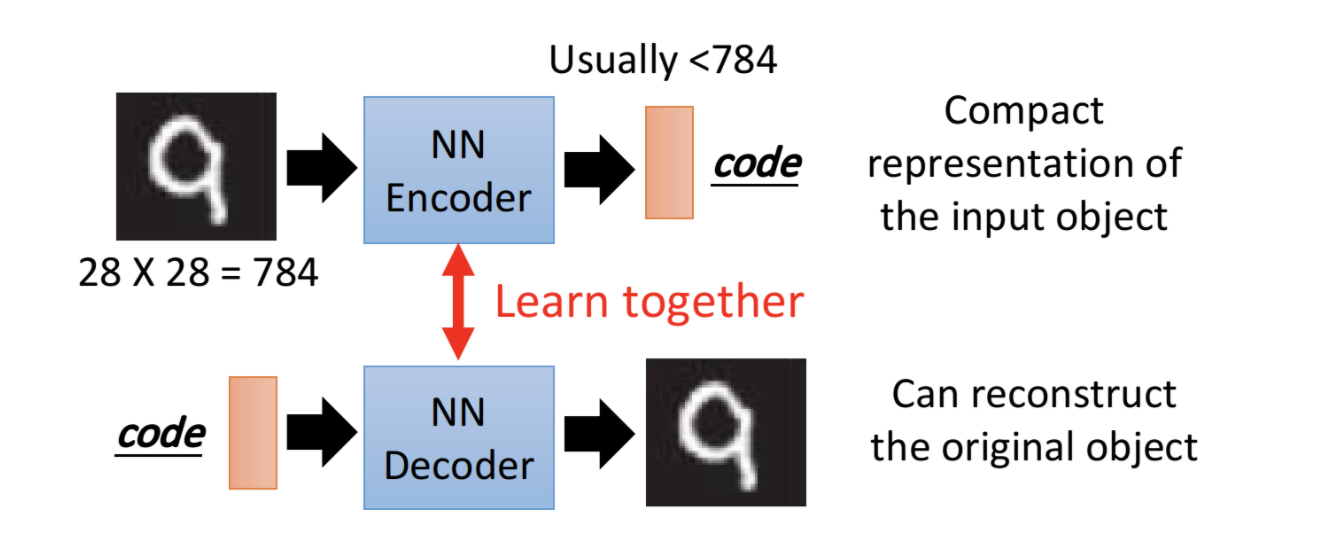
1.1 deep Auto-Encoder架构
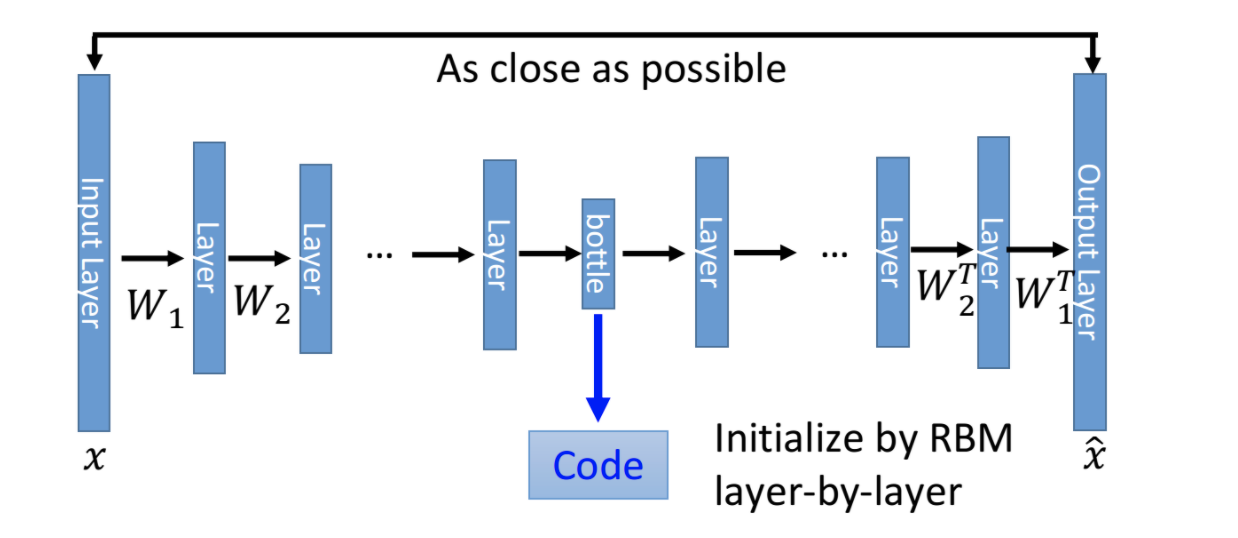
Deep Auto-Encoder架构如上图,来自Hinton 2006发表在Science上的文章,“Reducing the Dimensionality of Data with Neural Networks”。架构步骤如下
- 原始输入X,经过多层DNN layer,编码得到Code。它的维度一般比原始输入低很多,起到特征提取作用
- 编码得到的Code,经过多层DNN layer,解码得到输出X'
- 训练Encoder和Decoder,使得X'和X越接近越好。
Encoder和Decoder的各层参数,可以互为转置。这样就可以少一半参数,防止过拟合。但实际应用中,我们不必这样设置,Encoder和Decoder结构可以随意设置,只要二者联合训练就好了。