在上一篇文章中《Tensorflow入门图像分类-猫狗分类-安卓》,介绍了使用TensorFlow训练一个猫狗图像分类器的模型并在安卓应用上使用的全过程。
在这一篇文章中,将采用 MobileNet 来重新训练一个猫狗图像分类器。
一、 MobileNet 介绍
MobileNet是一种轻量级的神经网络架构,主要用于移动和嵌入式设备上的计算机视觉应用。它由Google Brain团队开发,旨在通过减少模型参数数量和计算复杂性来实现高效的图像分类、目标检测和语义分割等任务。
MobileNet采用了深度可分离卷积(depthwise separable convolution)来替代传统卷积操作,从而大幅降低了计算成本。深度可分离卷积将卷积操作分为两个步骤:首先对每个输入通道进行单独的空间卷积,然后再对通道之间的结果进行逐点卷积。这种方法可以显著地减少模型中的参数数量和计算量,并且可以在保持较高准确率的同时,将模型压缩到原始模型的很小部分。
MobileNet还使用了全局平均池化层来代替全连接层,以进一步减少模型大小和计算复杂度。此外,它还引入了线性瓶颈结构和批规范化(batch normalization)技术来提高性能和稳定性。
总体来说,MobileNet是一种非常有效的神经网络架构,可以在移动和嵌入式设备上实现高效的计算机视觉应用。
二、数据准备
本实例依然是采用上一篇文章介绍的猫狗数据集。链接:Download Kaggle Cats and Dogs Dataset from Official Microsoft Download Center
同样需要把数据集中的脏数据清除掉:
import os
from PIL import Image
# Set the directory to search for corrupted files
directory = 'path/to/directory'
# Loop through all files in the directory
for filename in os.listdir(directory):
# Check if file is an image
if filename.endswith('.jpg') or filename.endswith('.png'):
# Attempt to open image with PIL
try:
img = Image.open(os.path.join(directory, filename))
img.verify()
img.close()
except (IOError, SyntaxError) as e:
print(f"Deleting {filename} due to error: {e}")
os.remove(os.path.join(directory, filename))接着需要把数据集分为:训练集、测试集、验证集。
参考代码:
# 将数据集分为训练集、测试集、验证集
import os
import shutil
import numpy as np
train_dir = os.path.join(os.path.dirname(dataset_dir), 'PetImages_train')
val_dir = os.path.join(os.path.dirname(dataset_dir), 'PetImages_validation')
test_dir = os.path.join(os.path.dirname(dataset_dir), 'PetImages_test')
if not os.path.exists(train_dir):
train_ratio = 0.7 # 训练集比例
val_ratio = 0.15 # 验证集比例
test_ratio = 0.15 # 测试集比例
classfiers = ['Cat', 'Dog']
for cls in classfiers:
# 获取数据集中所有文件名
filenames = os.listdir(os.path.join(dataset_dir, cls))
# 计算拆分后的数据集大小
num_samples = len(filenames)
num_train = int(num_samples * train_ratio)
num_val = int(num_samples * val_ratio)
num_test = num_samples - num_train - num_val
# 将文件名打乱顺序
shuffle_indices = np.random.permutation(num_samples)
filenames = [filenames[i] for i in shuffle_indices]
os.makedirs(os.path.join(train_dir, cls), exist_ok=True)
os.makedirs(os.path.join(val_dir, cls), exist_ok=True)
os.makedirs(os.path.join(test_dir, cls), exist_ok=True)
# 拆分数据集并复制文件到相应目录
for i in range(num_train):
src_path = os.path.join(dataset_dir, cls, filenames[i])
dst_path = os.path.join(train_dir, cls, filenames[i])
shutil.copy(src_path, dst_path)
for i in range(num_train, num_train+num_val):
src_path = os.path.join(dataset_dir, cls, filenames[i])
dst_path = os.path.join(val_dir, cls, filenames[i])
shutil.copy(src_path, dst_path)
for i in range(num_train+num_val, num_samples):
