两个关键词 1. End to End(端到端的目标检测) 2. Transformers
目标检测里很少有端到端的方法 大部分方法 最后都需要一个后处理的操作 也就是nms(non-maximum suppression)这个操作 那么nms是什么?
"""
NMS:即非极大抑制 顾名思义就是抑制不是极大值的元素 搜索局部的极大值
在最近几年常见的物体检测算法(包括rcnn、sppnet、fast-rcnn、faster-rcnn等)中,最终都会从一张图片中找出很多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率。
假如我们检测一辆车
最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
所谓非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A<B<C<D<E<F。
(1) 从最大概率矩形框F开始,分别判断A、B、C、D、E与F的重叠度IOU(交并比:用预测框(A)和真实框(B)的交集除上二者的并集)是否大于某个设定的阈值;
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到所有被保留下来的矩形框。
"""
而正因为有了NMS的存在 模型在调参上就会变得非常复杂 而且即使训练好一个模型 部署起来也会非常苦难 因为NMS不是所有硬件都支持的 so DETR就很好解决了以上的痛点
它既不需要proposal 也不需要anchor 直接利用Transformer这种能全局建模的能力把目标检测看成一个集合预测的问题 而且因为有了这种能力 所以DETR不会输出那么多冗余的框 出什么结果就是什么结果 不再需要NMS
"""
什么是 proposal 和anchor??
anchor:个人理解是基于一个中心点创建出的几种大小和长宽比的框,这个中心点怎么确定呢?是根据Feature Map中每一个点在输入图片中对应的点
以Faster-RCNN举例
是在backbone的输入传入RPN后首先生成anchor,然后将anchor分别给两个分支去处理,一个分支使用softmax进行二分类,判断该anchor的框内有没有物体,有则为positive,没有则为negative;另一个分支进行边框回归,使anchor的边框更接近ground truth的框,因为默认生成的anchor框与实际框还是有偏差的。最终根据两个输出加原始图片信息生成Proposal。
其实具体anchor生成的过程还是不是很清楚。。。后续再补
proposal的生成过程:
第一步:先将前景的anchor按照softmax得到的score进行排序,然后取前N个positive anchor;
第二步:利用im_info中保存的信息,将选出的anchor由MxN的尺度还原回PxQ的尺度,刨除超出边界的anchor;
第三步:执行NMS(nonmaximum suppression,非极大值抑制);
第四步:将NMS的结果再次按照softmax的score进行排序,取N个anchor作为最终的Proposal;
"""
ok 大体过一遍 现在开始看论文
Abstract
我们提出了一种新的方法,将对象检测视为一个直接集预测问题。我们的方法简化了检测流程,有效地消除了许多手工设计组件的需要,如非最大抑制程序或锚定生成,这些组件显式编码了我们关于任务的先验知识。新框架被称为检测Transformer(DEtection TRansformer,简称DETR),其主要组成部分是1.基于集合的全局损耗(提出了一个新的目标函数),通过二分图匹配进行唯一的预测,2.以及Transformer编码器-解码器架构。给定一个固定的小集合的学习对象查询(transformer解码器的时候 还有另外一个输入 其实也有点类似于anchor的意思后面细讲),DETR根据对象(learned object queries)和全局图像上下文的关系来直接并行输出最终的预测集(这里有一个细节 in parallel 并行出框)。与许多其他现代探测器不同,新模型在概念上很简单,不需要专门的库。在具有挑战性的COCO对象检测数据集上,DETR展示了与完善的和高度优化的Faster RCNN基线相同的准确性和运行时性能。此外,该方法易于推广,比如在全景分割领域。我们表明,它明显优于竞争基线。
Introduction