这个架构和PCA有异曲同工之妙。区别在于PCA采用的是线性模型,而不是多层DNN。所以它的特征提取和样本重建能力都要差一些。
如下图所示,Deep Auto-Encoder的样本重建效果,明显比基于线性模型的PCA要好很多。主要原因还是采用了多层DNN的Encoder和Decoder,模型编码和解码能力,比线性模型要强很多。
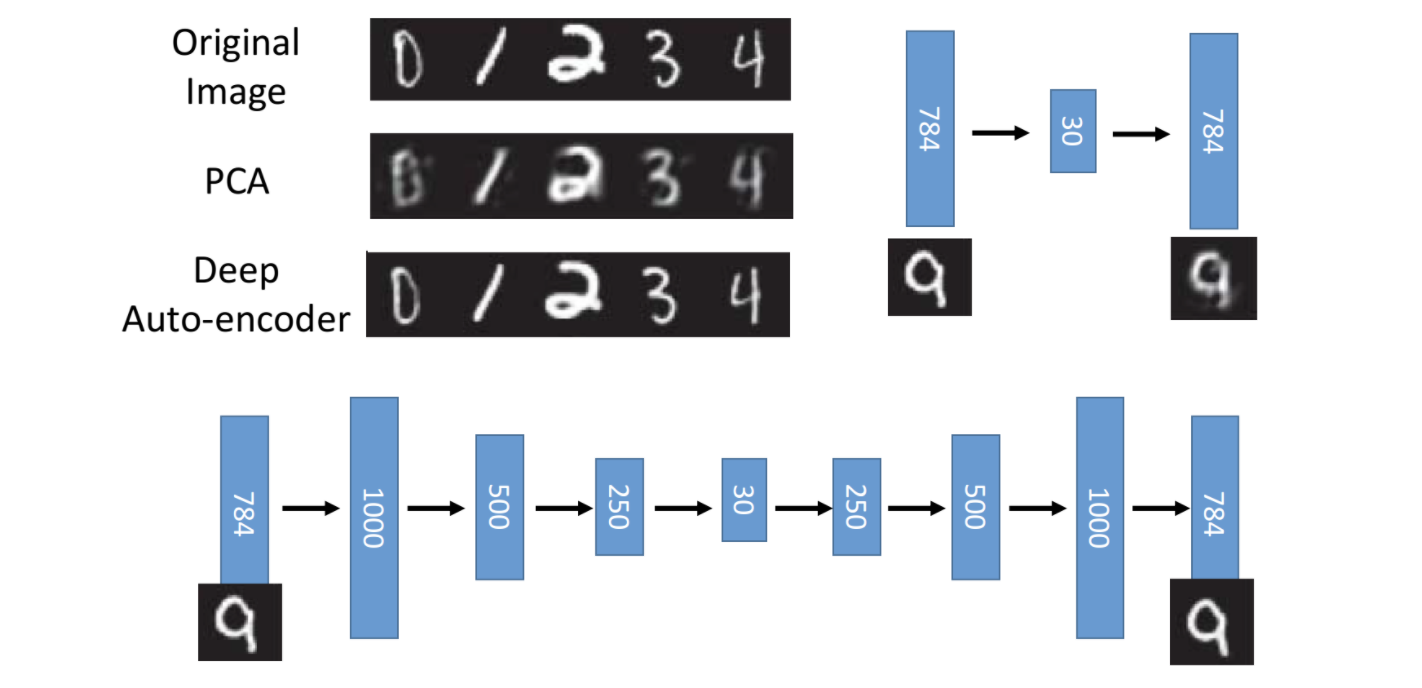
2 Auto-Encoder应用
2.1 文本检索
自编码器可以用在文本处理上。比如在文本检索领域,经常需要计算query和document的相关性。我们可以对query文本和document文本,分别编码为同一维度的向量。然后对二者计算cosine-similarity,值越大代表二者越相近。这个方法是make sense的。那么现在关键就是如何将文本编码为向量。
常用的文本编码方法有
