
论文链接:https://arxiv.org/pdf/2203.09642.pdf
代码链接:https://github.com/Kitware/COAT
1. 挑战

已有的工作面临着三个主要挑战:
- 在特征学习方面,人脸检测和ReID之间存在着冲突。人检测的目的是学习在人群中泛化的特征,以将人与背景区分开,而ReID的目的是学习在人群中不泛化但能将人彼此区分开来的特征。
- 显著的尺度或姿态变化增加了身份识别的难度。简单的特征融合策略可能会在特征嵌入中引入额外的背景噪声,导致ReID性能较差
- 背景目标或其他人的遮挡会使外观表现更加模糊。尽管基于anchor或者anchor-free来建模人整体外观的方法对行人的搜索精度有所提高,但复杂的遮挡容易导致搜索失败
2. 贡献
本文主要有以下两个贡献点:
1)作者提出了第一个基于级联Transformer的端到端行人搜索框架。渐进式设计有效地平衡了人的检测和ReID,而Transformer帮助注意比例和姿态/视角的变化。
2)在多尺度Transformer中,作者使用一种遮挡注意机制,在遮挡场景中生成具有鉴别性的细粒度人物表征,从而提高了性能。
3. 级联Transformers
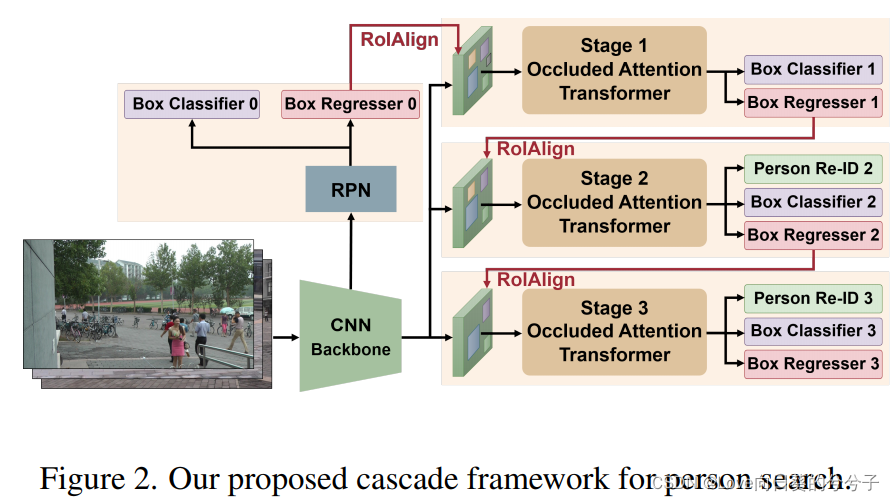
正如前面提到的,人的检测和人的ReID有着相互冲突的目标。因此,很难在骨干网络顶部共同学习这两个子任务的判别统一表示。与级联的R-CNN相似,作者在多尺度Transformer的 T T T阶段中将特征学习分解为顺序步骤。也就是说,Transformer中的每个头逐级细化预测对象的检测和ReID精度,即,可以逐步学习由粗到细的统一嵌入。然而,在被其他人、物体或背景遮挡的情况下,网络可能会遭受目标身份的噪声表示。为此,作者开发了多尺度Transformer中的遮挡注意机制,以学习遮挡鲁棒表示。如上图2所示,本文的网络是基于Faster R-CNN目标检测器主干与区域proposal网络(RPN)。然而,作者通过引入一个层叠的遮挡注意力transformers来扩展框架,该转换器以端到端方式进行训练。
3.1 Coarse-to-fine嵌入
从ResNet-50骨干中提取1024-dim stem特征映射后,作者使用RPN来生成区域proposals。对于每个proposals,应用RoI-Align操作将一个 h × w h \times w h×w区域作为基本的特征图 F \mathcal{F} F,其中 h h h和 w w w分别表示特征图的高度和宽度, c c c为通道数。
之后,作者采用多阶段级联结构学习嵌入的人检测和ReID。RPN的输出proposals在第一阶段用于对正实例和负实例进行重新采样。然后将第一阶段的box输出作为第二阶段的输入,以此类推。在每个阶段 t t t,将每个proposal的合并特征图发送给该阶段的卷积transformers。为了获得高质量的实例,级联结构逐步施加更严格的阶段约束。在实际应用中,逐步增加交叉并集(IoU)阈值 u t u_t ut。每个阶段的transformers后面有三个头,如NAE,包括一个人/背景分类器,一个box回归器和一个ReID鉴别器。注意,作者在第一阶段去掉了ReID鉴别器,以便在细化之前将网络集中于首先检测场景中的所有人。
