DETR
链接:https://github.com/facebookresearch/detr
论文地址:https://arxiv.org/pdf/2005.12872.pdf,
CNN生成的特征图将被送入Transformer,然后经过一系列的自注意力层和前馈神经网络层,最终得到一组对象的表示。每个对象的表示由一个类别分数和四个坐标值组成。这些类别分数和坐标值是预测得出的,它们表示对象在图像中的位置和类别信息。
解码器将这些对象解码为一组检测结果。在解码过程中,匹配函数将预测类别和预测坐标与这些对象进行匹配,从而找到与预测类别和预测坐标最匹配的对象,并将其作为最终的检测结果输出。
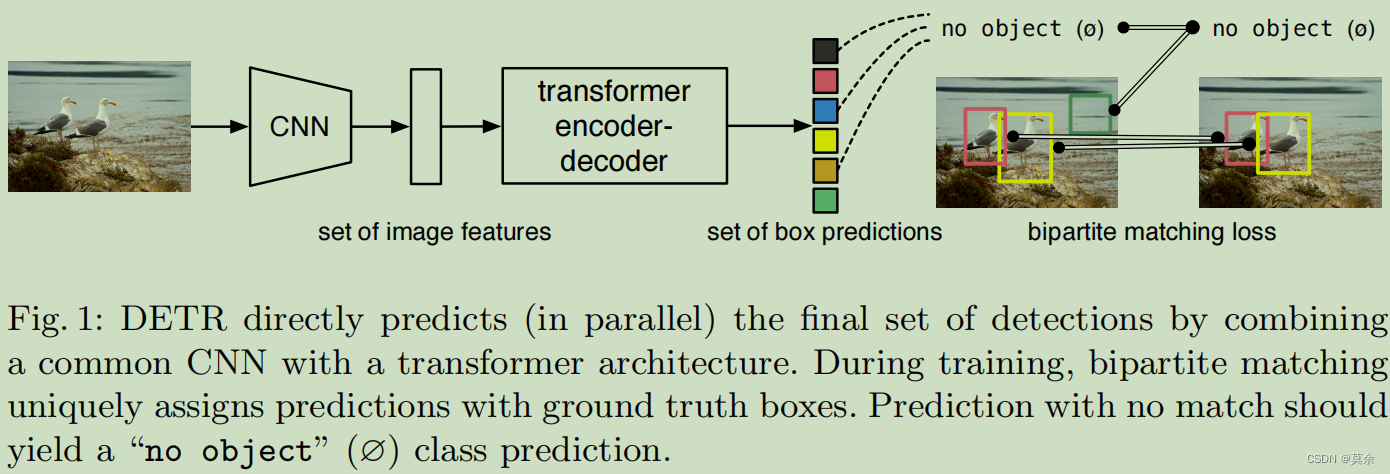
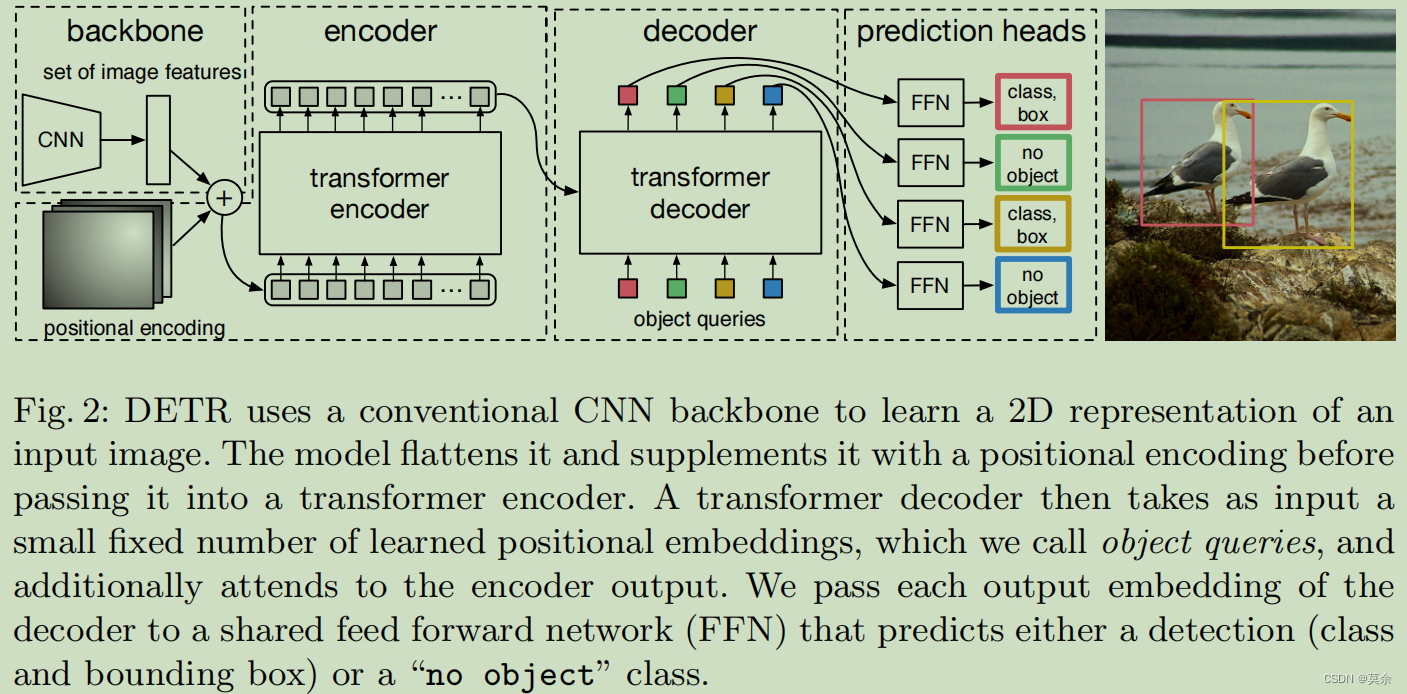
1. 亮点工作
1.1 E to E
DETR是第一个使用Transformer实现端到端目标检测的方法。这种方法不需要预定义的候选框或先验知识,并且可以同时执行分类和定位任务。
1.2 self-attention
DETR使用自注意力机制替代传统的卷积神经网络结构。自注意力机制能够有效地捕获全局上下文信息,从而在目标检测任务中获得更好的性能。
1.3 引入位置嵌入向量
DETR引入了一组位置嵌入向量来帮助解码器在生成目标检测结果时理解对象之间的相对位置关系
1.4 消除了候选框生成阶段
传统目标检测方法需要先生成一组候选框,然后对这些候选框进行分类和定位。DETR通过消除这个阶段,可以更好地利用计算资源和提高检测效率。
2. Set Prediction
实现了对 一组对象 的分类。
2.1 N个对象
在解码器中,每个位置都生成了一组对象,这些对象由类别分数和坐标表示。N就是指每个位置生成的对象的数量。一般情况下,N的值越大,DETR的检测性能就越好,但同时会带来更高的计算成本和内存占用。因此,需要在性能和效率之间进行权衡,并选择合适的N值。
在实际应用中,根据具体的任务和资源限制,N的值可能需要进行调整。
2.2 Hungarian algorithm
一种用于解决二分图匹配问题的经典算法,它的时间复杂度为O(n2),其中n为顶点数。
在DETR中,每个预测结果都需要与所有的实际目标进行匹配,因此可以将预测结果看作左边的顶点,实际目标看作右边的顶点,然后通过匈牙利算法计算出每个左边的顶点最匹配的右边的顶点是谁。这样可以快速地得到每个预测结果对应的实际目标,从而得到最终的检测结果。
解码器生成的一组对象 对比于 预测类别和预测坐标
在解码过程中,DETR模型会将编码器得到的一组对象表示解码为一组检测结果,其中每个对象的表示由一个类别分数和四个坐标值组成。这些类别分数和坐标值就是预测的类别和坐标。
3. 实例剖析
假设我们有一个图像,其中包含三个对象:一个狗、一个猫和一个椅子。
狗:坐标=(5, 15, 55, 65)
猫:坐标=(35, 45, 75, 85)
椅子:坐标=(95, 95, 145, 145)
设置N=3,DETR得到一组检测结果,如下所示:
对象1:类别分数=0.9,坐标=(10, 20, 50, 60)
对象2:类别分数=0.8,坐标=(30, 40, 70, 80)
对象3:类别分数=0.7,坐标=(100, 100, 150, 150)
