视频实例分割video instance segmentation,在vos的基础上,对每个实例打标签。
实例分割是目标检测+语义分割,在图像中将目标检测出来,然后对目标的每个像素分配类别标签,能够对前景语义类别相同的不同实例进行区分
数据集:Youtube-VIS
前身: Video instance segmentation
- 论文地址:VIS
- 代码地址:MaskTrackRCNN
VisTR:End-to-End Video Instance Segmentation with Transformers
- 论文地址:VisTR CVPR2021
- 代码地址:https://git.io/VisTR
- 参考链接:CVPR 2021 Oral: 基于Transformers的端到端视频实例分割方法VisTR
解决的问题
VIS不光要对单帧图像中的物体进行检测和分割,还要在多帧下找到每个物体的对应关系,即对其进行关联和跟踪。
- 视频本身是序列级的数据,将其建模为序列预测的任务,给定多帧的输入,输出多帧的分割掩码序列,需要一个能够并行处理多帧的模型
- 将分割和目标跟踪两个任务统一,分割是像素特征的相似度学习,目标跟踪是实例特征的相似度学习
将transformer应用于视频实例分割
- 本身用于序列到序列
- transformer擅长对长序列建模,可以用于建立长距离依赖,学习跨多帧的时间信息
- self-attention可以基于两两之间的相似度进行特征的学习和更新,可以更好的学习帧与帧的相关性
端到端,将视频的时间和空间特征看作一个整体,参考了DETR
介绍
任务:对每一帧进行实例分割,同时在连续的帧中建立实例的数据关联——追踪tracking
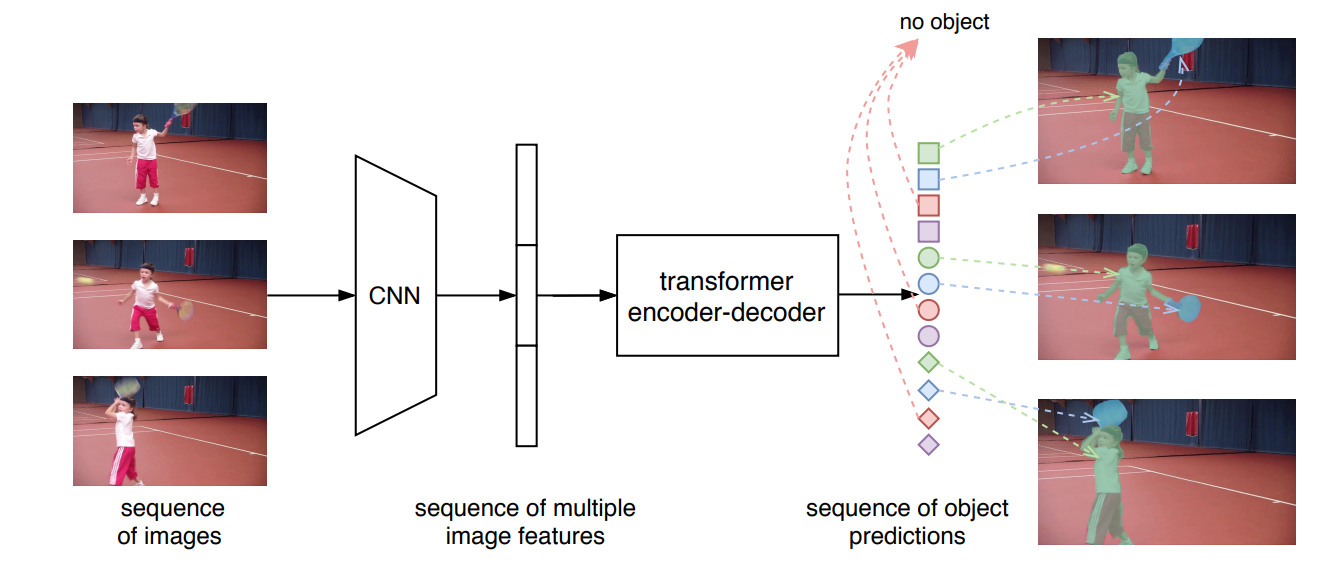
总结:它将VIS任务视为一个并行的序列解码/预测问题。给定一个由多个图像帧组成的视频片段作为输入,VisTR直接输出视频中每个实例的掩码序列。每个实例的输出序列在本文中被称为实例序列