3.2 遮挡Attention Transformer
这里将详细描述遮挡的注意Transformer,如图3所示。

1)Tokenization
给定基本特征图 F ∈ R h × w × c \mathcal{F} \in \mathbb{R}^{h \times w \times c} F∈Rh×w×c,对不同尺度下的Transformer输入进行token化。对于多尺度表示,作者首先将 F \mathcal{F} F通道分割为 n n n个切片,即 F ˉ ∈ R h × w × c ^ \mathcal{\bar{F}} \in \mathbb{R}^{h \times w \times \hat{c}} Fˉ∈Rh×w×c^,其中 c ^ = c n \hat{c} = \frac{c}{n} c^=nc来处理每个尺度的token。与ViT对大图像patch进行标记化不同,这里的transformer利用一系列卷积层来基于切片特征映射 F ˉ \mathcal{\bar{F}} Fˉ生成tokens。本文的方法受益于CNN的归纳偏差,并学习CNN的局部空间背景。不同的尺度由不同大小的卷积核实现。
通过一个卷积层将切片的特征映射 F ˉ ∈ R h × w × c ^ \mathcal{\bar{F}} \in \mathbb{R}^{h \times w \times \hat{c}} Fˉ∈Rh×w×c^转换为新的token映射 F ^ ∈ R h ^ × w ^ × c ^ \hat{F} \in \mathbb{R}^{\hat{h} \times \hat{w} \times \hat{c}} F^∈Rh^×w^×c^后,将其flatten为token输入 x ∈ R h ^ w ^ × c ^ x \in \mathbb{R}^{\hat{h}\hat{w} \times \hat{c}} x∈Rh^w^×c^。计算的token数为:
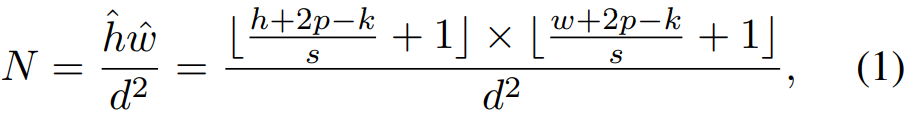
其中内核大小 k k k,步幅 s s s,卷积层的填充 p p p, d d d是每个token的patch大小.
2)Occluded attention
为了处理遮挡,作者在Transformer中引入了一种新的token级遮挡注意机制来模拟真实应用中的遮挡。具体来说,首先从一个mini-batch中的所有检测proposals中收集token,记为token bank X = { x 1 , x 2 , ⋅ ⋅ ⋅ , x P } \textbf{X} = \{\textbf{x}_1, \textbf{x}_2,···,\textbf{x}_P \} X={
