1、环境

2、文档
3、数据集
4、模型
在github上面下载
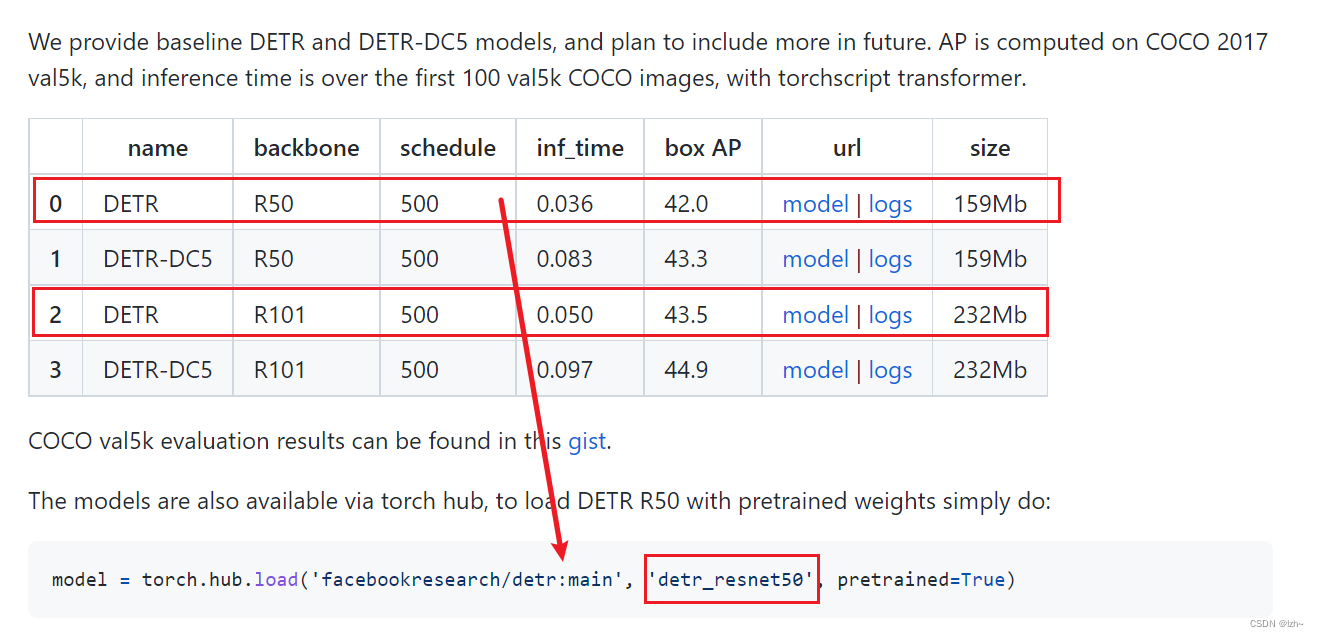
链接:https://pan.baidu.com/s/1fmOYAOZ4yYx_rYquOS6Ycw
提取码:74l5
5、权重文件
生成自己所需要的权重文件
import torch
# 修改路径 预训练模型
pretrained_weights=torch.load('detr-r50.pth')
# 修改自己的类别
num_classes=3
pretrained_weights["model"]["class_embed.weight"].resize_(num_classes+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_classes+1)
torch.save(pretrained_weights,"detr_r50_%d.pth"%num_classes)
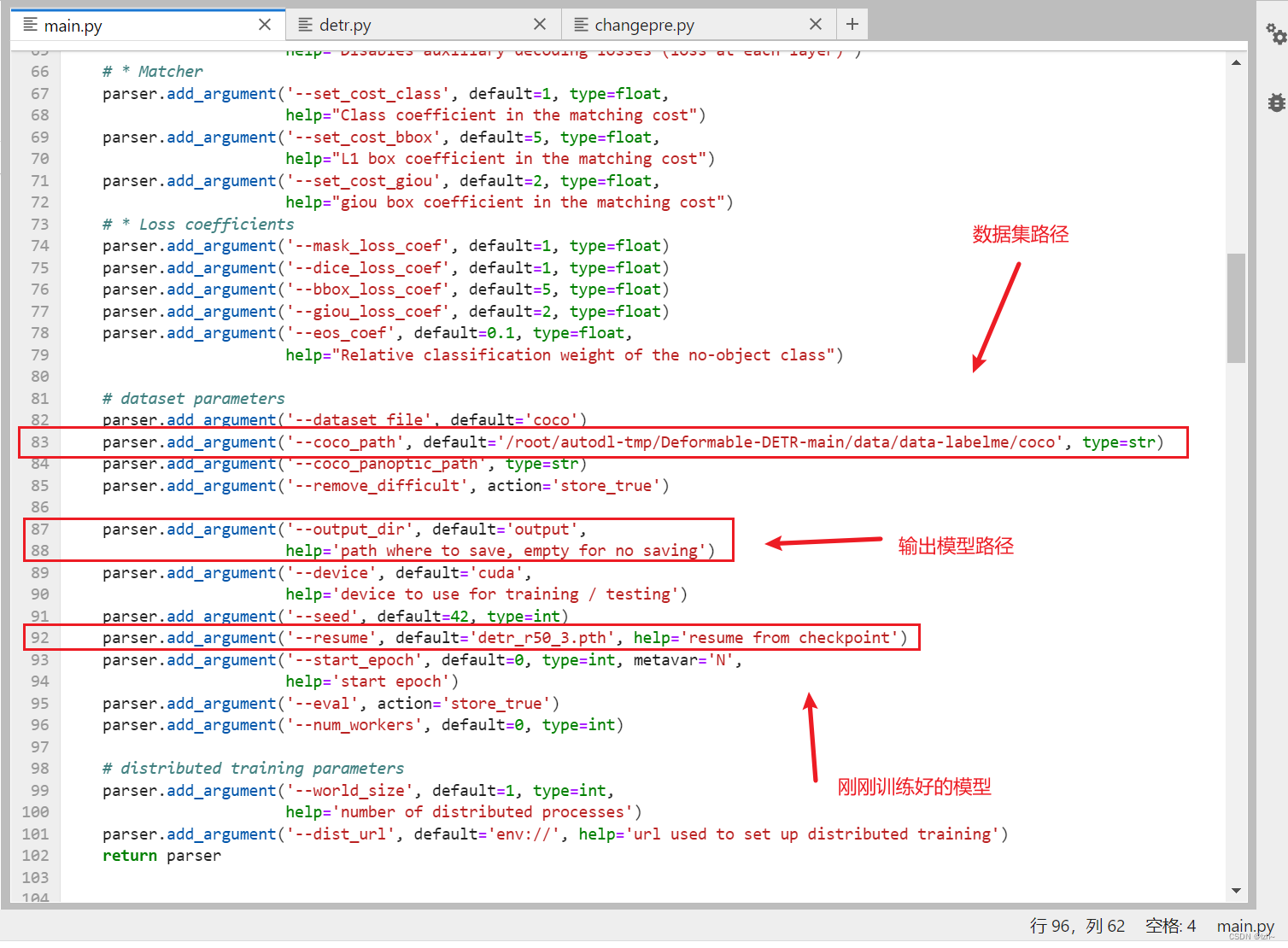
6、修改代码
main.py相应位置根据下图更改
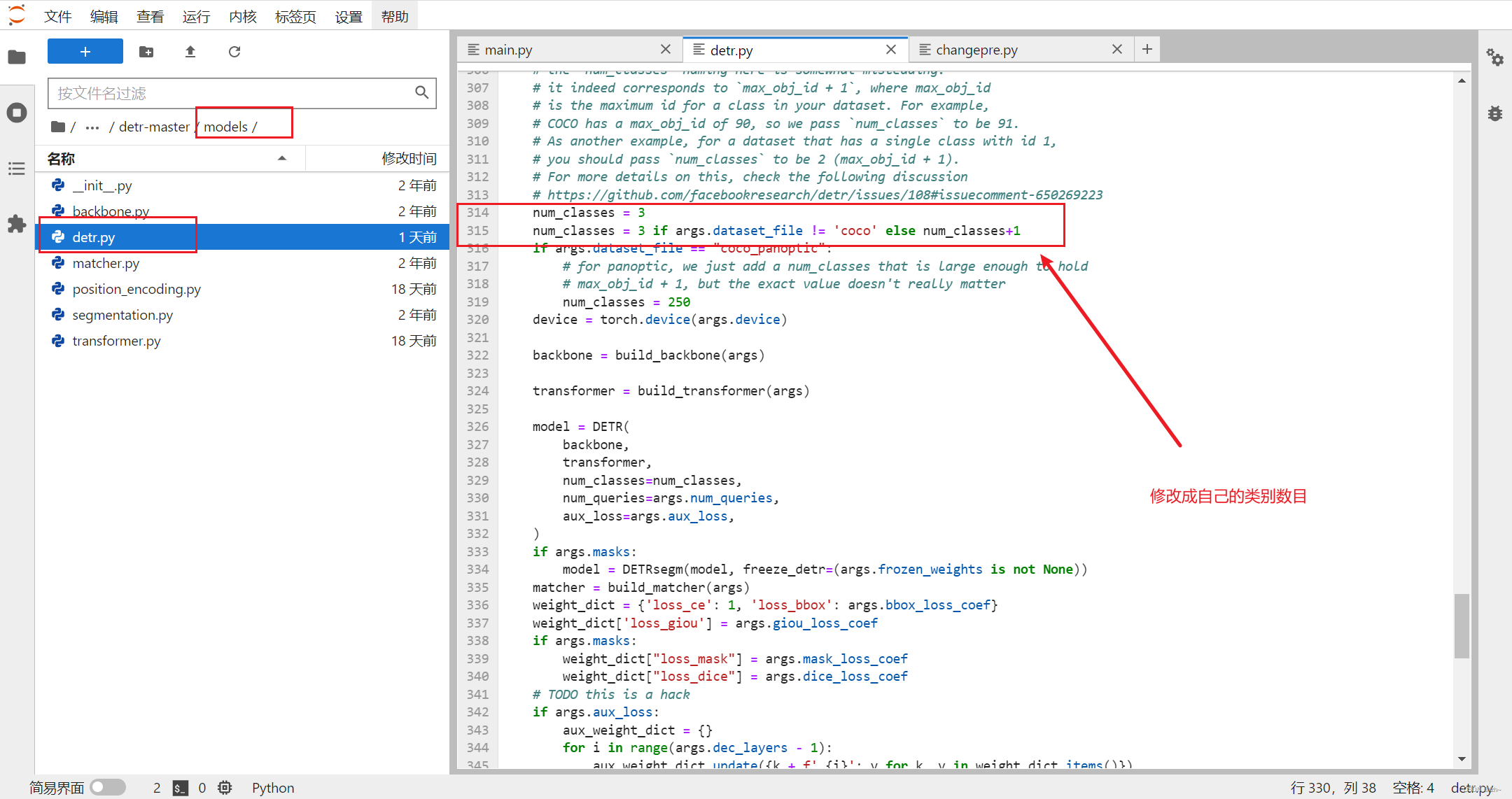
model目录下面的detr.py文件相应位置更改类别 num_classes
7、训练模型
python main.py
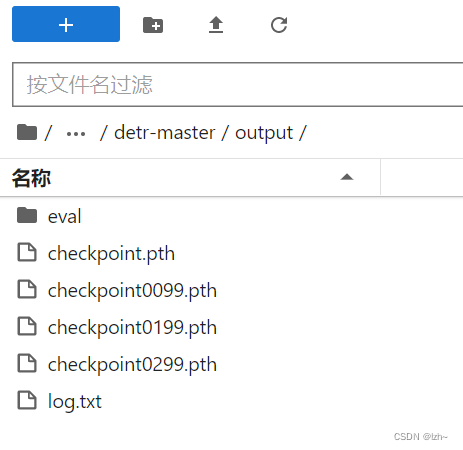
8、测试模型
import argparse
import random
import time
from pathlib import Path
import numpy as np
import torch
from models import build_model
from PIL import Image
import os
import torchvision
from torchvision.ops.boxes import batched_nms
import cv2
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=2, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float,