- 词袋模型BOW(bag of words)。它利用词频对文本进行编码。BOW简单易懂,但效果很差。它丢失了词语顺序、语义、共现关系等高维信息。
- word-embedding。利用word2vec、GloVe或者fastText,可以先利用一个很大的语料,训练得到每个词语固定的embedding向量,然后组成句向量。这种方法在2016年左右用的很多,现在也经常使用。它同样使用起来比较方便,而且包含了词语顺序、语义和共现关系等高维信息,效果还是很不错的。但致命的缺点就是词向量是固定不变的,没有结合上下文信息,无法处理一词多义的问题。
- Auto-Encoder。对文本使用深度模型进行Encode,得到低维向量,然后再进行decode,还原为原始文本。BERT就是使用Auto-Encoder的一个典型例子。它对经过mask后的语句,进行编码,然后利用编码信息,预测出mask位置的token。模型目标为尽量还原原始语句。Auto-Encoder可以利用各种词语高维信息,而且由于是基于上下文的,故可以解决一词多义的问题。
2.2 图片搜索
图片搜索和文本检索一样,需要计算图片相似度。其中的关键同样是,如何对图片进行编码。采用Auto-Encoder就是一种不错的方案。如下图
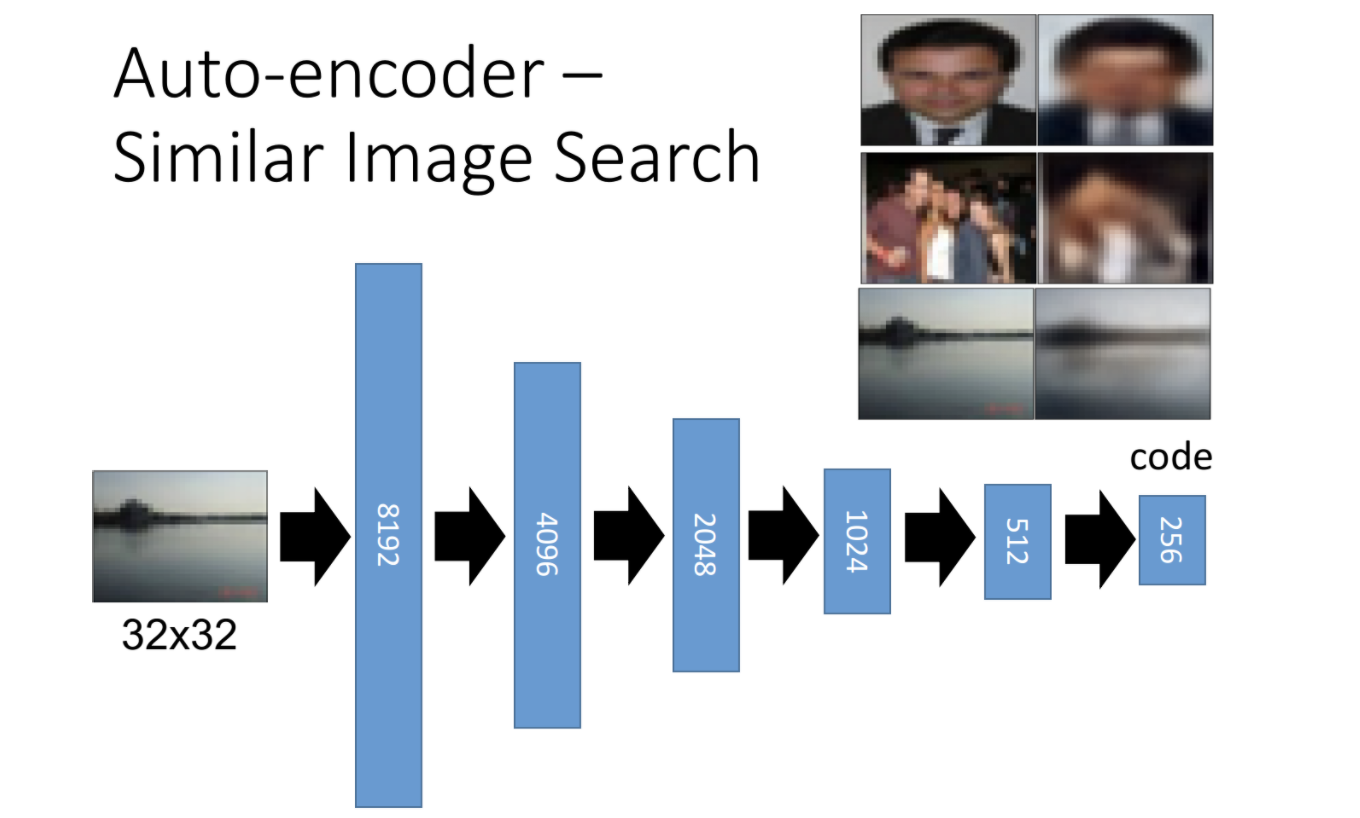
我们先利用大量图片数据,训练一个Auto-Encoder。然后利用这个自编码器,对两个输入图片进行特征提取,得到两个低维向量,计算二者的余弦距离即可计算它们的相似度。这样比直接基于pixel,或者线性模型的方法,效果要好很多。因为它利用深层模型,可以学到很多高维特征信息。
2.3 Pre-training DNN
训练神经网络时,如何对网络参数进行初始化,一直都是一个很关键但很头疼的问题。我们可以利用自编码器,来实现模型参数初始化,也就是预训练 pre-trainning
如下图所示,利用自编码器进行pre-train的步骤如下