x1,x2,⋅⋅⋅,xP},其中 P P P为该批次中每个阶段的检测proposal个数。由于RPN中的proposal包含了正反两方面的例子,token bank由前景行人部分和背景目标。我们在token bank之间tokens,所有实例都基于相同的交换指数集 M \mathcal{M} M。如上图3所示,交换的token对应于token映射中语义一致但随机选择的子区域。每个交换的token表示为:
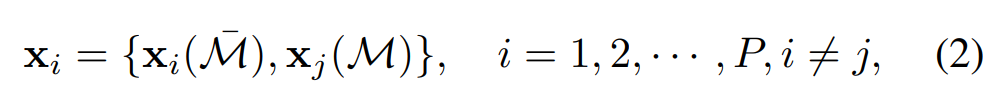
其中 x j \textbf{x}_j xj表示从token bank中随机选择的另一个样本。 M ˉ \mathcal{\bar{M}} Mˉ表示 M \mathcal{M} M的互补集,即 x i = x i ( M ˉ ) ⋃ x i ( M ) \textbf{x}_i = \textbf{x}_i(\mathcal{\bar{M})} \bigcup \textbf{x}_i(\mathcal{M}) xi=xi(Mˉ)⋃xi(M)。假设交换token bank X \textbf{X} X,计算它们之间的多尺度自注意,如上图3所示。就token的每个scale而言,作者运行transformers的两个子层(即,多头自注意(MSA)和一个前馈网络(FFN))。具体来说,通过三个独立的全连接(FC)层将混合tokens x \textbf{x} x转换为query矩阵 Q ∈ R h ^ w ^ × c ^ \textbf{Q} \in \mathbb{R}^{\hat{h} \hat{w} \times \hat{c}} Q∈Rh^w^×c^,key矩阵 K ∈ R h ^ w ^ × c ^ \textbf{K} \in \mathbb{R}^{\hat{h} \hat{w} \times \hat{c}} K∈Rh^w^×c^和value矩阵 V ∈ R h ^ w ^ × c ^ \textbf{V} \in \mathbb{R}^{\hat{h} \hat{w} \times \hat{c}} V∈Rh^w^×c^。可以进一步计算多头注意力和所有值的加权和为:
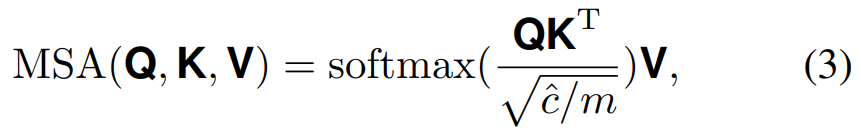
我们将query、key和value分割成 m m m个头,以获得更多的多样性,也就是说,从大小为 h ^ w ^ × c ^ \hat{h} \hat{w} \times \hat{c} h^w^×c^的张量到大小为 h ^ w ^ × c ^ m \hat{h} \hat{w} \times \frac{\hat{c}}{m} h^w^×mc^的 m m m个块。然后将独立注意输出串接并线性转换为期望维数。在MSA模块之后,FFN模块对每个token进行非线性转换,以增强其表示能力。然后将增强的特性映射成大小为 h ^ × w ^ × c ^ \hat{h} \times \hat{w} \times \hat{c} h^×w^×c^作为transformers的输出。