对象检测的目标是为每个感兴趣的对象预测一组边界框和类别标签。现代检测器以间接的方式解决了这一集合预测任务,通过在Proposal(RCNN系列的工作Faster R-CNN、Mask R-CNN、Cascade R-CNN)[37,5]、锚定(Anchor)(YOLO Focal Loss)[23]或窗口中心(Non anchor base的方法 比如用物体的中心点 center net FCOS这种方法)[53,46]上定义代理回归和分类问题。
它们的性能受到以下因素的显著影响:瓦解接近重复预测的后处理步骤、锚集的设计以及将目标框分配给锚[52]的启发式方法。(效果都受限于后处理操作 也就是NMS)为了简化这些管道,我们提出了一种直接集预测方法来绕过代理任务。这种端到端的理念在机器翻译或语音识别等复杂的结构化预测任务中取得了重大进展,但在目标检测方面还没有取得进展:以前的尝试(learnable nms OR soft nms)[43,16,4,39]要么添加了其他形式的先验知识,要么在具有挑战性的基准测试中没有被证明与强大的基线具有竞争力。本文旨在弥补这一差距。
DETR整个流程
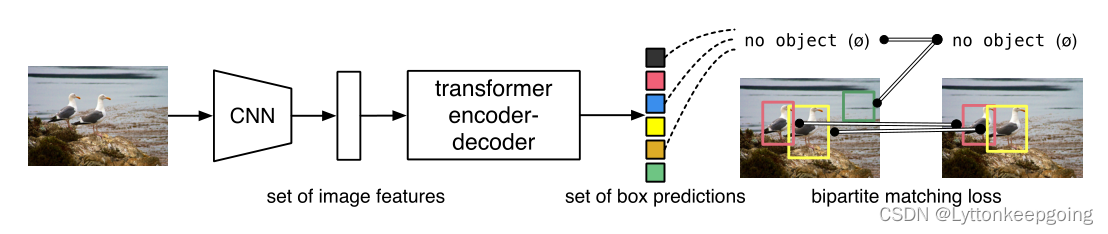
先用CNN去抽取特征 拿到这个特征之后 把它拉直(flatten) 送给transformer encoder-decoder 这里transformer encoder 可以进一步学习全局的信息
"""
为什么用transformer encoder ? 我的理解是 如果使用了transformer encoder 那每一个特征都会和图片里其他的特征都会有交互了 这样他大概就知道是哪块是哪个物体 对同一个物体来说 就只应该出一个框
"""
然后用transformer decoder 生成框的输出 其实这里还有一个 object query (这个query就是限定你要出多少个框 论文中限定的是100) 然后通过query和这个特征 在decoder里不停的交互 从而得到最后的输出的这个框
那么现在出的框怎么和ground truth 这个框做匹配 然后算loss呢?
他把这个问题看成是一个集合预测的问题 最后它可以用这种二分图匹配的方法(bipartite matching loss)去算这个loss 比如说上图中 ground truth其实只有两个框 那在训练的时候 通过算这100个预测的框 和这两个ground truth框之间的matching loss 从而决定出 在这100个预测中 那两个框是独一无二的对应到图中的红色和黄色的框 一旦决定好这个匹配关系之后 然后才会像普通的目标检测一样 去算一个分类的loss 再算一个bounding box的loss
那么推理的时候 matching loss就不需要了 直接在最后的输出上 用一个阈值去卡一下这个输出的置信度 最后模型比较自信的 就是哪些 置信度大于0.7的预测 就会被保留下来 也就是所谓的前景物体 其余的就是背景物体
"""
ok 问题又来了 什么是 二分图匹配 什么是 bounding box 的loss 就是边框回归 算真实框和现在狂之间的边框回归损失? 二分图匹配没弄懂。。。
"""
然后就说一下performance 第一个就是在COCO上 DETR和Faster-RCNN 效果差不多 但是大物体的ap和小物体的ap还是差很多的
1.DETR在小物体上表现不太好
2.DETR训练太慢 (作者训练了500个epoch 对于COCO来说 几十个epoch就行了 )
DETR目标函数
DETR模型最后的输出是一个固定的集合 就是任何一个图片出来 他都会给你扔出来一百个框 一般来说 这个N要比图片中包含的物体个数多很多 那么这里就有一个问题 DETR每次都会有一百个框 实际上 一个图片的ground truth 的bounding box可能只有几个 那么怎么做这种匹配 怎么算loss呢
这里就要介绍二分图匹配了
简单来说 就是 由一百个框 和 ground truth 构成一个 cost matrix 然后 把这个矩阵扔到spicy中的一个函数 (linear sum assignment)中 就能得到最优匹配结果
那么cost matrix 里面的值应该放什么呢 ?loss
loss怎么算呢? ![]()
就是一般目标检测的loss 第一个 就是分类的损失 第二个就是出框的准确度
所以说 就是遍历所有预测的框 拿这些预测的框去和ground truth的框去算这两个loss 然后生成 cost matrix
匹配好之后就可以算一个真正的目标函数 然后用这个loss 去做梯度回传 更新模型