首先,计算IoU,(145-100)×(145-100)=2025,它们之间的并集面积为(50×50)+(50×50)-2025 = 2975。
IoU得分:2025/2975 = 0.6
总得分:0.7*0.6 = 0.42 < 0.5
输出1:狗,类别分数=0.9,坐标=(10, 20, 50, 60)
输出2:猫,类别分数=0.8,坐标=(30, 40, 70, 80)
输出3:椅子,类别分数=0.0,坐标=(0, 0, 0, 0)
由于第三个输出与任何一个真实对象都没有匹配,因此其类别分数和坐标值都被设为0。
4. 代码
4.1 配置文件
d2/configs/detr_256_6_6_torchvision.yaml
d2/detr/config.py
4.1.1 数据集的类别数
需要根据自己的数据集修改模型的分类器的输出维度,使其等于数据集中的类别数。
cfg.MODEL.DETR.NUM_CLASSES = 80
4.1.2 训练集和验证集的路径
需要在训练和验证代码中设置自己数据集的路径。
DATASETS:
TRAIN: ("coco_2017_train",)
TEST: ("coco_2017_val",)
4.1.3 图片的大小
需要根据自己的数据集图片的大小修改模型的输入大小。
INPUT:
MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
CROP:
ENABLED: True
TYPE: "absolute_range"
SIZE: (384, 600)
FORMAT: "RGB"
4.1.4 训练时的批量大小、学习率等参数
需要根据自己的数据集和硬件环境进行调整。
SOLVER:
IMS_PER_BATCH: 64
BASE_LR: 0.0001
4.2 模型部分
4.2.1 backbone
DETR的backbone是Dilated ResNet,它是一种轻量级的卷积神经网络。
4.2.2 neck
DETR使用了Transformer的Encoder作为其neck部分的主要组成部分。
具体来说,DETR包含一个Encoder和一个Decoder,其中Encoder使用Transformer对输入的图像特征进行编码,将其转换为一组上下文向量,而Decoder使用Transformer对这些上下文向量和预测的对象查询向量进行解码,生成最终的目标预测结果。
4.2.3 head
主要包含Transformer Decoder、Query Embedding。
DETR中的全局嵌入(Query Embedding)是在Transformer Decoder的输出之上计算的。具体地,Transformer Decoder的输出通过多头自注意力(Multi-Head Self-Attention)进行加权求和,得到一个新的表示,即为每个对象提取了不同的上下文信息。
接着,这个表示会被传递到Feed-Forward Network(FFN)中进行进一步的处理,以产生更丰富的特征表示。
最后,Query Embedding是在FFN的输出上计算得到的,它是一个用于匹配对象嵌入向量。因此,可以说,在DETR中,FFN和Query Embedding是在Transformer Decoder之上进行的。