最后,作者将transformers的 n n n个尺度输出连接成原始的空间尺寸 h ^ × w ^ × c \hat{h} \times \hat{w} \times c h^×w^×c。注意,在每个Transformer外面有一个残差连接。经过GAP (global average pooling)层后,提取的特征被送入后续的头部进行box回归、人物/背景分类和人物再识别。
3)与concurrent works的相关性
不同领域有两种基于虚拟现实技术的并行工作,其中,Chen等人开发了一种多尺度变压器,包括两个独立的分支,带有small-patch和large-patch token。基于交叉注意token融合模块学习两尺度表示,其中每个分支的单个token被视为一个查询,以与其他分支交换信息。相反,本文作者利用一系列具有不同内核的卷积层来生成多尺度token。最后,作者连接增强的特征映射对应于transformer的特定切片的每个尺度。
为了处理person ReID中的遮挡和错位问题,He等人对人部分的patch embedding进行洗牌并重新组合,每一组包含多个随机的单个实例的patch embedding。与此相反,本文的方法首先在一个mini-batch中交换实例的partial tokens,然后基于混合token计算被遮挡的注意力。因此,最终的嵌入部分覆盖目标人,从不同的人或背景对象中提取特征,产生更强的遮挡鲁棒表示。
3.3 推理阶段
在推理阶段,作者通过删除上图3中的token mix-up步骤,将遮挡注意机制替换为Transformer中的经典自注意模块。在最后阶段输出具有相应嵌入的检测包围盒,并使用NMS操作去除冗余的包围盒。
4. 部分实验结果
主要在CUHK-SYSU库和PRW库这两个库上进行实验
4.1 SOTA方法性能对比
- 定量结果
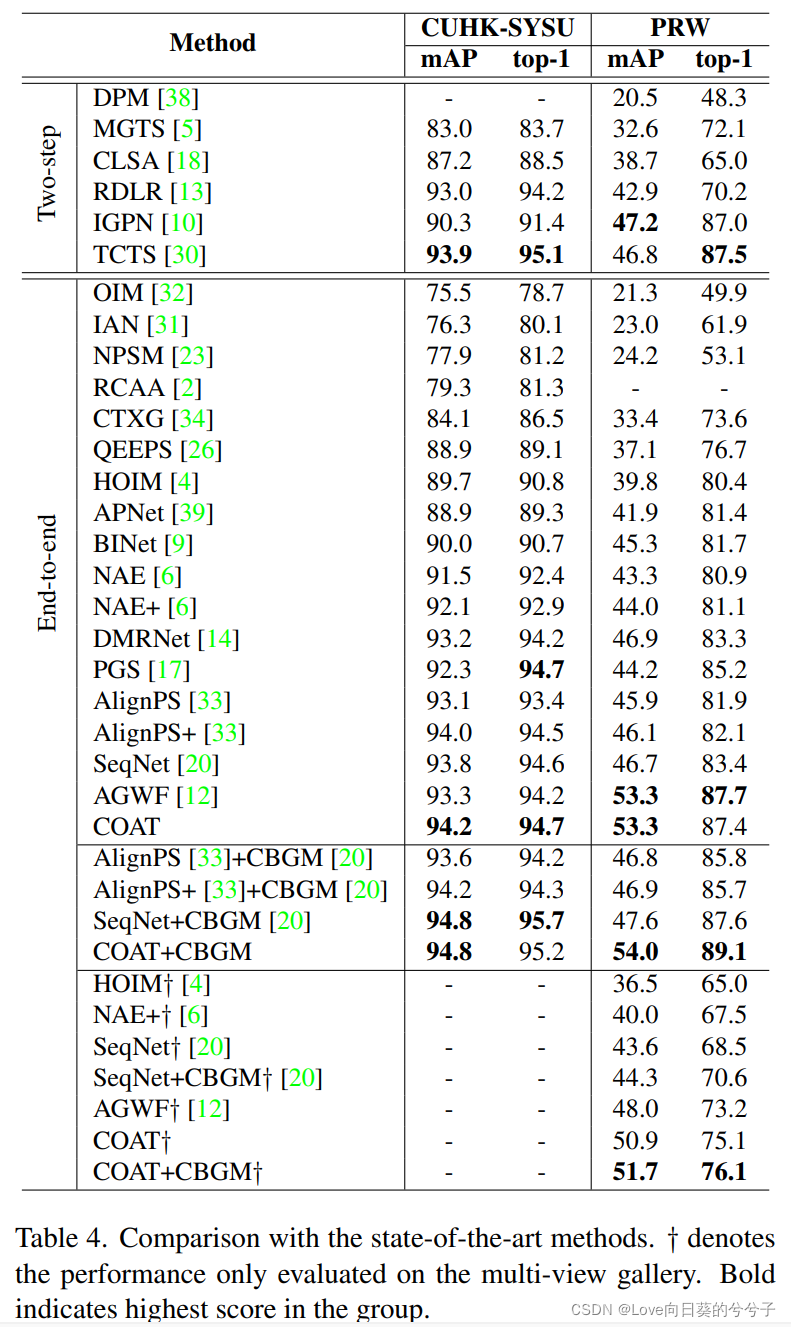
为了进行综合评估,如下图6所示,作者在增加图库大小时比较竞争方法的mAP分数。由于在gallery集合中考虑更多分散注意力的人具有挑战性,所有比较方法的性能都随着gallery大小的增加而降低。然而,本文的方法始终优于所有端到端方法和大多数两步方法。当库的大小大于1000时,本文的方法的性能略低于两步TCTS方法!!!
- 定性结果
如下图5所示,本文方法可以处理轻微/中度遮挡和规模/姿态变化的情况,而其他最先进的方法,如SeqNet和NAE在这些场景中失败

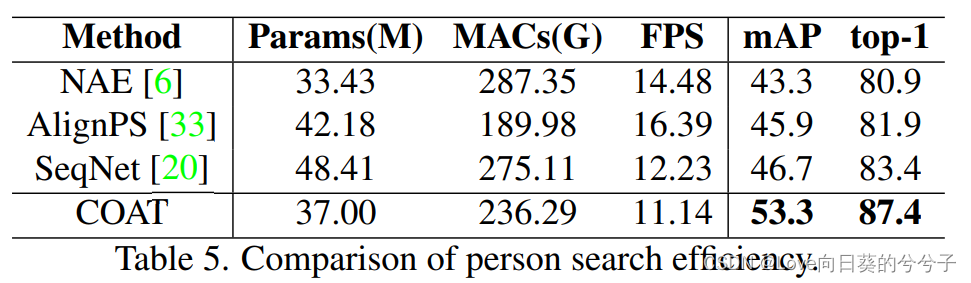
- Efficiency对比
从表5中,作者比较了参数数量、乘法累加操作(mac)和每秒帧的运行速度(FPS)。与其他比较方法相比,该方法计算复杂度较低,计算速度略慢,但mAP和准确率分别提高了+6.6%和+4.0%。COAT在Transformer中只使用了一个编码器层,并使用多尺度卷积来减少token化之前的信道数量,从而增加了COAT的效率.