src_path = os.path.join(dataset_dir, cls, filenames[i])
dst_path = os.path.join(test_dir, cls, filenames[i])
shutil.copy(src_path, dst_path)三、模型训练
3.1 准备
import os
import tensorflow as tf
from tensorflow.keras import layers3.2 数据加载和数据增强
# 加载数据集
train_dir = 'I:/数据集/kagglecatsanddogs_5340/PetImages_train'
val_dir = 'I:/数据集/kagglecatsanddogs_5340/PetImages_validation'
test_dir = 'I:/数据集/kagglecatsanddogs_5340/PetImages_test'
batch_size = 32
image_size = 224
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(image_size, image_size),
batch_size=batch_size,
class_mode='categorical')
val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(image_size, image_size),
batch_size=batch_size,
class_mode='categorical')这段代码主要用于数据预处理和数据生成器的创建,用于训练和验证深度学习模型。
首先,指定了训练、验证和测试数据集所在的文件夹路径。batch_size变量表示每个批次的图像数,image_size变量表示将图像调整为的统一大小。
然后,创建一个ImageDataGenerator对象,train_datagen,来对输入图像进行数据增强(rescale、shear_range、zoom_range和horizontal_flip),从而扩充我们的训练数据集。
接着,使用train_datagen.flow_from_directory函数来创建一个训练集的数据生成器train_generator,它将自动从train_dir目录中读取图像,并实时地将其转换为张量批次,以便于训练模型。class_mode参数设为'categorical'表示使用分类标签。
同样的,也创建了一个ImageDataGenerator对象val_datagen,只应用了图像缩放操作。接着使用val_datagen.flow_from_directory函数创建了一个验证集的数据生成器validation_generator,class_mode参数也设置为'categorical',以便于评估模型的精度。
3.3 模型设计
input_shape = (image_size, image_size, 3)
num_classes = 2
# 加载预训练模型
base_model = tf.keras.applications.MobileNetV2(input_shape=input_shape, include_top=False, weights='imagenet')
# 冻结前面的层
for layer in base_model.layers:
layer.trainable = False
# 添加新的全连接层
x = base_model.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(128, activation='relu')(x)
x = layers.Dropout(0.5)(x)
predictions = layers.Dense(num_classes, activation='sigmoid')(x)
# 构造完整模型
model = tf.keras.models.Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy'])首先,指定了输入图像的形状(input_shape)和分类数目(num_classes)。
然后,使用tf.keras.applications.MobileNetV2函数加载了一个已经预先训练好的MobileNetV2模型,该模型作为神经网络的基础架构。include_top参数被设置为False,表示只需要模型的卷积部分,而不需要其全连接层。weights参数被设置为'imagenet',表示使用在ImageNet上预训练的权重值。
接着,将MobileNetV2模型中的所有层都冻结起来,即将它们的trainable属性设为False,这样在训练过程中它们的权重将不会被更新。
添加新的全连接层,其中 x = base_model.output 表示将MobileNetV2的输出作为新模型的输入;layers.GlobalAveragePooling2D() 将每个特征图中所有位置的值取平均值,得到一个固定长度的向量;Dense(128, activation='relu') 表示添加一个包含128个神经元的全连接层,并使用ReLU激活函数进行非线性变换;layers.Dropout(0.5) 表示在全连接层后面加上一个dropout层,以减少过拟合风险;最后一层layer.Dense(num_classes, activation='sigmoid')则根据我们的分类任务,使用sigmoid激活函数输出概率值。
最后,使用tf.keras.models.Model将MobileNetV2模型和新添加的全连接层拼接在一起,生成完整的深度学习模型。对生成的模型进行编译,设置优化器(Adam)和损失函数(binary_crossentropy),并指定评估指标(accuracy)。
3.4 模型训练
# 训练模型
epochs = 5
steps_per_epoch = train_generator.n // batch_size
validation_steps = validation_generator.n // batch_size