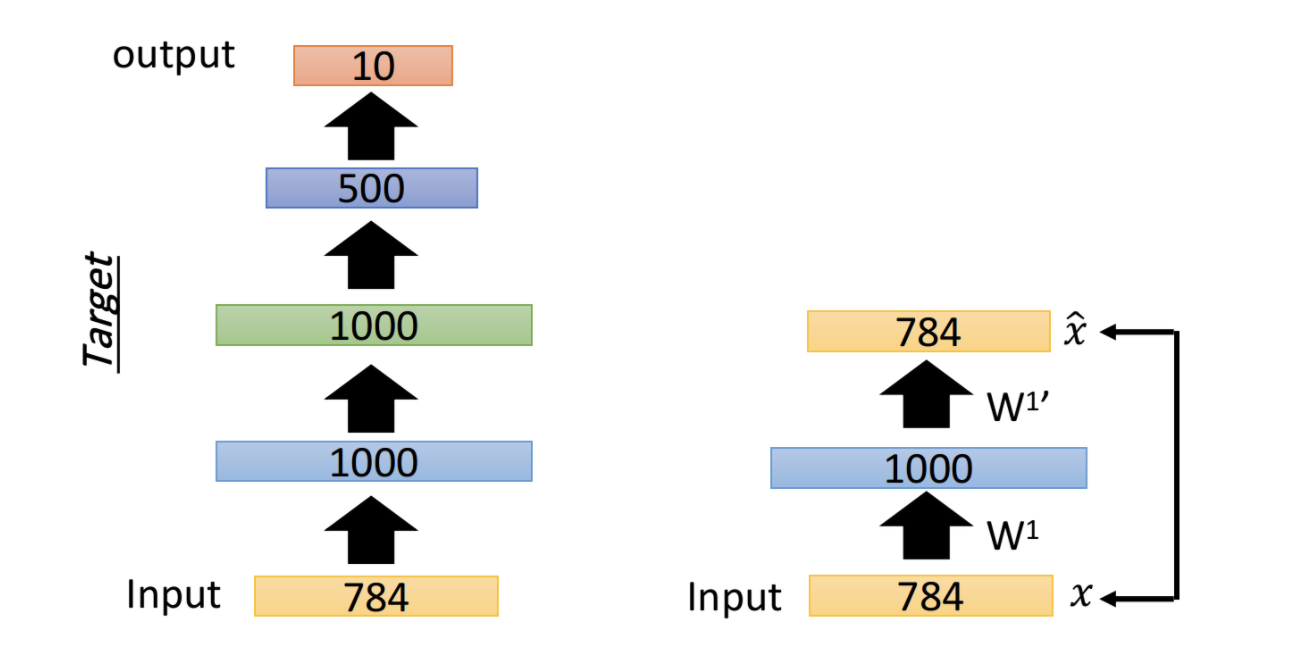
- 先预训练第一层参数w1。构建一个自编码器,它的输入直接经过w1编码为一个1000维向量,然后再经过w1'解码为输出,使得输入和输出尽量接近,即可训练得到w1
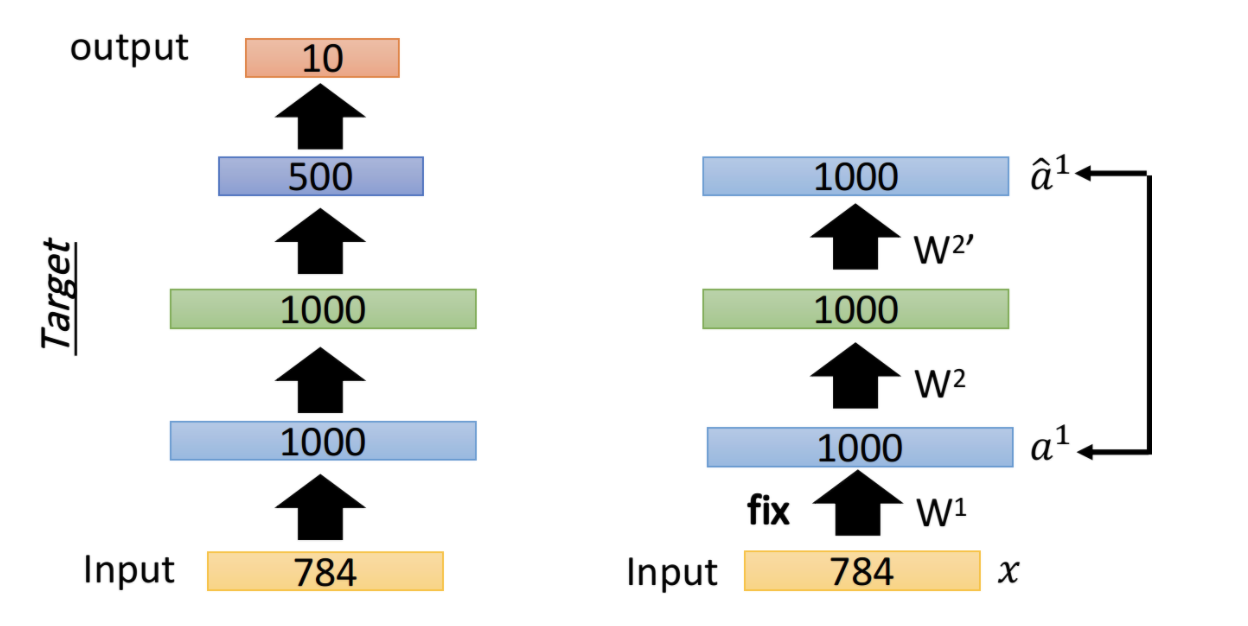
- 固定住第一层参数w1,训练第二层参数w2。同样的,输入x先经过第一层w1,得到a1。然后a1经过w2编码,得到embedding向量,然后再经过w2'解码,还原为a1'。训练w2,使得a1和a1'尽量接近,即可得到参数w2
- 固定住第一层参数w1和第二层参数w2,继续训练剩下的layer。最终即可得到所有层的预训练参数。
当数据量足够,且机器资源充足,训练收敛快时,我们没必要使用自编码器进行预训练。但对于一些半监督场景,比如只有少量labeled data,有大量unlabeled data时,我们完全可以先用unlabeled data进行pretrain,然后再在labeled data上进行fine-tune。