help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None,
help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
# 如果设置为resnet101,后面的权重文件路径也需要修改一下
parser.add_argument('--backbone', default='resnet50', type=str,
help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true',
help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int,
help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int,
help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int,
help="Number of query slots")
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true',
help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', default='False',
help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float,
help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float,
help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float,
help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float,
help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', type=str, default="coco")
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
# 修改检测的图像路径
parser.add_argument('--source_dir', default='/root/autodl-tmp/Deformable-DETR-main/data/data-labelme/test',
help='path where to save, empty for no saving')
# 修改检测结果保存路径
parser.add_argument('--output_dir', default='result/',
help='path where to save, empty for no saving')
parser.add_argument('--device', default='cpu',
help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
# 修改resnet50对应的权重文件
parser.add_argument('--resume', default='output/checkpoint0299.pth',
help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', default="True")
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
def filter_boxes(scores, boxes, confidence=0.7, apply_nms=True, iou=0.5):
keep = scores.max(-1).values > confidence
scores, boxes = scores[keep], boxes[keep]
if apply_nms:
top_scores, labels = scores.max(-1)
keep = batched_nms(boxes, top_scores, labels, iou)
scores, boxes = scores[keep], boxes[keep]
return scores, boxes
# COCO classes
CLASSES = ['green','puple','yellow']
def plot_one_box(x, img, color=None, label=None, line_thickness=1):
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def main(args):
print(args)
device = torch.device(args.device)
model, criterion, postprocessors = build_model(args)
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'],False)
model.to(device)
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("parameters:", n_parameters)
image_Totensor = torchvision.transforms.ToTensor()
image_file_path = os.listdir(args.source_dir)
for image_item in image_file_path:
print("inference_image:", image_item)
image_path = os.path.join(args.source_dir, image_item)
image = Image.open(image_path)
image_tensor = image_Totensor(image)
image_tensor = torch.reshape(image_tensor,
[-1, image_tensor.shape[0], image_tensor.shape[1], image_tensor.shape[2]])
image_tensor = image_tensor.to(device)
time1 = time.time()