history = model.fit(
train_generator,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_steps)首先,指定了epochs参数表示要遍历整个训练集的次数。steps_per_epoch表示每个epoch中要进行的步骤数,这里通过train_generator.n // batch_size来确定。同样地,validation_steps也是通过validation_generator.n // batch_size来确定。
接着,使用model.fit函数开始训练模型。train_generator和validation_generator分别是训练集和验证集的数据生成器;steps_per_epoch、epochs和validation_steps则是前面定义好的参数;validation_data表示使用哪个数据集用来做验证;history = model.fit返回一个History对象,包含了训练过程中的损失值和评估指标等信息。
在模型训练期间,每个epoch都会将训练集中的所有样本送入模型进行训练,并将验证集的结果返回给我们,以便于我们查看模型的性能表现。最后,我们可以使用得到的History对象来分析模型在训练和验证阶段的表现情况,并据此进行调优。
代码输出:
Epoch 1/10 546/546 [=======] - 135s 239ms/step - loss: 0.1517 - accuracy: 0.9488 - val_loss: 0.0612 - val_accuracy: 0.9797Epoch 2/10 546/546 [=======] - 125s 230ms/step - loss: 0.0720 - accuracy: 0.9749 - val_loss: 0.0544 - val_accuracy: 0.9826
Epoch 3/10 546/546 [=======] - 128s 234ms/step - loss: 0.0615 - accuracy: 0.9788 - val_loss: 0.0531 - val_accuracy: 0.9818
Epoch 4/10 546/546 [=======] - 124s 228ms/step - loss: 0.0557 - accuracy: 0.9805 - val_loss: 0.0525 - val_accuracy: 0.9810
Epoch 5/10 546/546 [=======] - 126s 231ms/step - loss: 0.0510 - accuracy: 0.9802 - val_loss: 0.0499 - val_accuracy: 0.9829
说明:
- 从上面的输出来看,在训练的第一个 epoch 结束的时候,模型的 accuracy 就已经达到了 94%,作为对比,在上一篇文章中,完整从头训练的情况下,15个 epoch 才能达到 90% 的 accuracy。
- 这说明了使用 MobileNet 作为基础模型,可以有效地提高准确率,缩短训练时间。
由于使用了预训练的 MobileNet 模型作为基础,那么它的权重已经经过了充分的训练和调整,具有较强的特征提取能力,因此在猫狗图像分类任务中表现良好是可以预料的。而如果从零开始训练模型,则需要更多的样本和更长的训练时间才能达到类似的性能。
3.5 评估模型
# 评估模型在测试集上的性能
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(image_size, image_size),
batch_size=batch_size,
class_mode='categorical')
# 评估模型在测试集上的性能
loss, acc = model.evaluate(test_generator)
print(f'Test loss: {loss}, Test accuracy: {acc}')代码输出:
Found 3752 images belonging to 2 classes.
49/118 [=====>..................] - ETA: 2s - loss: 0.0645 - accuracy: 0.9758
118/118 [==============] - 5s 44ms/step - loss: 0.0590 - accuracy: 0.9784
Test loss: 0.05904101952910423, Test accuracy: 0.9784114956855774
说明:
- 从输出信息来看,无论是训练时的准确率、还是测试的准备率,都已经达到了97%以上,可以说是非常高的了。
3.6 模型保存
保存为 tf
# 保存模型参数
model.save('cat_dog_classfier_v2.tf', overwrite=True, include_optimizer=True)保存为 tflite 格式,以便在移动端上使用:
# 导出TensorFlow Lite模型
covertor = tf.lite.TFLiteConverter.from_keras_model(model)
covertor.optimizations = [tf.lite.Optimize.DEFAULT]
tflife_model = covertor.convert()
with open('cat_dog_classfier_v2.tflite', 'wb') as f:
f.write(tflife_model)导出的tflite文件 如下:
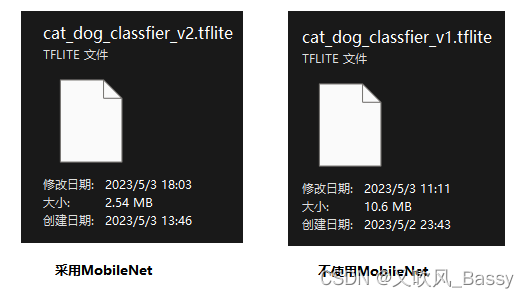
从 上图对比得出:使用 MobileNet 训练的 v2 模型,只有 2.54 MB,而不使用 MobileNet 的 v1 版本,有 10 MB 。
四、总结
本文介绍了采用 MobileNet 作为神经网络的基础架构来训练猫狗图像分类器的方法,该方法十分适合移动端。它不但减少了训练时间、提高了准确率,同时还减少了模型文件大小。
.