现在流行的各种BERT,就是这种pretrain-finetune二阶段训练的典型例子。
3 CNN中的Auto-Encoder
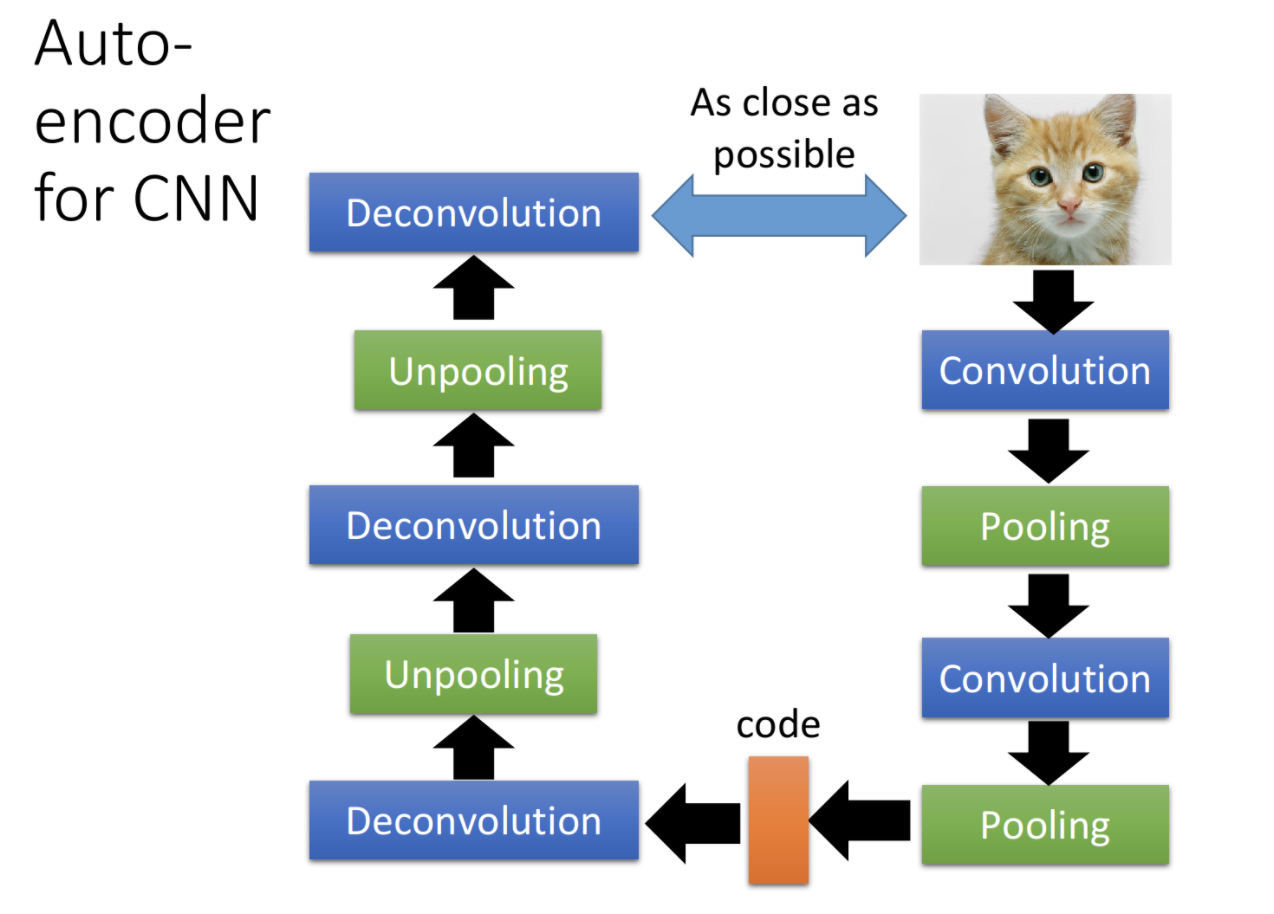
CNN中的自编码器,和DNN中没有本质区别。也是需要先进行Encode,然后进行Decode,使得输入和输出尽量一致。关键点在于CNN encoder中使用了卷积和池化,故decoder必须使用反卷积和反池化。如下图
3.1 unpooling反池化
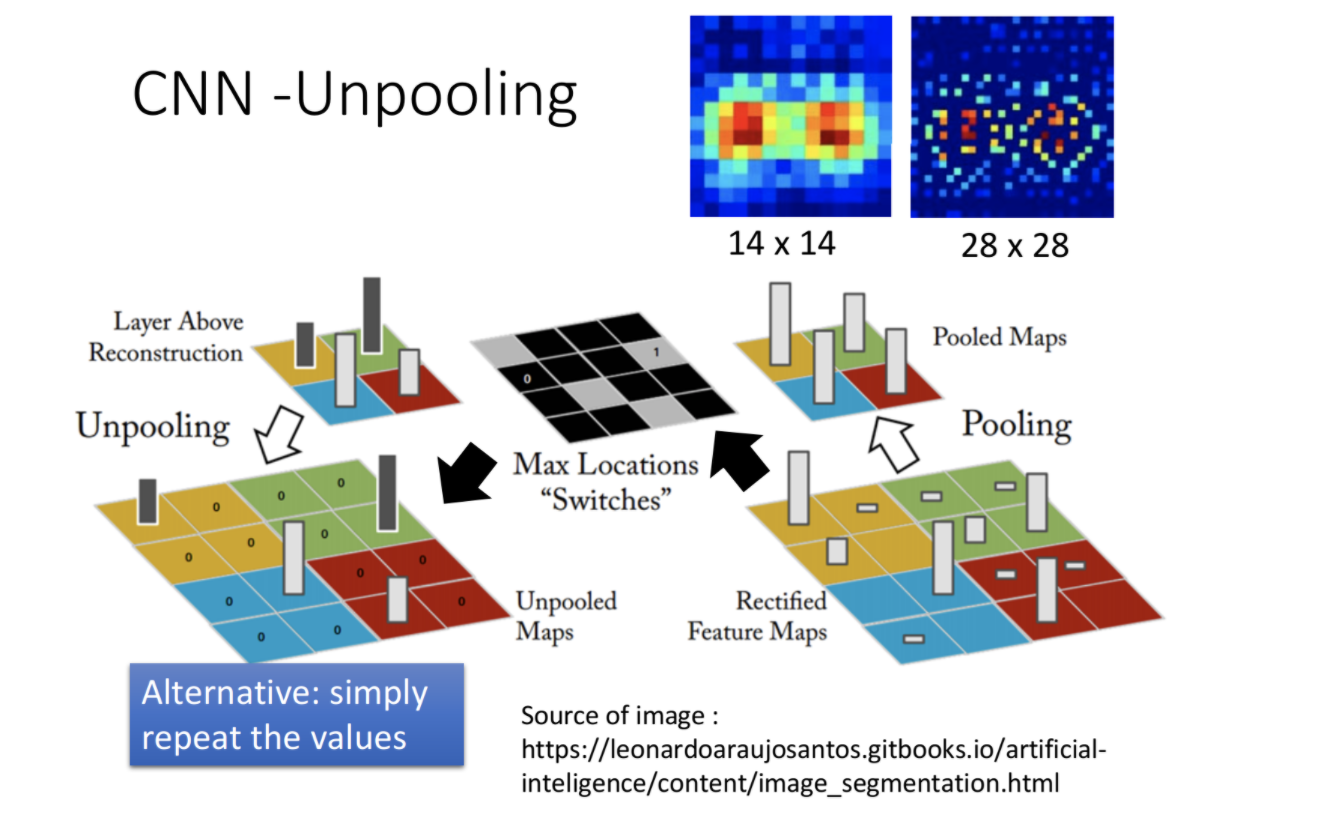
CNN中经常用到的是最大值池化,它取区域中最大的值,来代替该区域,从而做到降维。反池化可以采用多种方法,典型的方法有
- 池化时记住最大值位于区域哪个点,反池化时,最大值的点填充池化后的值,其他点填充0