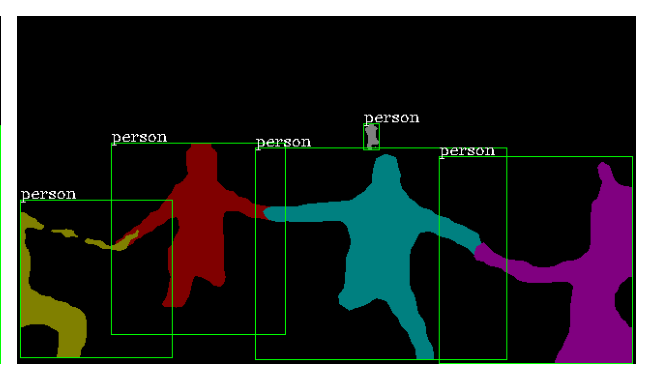
在下图中,用形状区分帧,用颜色区分实例,三帧,4个实例
-
第一阶段,给定一个视频帧序列,一个标准的CNN模块提取单个图像帧的特征,然后将多个图像特征按帧顺序串联起来,形成特征序列。
注:在提取特征的阶段网络的选择可以根据图片类型进行更改
-
第二阶段,transformer将片段级特征序列作为输入,并按顺序输出一串实例预测。预测序列遵循输入帧的顺序,而每帧的预测也遵循相同的实例顺序。
挑战:建模为一个序列预测问题
虽然在最开始的输入时,在时序维度多帧的输入和输出是有序的,但是对于单帧而言,实例的序列在初始状态下是无序的,无法实现实例的跟踪关联,因此要强制使得每帧图像输出的实例的顺序一致,这样只要找到对应位置的输出,便可以自然的实现同一实例的关联。
如何保持输出的顺序
实例序列匹配策略:对同一个实力位置处的特征进行序列维度
在输出的与真实的序列之间进行二方图匹配,并将序列作为一个整体进行监督
如何从transformer网络中获取每个实例的掩码序列
实例序列分割模块:自注意力获取每个实例在多帧中的掩码特征,并利用三维卷积对每个实例的掩码序列进行分割
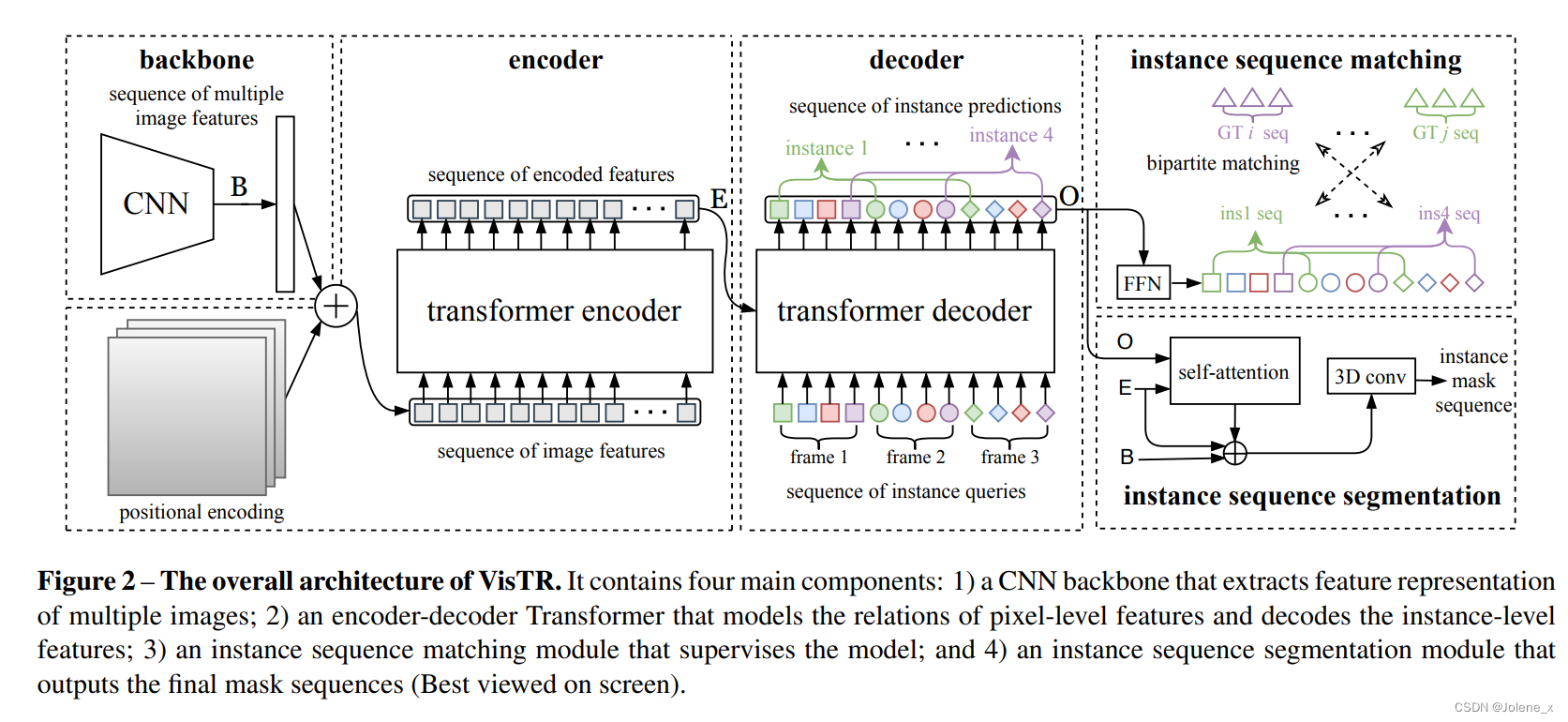
VisTR整体架构
一个CNN主干来提取多帧特征表示(此处可以根据不同的场景需求采用不同的特征提取网络)
一个编码器-解码器transformer来模拟像素级和实例级特征的相似性
一个实例序列匹配模块
一个实例序列分割模块
backbone
初始输入:T帧 * 通道数3 * H’ * W’
输出特征矩阵(将每帧concat):T * C * H * W
transformer 编码器
学习点和点之间的相似度,输出的是密集的像素特征序列
先将backbone提取到的特征用1*1卷积降维操作:T * C * H * W => T * d * H * W
展平:transformer的输入需要是二维的,所以对空间(H, W)和时间(T)进行flatten,T * d * H * W => d * (T * H * W)