4.2 消融实验
- 级联结构的贡献
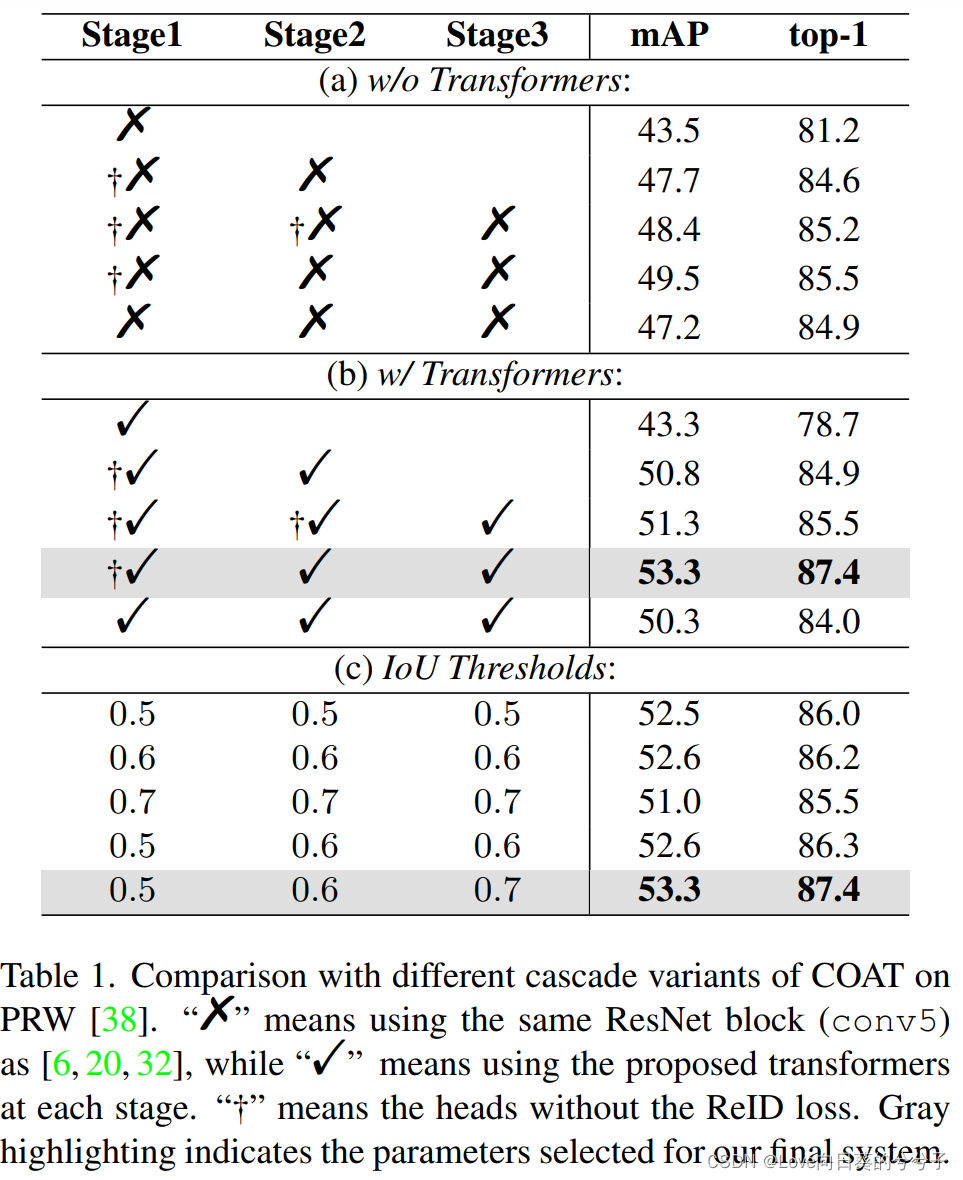
为了显示级联结构的贡献,作者根据级联阶段的数量和IoU阈值来评估粗到细约束。
1)首先,作者在每个阶段用ResNet块(conv5)替换遮挡注意Transformer。如下表1(a)所示,级联结构在增加更多阶段时显著提高了人搜索的精度,mAP从43.5%提高到49.5%,top-1精度从81.2%提高到85.5%。
2)当作者们引入所提出的遮挡注意Transformer时,其性能得到了进一步的改善(见下表1(b)),表明的遮挡注意Transformer的有效性。
3)此外,级联设计中不断增加的IoU阈值 u t u_t ut提高了搜索性能。如下表1©所示,每个阶段相同的IoU阈值比本文的方法产生的精度要低。例如,如果 u t = 0.5 u_t = 0.5 ut=0.5或 u t = 0.7 u_t = 0.7 ut=0.7,会引入更多的假阳性或假阴性。相比之下,本文的方法可以选择质量更高的检测proposal,从而获得更好的性能,即在第一阶段产生更多的候选检测,在第三阶段只产生高度重叠的检测。