- 反池化时,直接对区域内所有点,填充最大值。此时不需要记住池化时最大值位于区域哪个点。
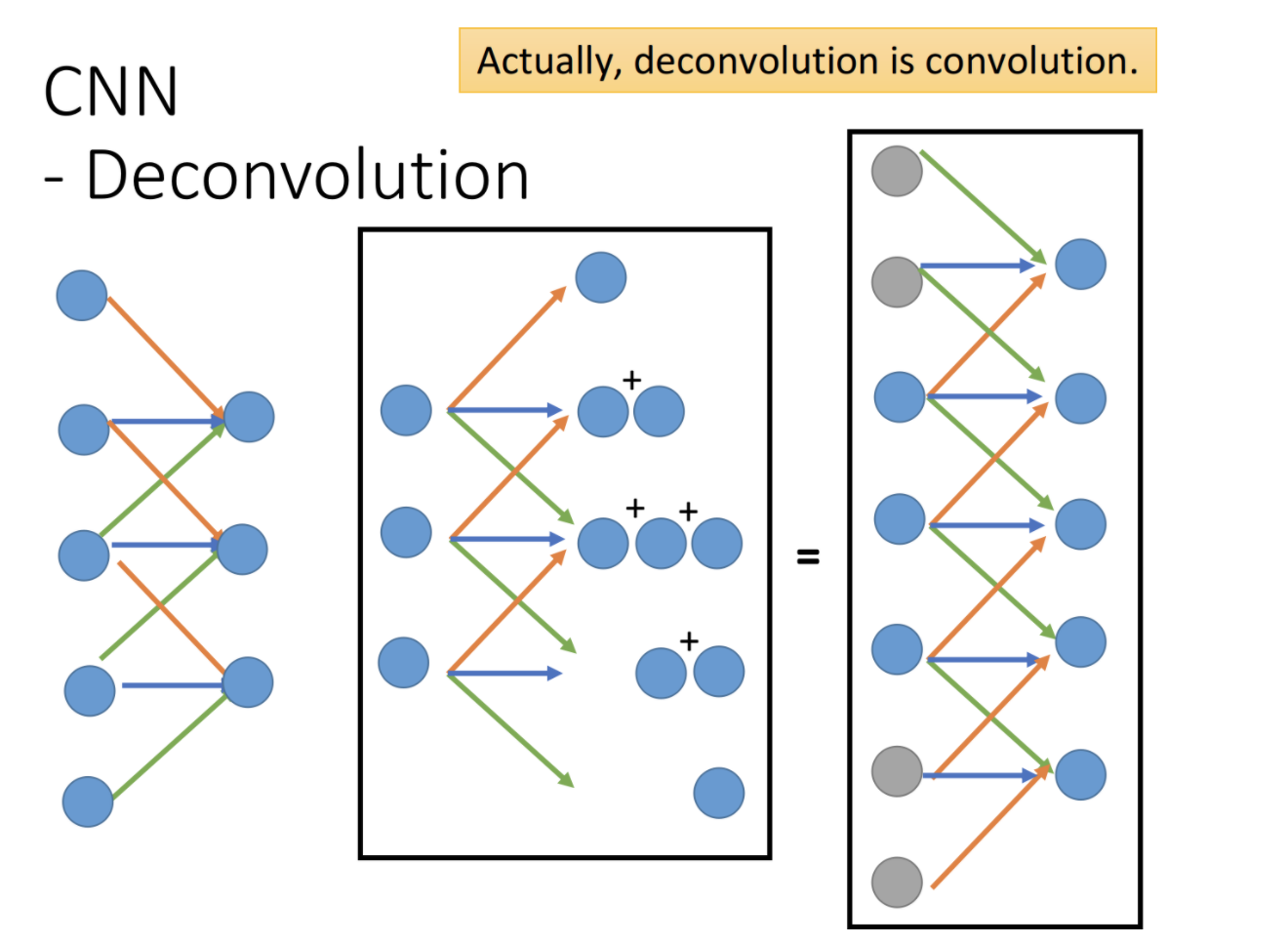
3.2 Deconvolution反卷积
反卷积可以通过加padding,然后进行卷积来实现。如下图
4 其他Auto-Encoder
4.1 De-noising Auto-encoder 去噪自编码器
去噪自编码器,对原始输入,增加了一些噪声,然后再经过自编码器的encoder和decoder,来还原原始图片。它强迫模型学习分辨噪声的能力,可以提升自编码器的鲁棒性。如下图
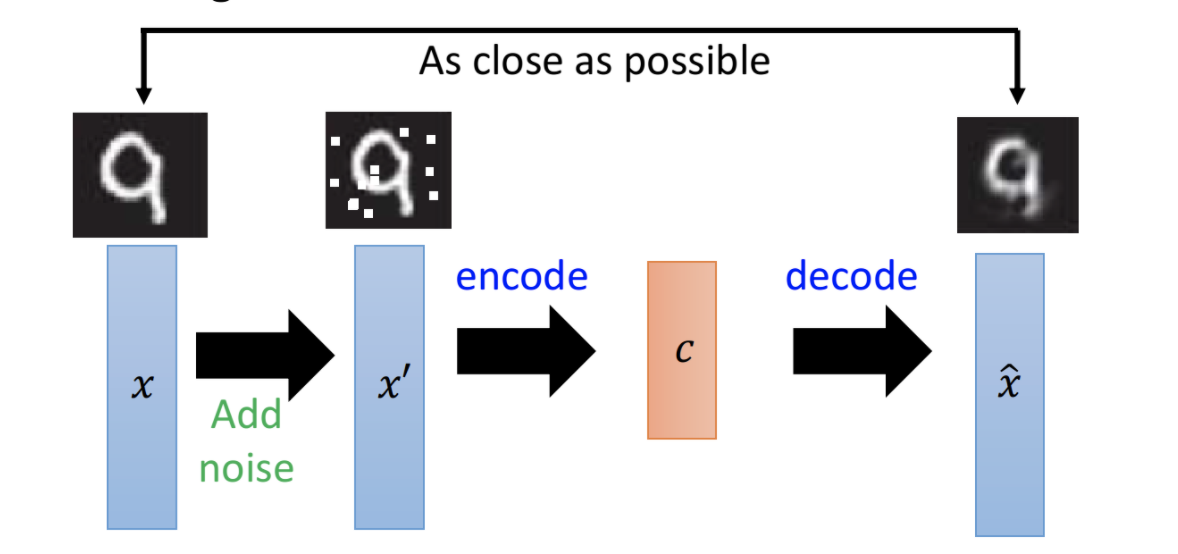
Vincent, Pascal, et al. "Extracting and composing robust features with denoising autoencoders." ICML, 2008.