展平的理解:d类似于通道,而T * H * W就是此序列所有T帧的所有像素点
时间和空间的位置编码
Temporal and spatial positional encoding.
最终的位置编码的维度是d
Transformer的结果是与输入的序列无关的,而实例分割任务需要精确的位置信息,所以用固定的位置编码信息来补充特征,这些信息包含片段中的三维(时间、空间——H, W)位置信息,与backbone提取到的特征信息一起送入编码器
在原始的transformer中,位置信息是一维的,所以 i i i是从1到d维,所以 2 k 2k 2k从0到d, w k w_k wk从1逐渐到无限接近于0
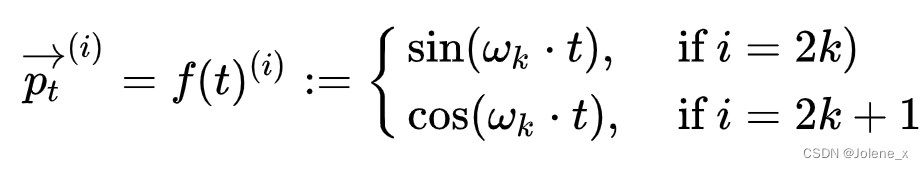
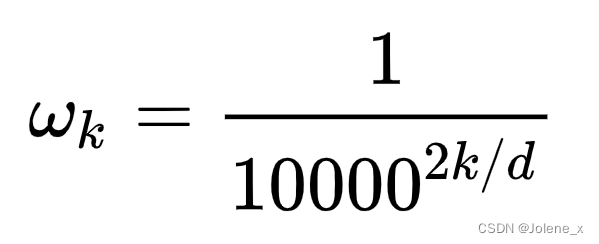
那么最终t位置的向量也是d维的:
p t = [ s i n ( w 1 . t ) c o s ( w 1 . t ) s i n ( w 2 . t ) c o s ( w 2 . t ) s i n ( w d / 2 . t ) c o s ( w d / 2 . t ) ] d p_t = \left[ \begin{matrix} sin(w_1 .t)\\ cos(w_1 .t)\\ sin(w_2 .t)\\ cos(w_2 .t)\\ \\ \\ sin(w_{d/2}.t)\\ cos(w_{d/2}.t)\\ \end{matrix} \right] _d pt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(w1.t)cos(w1.t)sin(w2.t)cos(w2.t)sin(wd/2.t)cos(wd/2.t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d
而本文中,需要考虑的是三个维度的位置,H, W , T,也就是说对于一个像素点,他的坐标有三个值,所以对于三个维度,独立的生成 d / 3 d/3 d/3维的位置向量