假设我们有一个包含4个对象的图像,并使用DETR模型对其进行目标检测。在DETR模型的输入端,我们有图像张量 X X X,其尺寸为 C × H × W C\times H\times W C×H×W,其中 C C C 是通道数, H H H 和 W W W 是高度和宽度。
首先,我们使用DETR的backbone网络(Diamante)将图像张量 X X X 转换为特征张量 F backbone F_{\text{backbone}} Fbackbone。这个特征张量的大小是 C backbone × H backbone × W backbone C_{\text{backbone}}\times H_{\text{backbone}}\times W_{\text{backbone}} Cbackbone×Hbackbone×Wbackbone。
接下来,我们将特征张量 F backbone F_{\text{backbone}} Fbackbone 送入Transformer Decoder网络,得到Transformer Decoder的输出 F decoder F_{\text{decoder}} Fdecoder。这个输出张量的大小也是 C decoder × H decoder × W decoder C_{\text{decoder}}\times H_{\text{decoder}}\times W_{\text{decoder}} Cdecoder×Hdecoder×Wdecoder。
然后,我们对 F decoder F_{\text{decoder}} Fdecoder 进行FFN,得到FFN的输出张量 F ffn F_{\text{ffn}} Fffn。这个张量的大小和 F decoder F_{\text{decoder}} Fdecoder 相同。
最后,我们使用Query Embedding将 F ffn F_{\text{ffn}} Fffn 映射到特定的目标类别,得到每个对象的预测框坐标和类别。
4.3 train/engine.py
4.3.1 train.py
DETR的main.py文件是训练和测试DETR模型的主要脚本。在该脚本中,首先通过命令行参数解析器解析各种配置和超参数,然后通过build_model()函数构建DETR模型和优化器,通过build_lr_scheduler()函数构建学习率调度器,最后通过DefaultTrainer()类进行训练或测试。
4.3.2 engine.py
定义了一些训练和测试的辅助函数,包括计算loss、前向传播、后向传播、评估等。如构建匹配矩阵和计算损失。
train_one_epoch()
模型和损失切换到训练状态。
记录日志信息,主要是损失。
最后生成metric_logger的所有信息。
evaluate()
@torch.no_grad()装饰器,在评估过程中不进行梯度计算和参数更新。
设置模型和损失设置为评估状态。
使用for循环遍历数据集中的每个批次,并在MetricLogger对象上记录指标。
将输入数据和目标数据移到GPU上,然后使用模型进行前向传递。
如果数据集包含分割任务,则将分割结果与目标进行比较,以获得更准确的结果。
对所有结果进行聚合,以获得数据集上的总体评估指标。输出评估指标,包括平均指标和COCO指标。