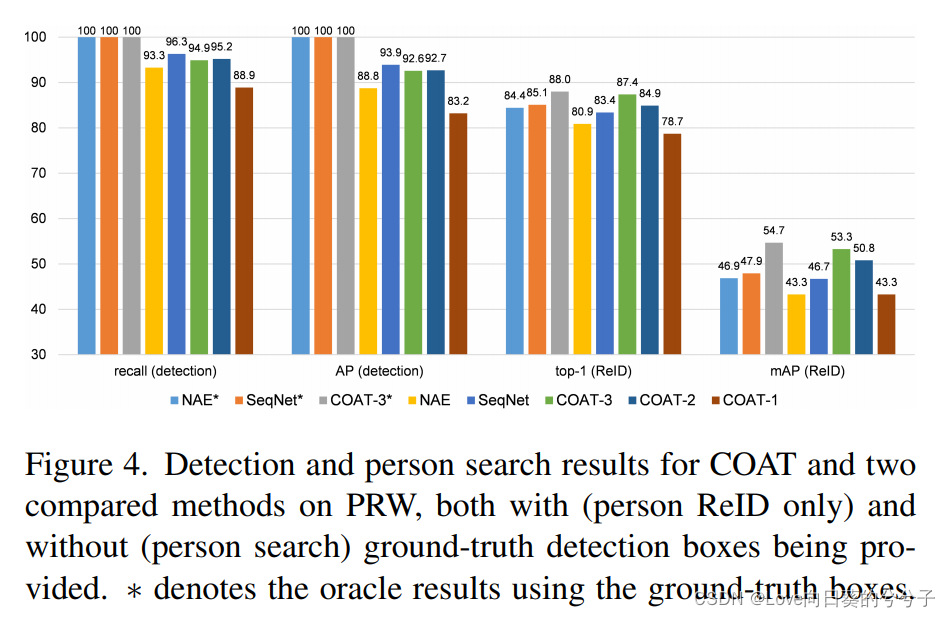
- 行人检测与ReID的关系
正如在前面所讨论的,行人检测和ReID之间存在冲突。在下图4中,作者探究了这两个子任务之间的关系。作者将COAT与最先进的NAE和SeqNet方法进行了比较,它们共享相同的Faster R-CNN检测器。作者还构造了三个具有不同阶段的COAT变量,即COAT-t,其中 t = 1 、 2 、 3 t = 1、2、3 t=1、2、3表示阶段数。当只看个人ReID而不是个人搜索时,即当给出ground-truth检测框时,COAT在top-1中有超过3%的增长,在mAP中有超过6%的增长,超过了两个竞争对手。同时,行人检测精度略低于SeqNet。这些结果表明,本文改进的ReID性能来自于从粗到细的人嵌入,而不是更精确的检测。
作者还观察到,从 t = 1 t = 1 t=1到 t = 2 t = 2 t=2,行人检测性能有所提高,但当 t = 3 t = 3 t=3时略有下降。作者推测这是因为,在权衡行人检测和ReID时,本文的方法更多地关注于对行人ReID进行区别性嵌入学习,而略微牺牲了检测性能。