对于每个维度的坐标,独立使用正弦和余弦函数,生成 d / 3 d/3 d/3维度的向量
p o s pos pos代表坐标( h , w , t h, w, t h,w,t), i i i代表维度,假设只看 h h h,则 i i i从1到 d / 3 d/3 d/3维,同时为了保证 w k w_k wk的取值在0到1之间,所以此处的 w k w_k wk与原始的transformer不一样。
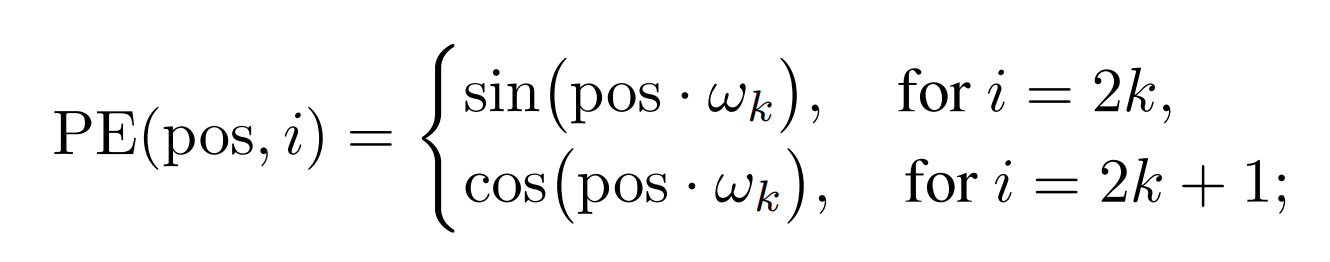
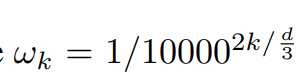
最终在H维度的位置向量表示如下
P E ( p o s ) H = [ s i n ( w 1 . t ) c o s ( w 1 . t ) s i n ( w 2 . t ) c o s ( w 2 . t ) s i n ( w d / 6 . t ) c o s ( w d / 6 . t ) ] d / 3 PE(pos)_H = \left[ \begin{matrix} sin(w_1 .t)\\ cos(w_1 .t)\\ sin(w_2 .t)\\ cos(w_2 .t)\\ \\ \\ sin(w_{d/6}.t)\\ cos(w_{d/6}.t)\\ \end{matrix} \right] _{d/3} PE(pos)H=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(w1.t)cos(w1.t)sin(w2.t)cos(w2.t)sin(wd/6.t)cos(wd/6.t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d/3
然后将位置编码(d * H * W * T)与backbone提取到的特征一起输入到编码器中
transformer解码器
将encoder输出的密集像素特征序列解码为稀疏的实例特征序列