4.2 Seq2Seq Auto-encoder
自编码器的训练目标是,模型输入和输出越接近越好。那我们能否有其他学习目标呢。答案是肯定的。在文本领域,我们除了学习sequence的句向量之外,语句和语句间的前后关系,其实也是很有用的。seq2seq自编码器,可以利用当前语句,来预测下一语句或上一语句。

如上图所示,训练时我们构建next文本和random文本。对current、random、next均进行编码,然后判断current和next、current和random,是否是下一句关系。如此则可以利用训练好的模型,来进行next sequence predict。
4.3 Variational Auto-Encoder 变分自编码器
变分自编码器其实是去噪自编码器的一种,它可以大大提升自编码器的鲁棒性。其结构如下
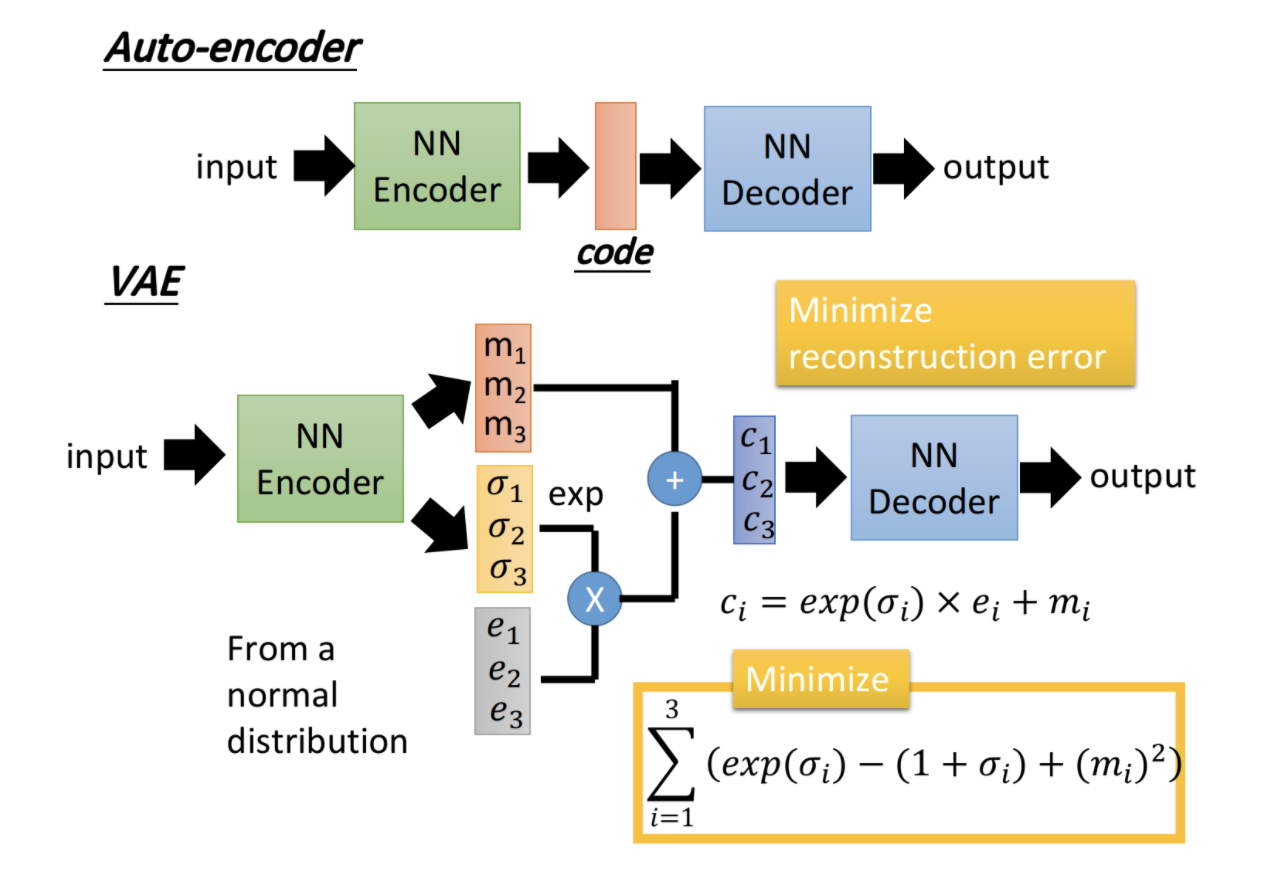
VAE的改进在于,中间code位置,加入了噪声。Encoder输出m和σ,我们再从正态分布中随机取出点e,最终编码结果如下
![]()
其中参数的意义是
- m代表了原始未加入噪声的Auto-Encoder的编码输出
- c代表加入noise之后的编码输出
- σ代表了noise的大小,取exp保证了noise永远都是正的
- e为正态分布中随机选取的点
VAE的优化目标有两个,除了输出和输入要尽量接近外,还对噪声部分做了限制,最小化下式
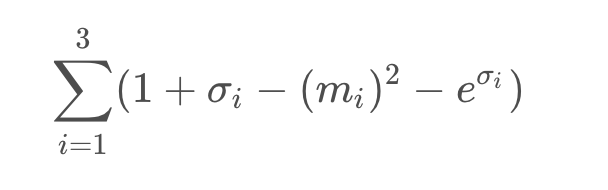
VAE生成的图片一般都不清晰,它是对输入图片的模仿,不算真正意义上的创造(GAN可以认为是真正意义的创造)。