此外,从上表1(a)(b)中可以看出,第一阶段带有ReID损失的COAT变量比本文的方法表现更差(mAP为50.3 vs 53.3)。同时,学习用于人检测和ReID的判别表示是非常困难的。因此,作者在COAT方法中去除阶段1的ReID鉴别器头(c.f.图2)。如果作者在第二阶段继续去除ReID鉴别器,mAP中ReID性能降低了2%。这表明,ReID嵌入确实受益于多阶段细化。
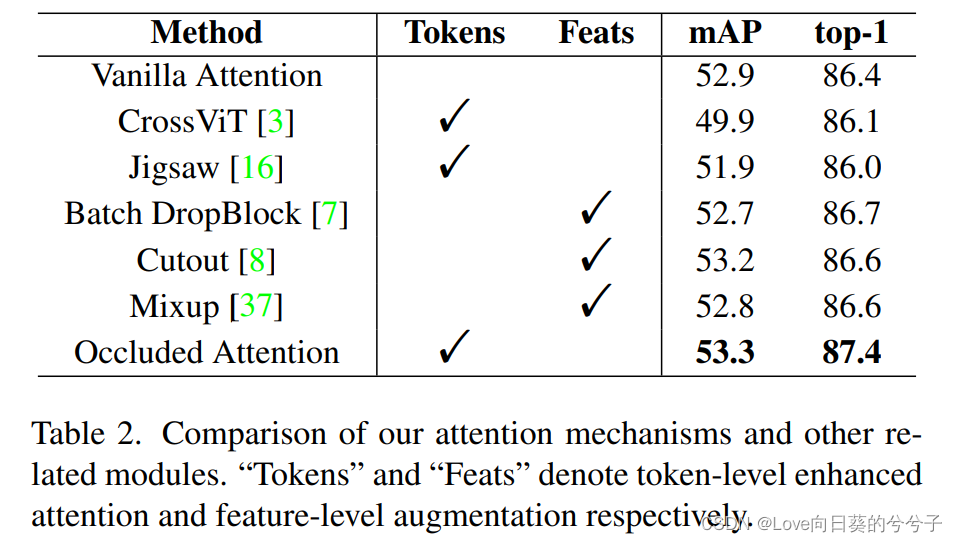
- 与其他注意机制进行比较以及与特征增强的比较
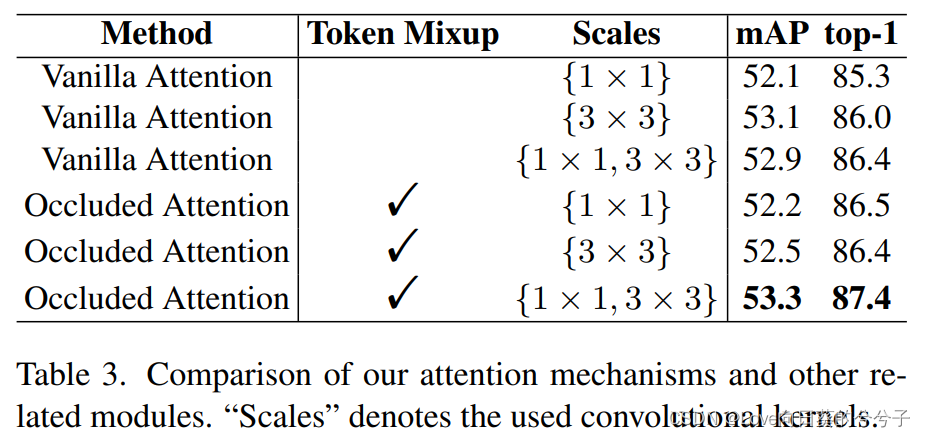
- 遮挡注意力机制的影响
5. 总结
- 本文设计了一种用于端到端行人搜索的级联遮挡注意Transformer(COAT)。COAT通过级联Transformer框架对行人检测和行人ReID都学习了从粗到细的判别表示。同时,遮挡注意机制综合模拟来自前景或背景物体的遮挡。
- 注意,论文中牵涉到的mix up数据增强策略,在图3展示的是先通过卷积进行token化后再进行的mix up!实际代码中,是先在图像级进行mix up,然后对mix up后的图像进行token化。