待看:受DETR的启发,假设每一帧有n个实例,则预设每一帧有固定n个input embedding用于提取实例的特征,命名为instance query,那么T帧的实例查询有N = n * T。是可学习的,与像素特征有相同的维度
instance query:用于和密集的输入特征序列进行attention运算,选取能够代表每个实例的特征
输入:E + 实例查询(instance query)
输出:每个实例的预测序列O,后续过程将单个实例的所有帧的预测序列看成一个整体,按照原始视频帧序列的顺序输出,为n * T个实例向量
实例序列匹配
decoder的输出是n * T个预测序列,按照帧的顺序,但每一帧中的n个实例顺序不确定
此模块的功能是使得不同帧中,对于同一个实例的预测,保持相对位置不变
将每个实例的预测序列和标注数据中每个实例的GT序列进行二分匹配,利用匈牙利匹配的方式找到每个预测最近的标注数据
补充FFN:其实也就是MLP多层感知机,就是FC+GeLU+FC
在 Transformer中,MSA 后跟一个 FFN (Feed-forward network),其包含 两个 FC 层,第一个 FC 将特征从维度 D变换成4D,第二个 FC 将特征从维度4D恢复成D,中间的非线性激活函数均采用 GeLU (Gaussian Error Linear Unit,高斯误差线性单元) —— 这实质是一个 MLP (多层感知机与线性模型类似,区别在于 MLP 相对于 FC 层数增加且引入了非线性激活函数,例如 FC + GeLU + FC)
主要是保持不同图像中同一实例的预测的相对位置
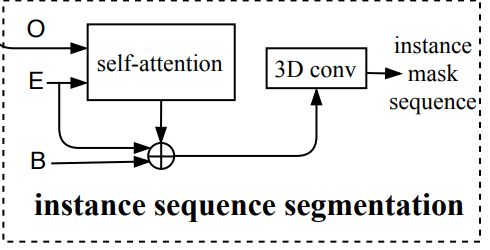
实例序列分割
任务:计算每一个实例在对应帧中的掩码
O是decoder的输出,E是encoder的输出,B是CNN提取到的特征