最后的目标函数细节:

同样是两个loss 一般算分类 都用log去算loss 作者为了让第一个loss 和第二个loss大概在同样的取值空间 作者把这个log去掉了 用![]() 可以得到更好的性能 另一个loss 没有使用传统的L1loss 但是L1LOSS 和出框的大小有关系 这个框越大 出框的loss容易越大 因为tranformer对于大物体很友好 所以出框的loss会很大 不利于优化 然后作者就又加了一个loss Generalized IOU loss
可以得到更好的性能 另一个loss 没有使用传统的L1loss 但是L1LOSS 和出框的大小有关系 这个框越大 出框的loss容易越大 因为tranformer对于大物体很友好 所以出框的loss会很大 不利于优化 然后作者就又加了一个loss Generalized IOU loss
这个loss 就是跟框大小无关的一个目标函数
DETR网络框架
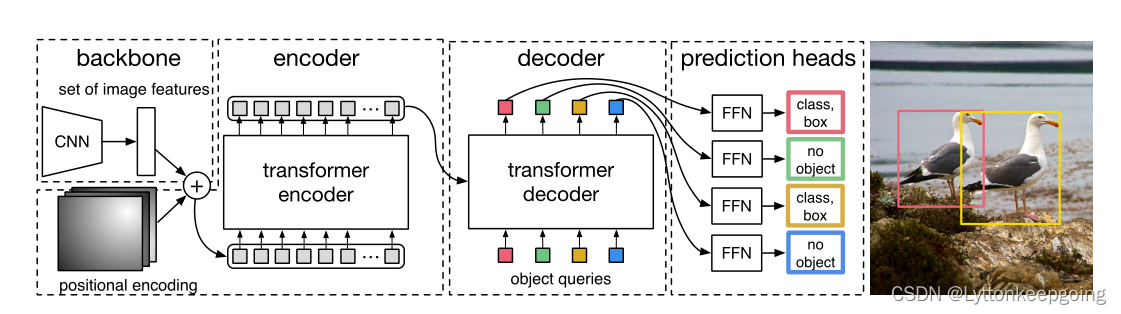
这里根据作者给的notebook 讲一下具体的前向过程
输入图片的大小是 3X800X1066 然后通过cnn 得到一些特征 走到cnn最后一层 走到conv5的时候
就会得到 2048X25X34的一个特征 因为要把这个特征 扔给transformer 然后作者就做了一个1x1的降维操作 就变成了 256X25X34 所以从backbone出来的维度 就是256X25X34 然后因为要进tranformer 因为transformer没有位置信息 所以要加入位置编码 这里面的位置编码其实是一个固定的位置编码 他的维度大小也是256X25X34 然后两个加起来 再把这个向量拉直 也就是把h和w拉直
变成一个数值 也就变成了 850X256 850就是序列长度 256就是transformer的hidden dimension
然后到decoder 部分 这里就有一个之前提到过的 object query 这个query其实是一个learnable query 他是可以学习的 准确的说 他是一个learnable position embedding 他的维度是100X256
256就是和之前的hidden dimension对应 那么100 就是告诉这个模型 我最后要得到100个输出 也就是100个框 然后在transformer decoder里面 其实做的是一个cross attention 比如说 输入是这个object query 100X256 然后还有另外一个输入呢 是从图像端拿来的全局特征 然后拿850X256和100X256 去反复做这种自注意力操作 最后就得到了一个100X256的特征 DETR也用了六层Decoder 每层的输入和输出的维度是不变的 始终是100X256进 100X256出 然后就是最后的检测头了 就是比较标准的 feed forword network 准确来说 就是把这个特征 给这些全连接层 然后这个全连接层呢 就会给你做两个预测 一个是做物体类别的预测 一个是出框的预测 类别呢 如果是COCO就是91类1X91 框就是四个值 1X4分别对应 xy 就是这个出框的中心点以及这个框的这个高度和宽度
然后补充材料里说 : 在每一个decoder里 都会先做一个objectquery的这个自注意力操作 然后说第一层 其实可以不做 但是后面那些层不能省掉 这里的自注意力操作主要就是为了移除这种冗余框 因为在他们交互之后 就知道每个query可能得到一个什么框 最后还有一个细节 就是最后算loss的时候
作者发现 为了让这个模型训练的更快 或者训练的更稳定 在decoder后面加了很多叫 auxiliary loss 就是加了很多额外的目标函数
伪代码:

首先定义一个DETR模型 num_classes COCO91类 hidden_dim 就是256 然后多头自注意力用了8
encoder decoder都用了6层
然后看初始化 首先要一个CNN的backbone 这里面呢就用了 pretrain好的resnet50 然后一个conv投射层 把2048变成256 然后就需要transformer encoder decoder 预测的时候就需要两个FFN 一个是类别预测 一个是框的FFN 然后就是这个query_pos 这里设置的是100 最后这个row_embed和col_embed是就是position embedding
这里的代码写的是真的简单!
到此DETR就讲解的差不多了 有少数坑没填 后面会补上。。