inference_result = model(image_tensor)
time2 = time.time()
print("inference_time:", time2 - time1)
probas = inference_result['pred_logits'].softmax(-1)[0, :, :-1].cpu()
bboxes_scaled = rescale_bboxes(inference_result['pred_boxes'][0,].cpu(),
(image_tensor.shape[3], image_tensor.shape[2]))
scores, boxes = filter_boxes(probas, bboxes_scaled)
scores = scores.data.numpy()
boxes = boxes.data.numpy()
for i in range(boxes.shape[0]):
class_id = scores[i].argmax()
label = CLASSES[class_id]
confidence = scores[i].max()
text = f"{
label} {
confidence:.3f}"
print(text)
image = np.array(image)
plot_one_box(boxes[i], image, label=text)
# cv2.imshow("images", cv2.cvtColor(image,cv2.COLOR_BGR2RGB))
# cv2.waitKey()
image = Image.fromarray(image)
image.save(os.path.join(args.output_dir, image_item))
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
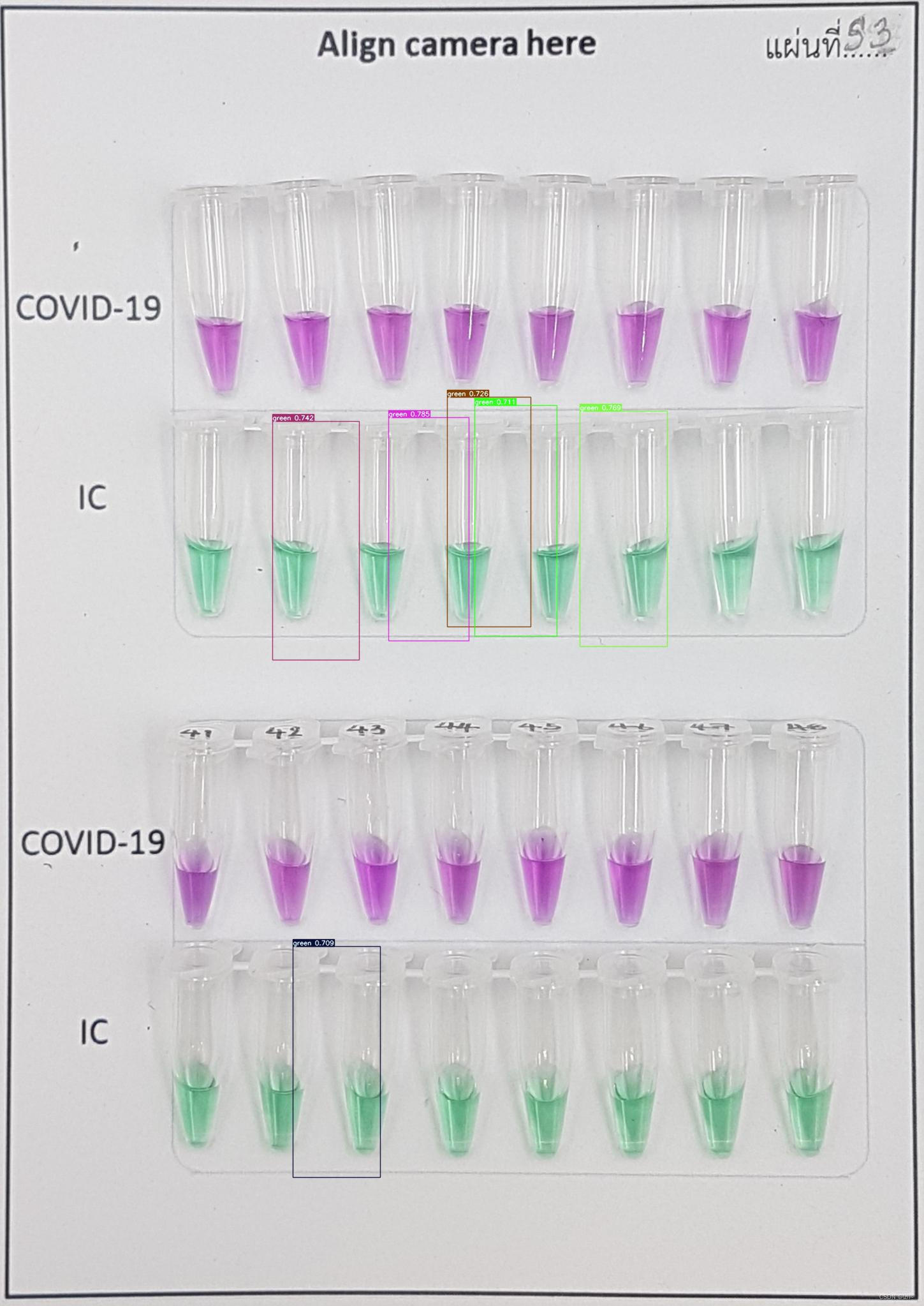
9、结果
detr的测试对于小物体的检测不是很好,相比来说deformable detr的效果更好
扫描二维码关注公众号,回复:
14595400 查看本文章