实例分割的本质是像素相似度的学习,对于每一帧,先将预测图O与编码特征E送入self-attention,计算相似度,将结果作为该实例该帧的初始mask,然后与该帧的初始backbone特征和编码特征E融合,得到该帧该实例的最终掩码特征。为了更好的利用时序信息,将该实例的多帧mask concat生成mask序列,送入3D卷积模块进行分割
这种方式通过利用多帧同一实例的特征对单帧的分割进行加强,发挥时序的优势
原因:当物体处于challenge状态下,比如运动模糊、遮盖等情况,可以通过学习来自其他帧的信息,来帮助分割,也就是,来自多个帧的同一实例的特征可以帮助网络更好的识别该实例
假设第t帧的实例i的掩码特征g(i, t):1 * a * H’/4 * W’/4,其中a为通道号,将T帧的特征串联,得到该实例在所有帧中的掩码1 * a * T * H’/4 * W’/4
此处4是因为例子里是4个实例
消融实验
视频序列的长度
18到36,效果变好,更多的时间信息有助于提升结果
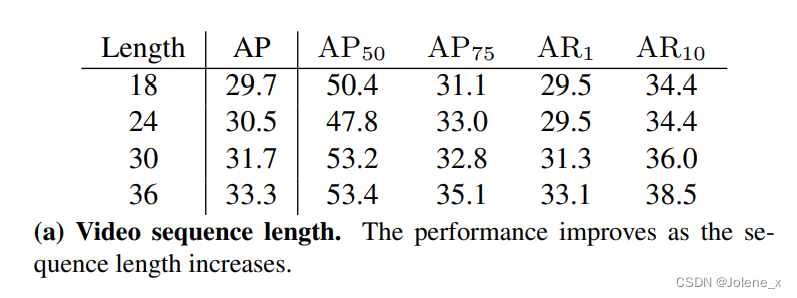
视频序列的顺序

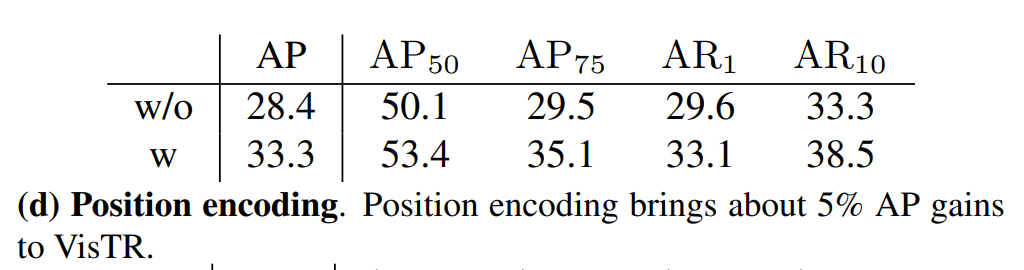
位置编码
视频序列中的相对位置
第一行没有位置编码取得的效果是:序列监督的有序格式和transformer输入输出顺序之间的对应关系隐含了部分的相对位置信息
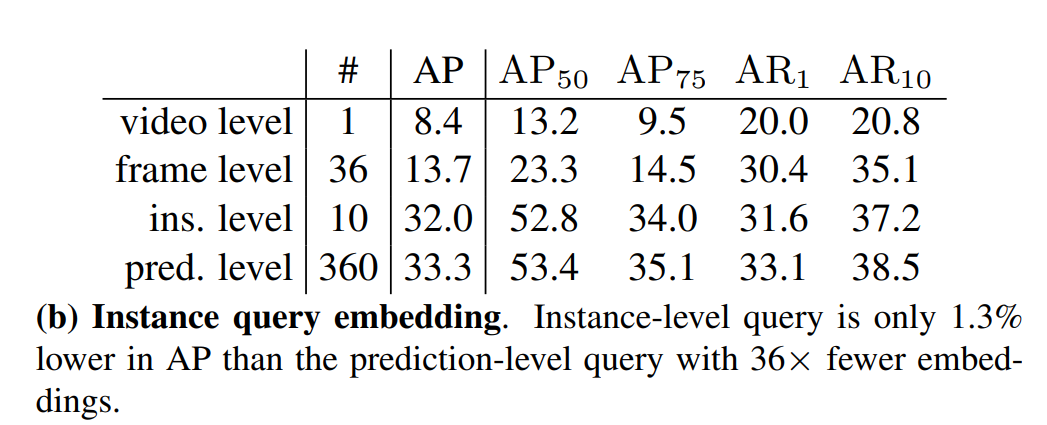
可学习的实例查询嵌入
默认prediction. level:一个嵌入负责一个预测,共n * T
video level:只有一个嵌入,被重复利用n * T次
frame level:对于每帧,使用一个嵌入,也就是T个嵌入,对于每个嵌入,重复n次
instance level:对于每个实例,使用一个嵌入,也就是n个嵌入,重复T次
一个实例的查询可以共享,可以用来改善速度
实验结果
数据集:YouTube-VIS
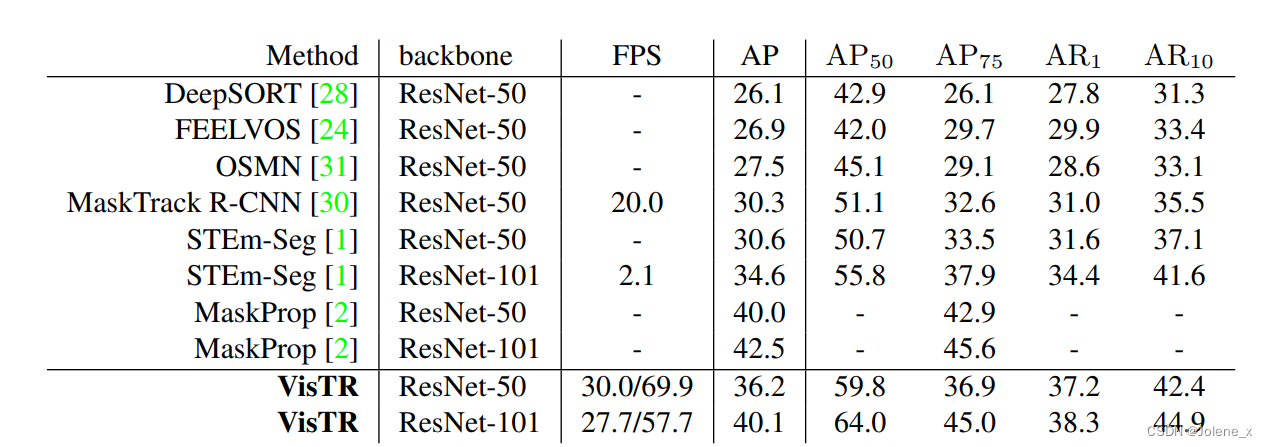
速度快归功于:并行解码
可视化结果:(a)实例重叠,(b)实例之间相对位置的变化,©同一类别的实例靠近时产生的混淆,(d)各种姿势的实例。
