Abstract
动机:随着生物医学文献数量的快速增长,生物医学文本挖掘变得越来越重要。随着自然语言处理(NLP)的进步,从生物医学文献中提取有价值的信息已在研究人员中广受欢迎,而深度学习促进了有效的生物医学文本挖掘模型的发展。但是,由于单词分布从普通领域的语料库转移到生物医学的语料库,直接将NLP的进步应用到生物医学的文本挖掘常常会产生不令人满意的结果。在本文中,我们研究了最近引入的预训练语言模型BERT如何适用于生物医学语料库。
结果:我们介绍了BioBERT(来自生物医学文本挖掘的变压器的双向编码器表示),这是一种在大型生物医学语料库上预先训练的领域特定语言表示模型。通过在任务上几乎相同的体系结构,在经过生物医学语料库的预训练之后,BioBERT在许多生物医学文本挖掘任务中都大大优于BERT和以前的最新模型。尽管BERT的性能可与以前的最新模型相媲美,但在以下三个代表性的生物医学文本挖掘任务上,BioBERT的性能明显优于它们:生物医学命名实体识别(F1分数提高0.62%),生物医学关系提取(2.80%) F1分数提高)和生物医学问答(MRR提高12.24%)。我们的分析结果表明,对生物医学语料库进行BERT的预培训有助于其理解复杂的生物医学文献。
1 Introduction
生物医学文献的数量继续迅速增加。 平均而言,每天在同行评审的期刊上发表3000多篇新文章,不包括各种档案中的预印本和技术报告,例如临床试验报告。 截至2019年1月,仅PubMed就有2900万篇文章。包含有关新发现和新见解的宝贵信息的报告不断地被添加到本已大量的文献中。 因此,越来越需要用于从文献中提取信息的精确的生物医学文本挖掘工具。
自然语言处理(NLP)中使用的深度学习技术的进步,使生物医学文本挖掘模型的最新进展成为可能。例如,在过去几年中,长短期记忆(LSTM)和条件随机场(CRF)在生物医学命名实体识别(NER)方面的性能有了很大提高(Giorgi和Bader,2018; Habibi et al。,2017; Wang等人,2018; Yoon等人,2019)。其他基于深度学习的模型也改善了生物医学文本挖掘任务,例如关系提取(RE)(Bhasuran和Natarajan,2018; Lim和Kang,2018)和问答(QA)(Wiese等人,2017)。 )。
但是,将最新的NLP方法直接应用于生物医学文本挖掘具有局限性。首先,作为最近的单词表示模型,例如Word2Vec(Mikolov等,2013),ELMo(Peters等,2018)和BERT(Devlin等,2019),主要在包含通用域的数据集上进行训练和测试。文本(例如Wikipedia),很难估计它们在包含生物医学文本的数据集上的表现。同样,普通语料库和生物医学语料库的单词分布也有很大不同,这对于生物医学文本挖掘模型通常可能是一个问题。结果,近来生物医学文本挖掘中的模型主要依赖于单词表示的改编版本(Habibi等人,2017; Pyysalo等人,2013)。在这项研究中,我们假设需要在生物医学语料库上对当前最先进的词表示模型(例如BERT)进行训练,以有效地进行生物医学文本挖掘任务。 以前,Word2Vec是最广为人知的独立于上下文的词表示模型之一,它是在生物医学语料库上进行训练的,其中包含通常不包含在通用领域语料库中的术语和表达(Pyysalo等人,2013) 。 尽管ELMo和BERT已经证明了上下文化词表示法的有效性,但由于它们仅在通用领域的语料库上进行过训练,因此无法在生物医学语料库上获得高性能。 由于BERT在各种NLP任务上都取得了非常出色的结果,同时在整个任务中使用了几乎相同的结构,因此将BERT应用于生物医学领域可能会有益于众多生物医学NLP研究。
2 Approach
在本文中,我们介绍了BioBERT,它是针对生物医学领域的预先训练的语言表示模型。预训练和微调BioBERT的总体过程如图1所示。
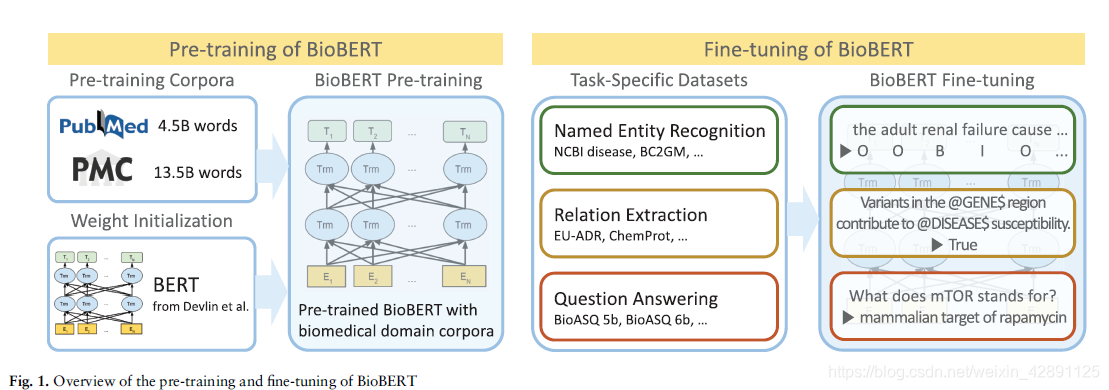
首先,我们使用BERT的权重初始化BioBERT,该BERT已在通用领域语料库(英语Wikipedia和BooksCorpus)上进行了预训练。然后,对BioBERT进行生物医学领域语料库的培训(PubMed摘要和PMC全文文章)。为了展示我们的方法在生物医学文本挖掘中的有效性,我们对BioBERT进行了微调,并对三种流行的生物医学文本挖掘任务(NER,RE和QA)进行了评估。我们用通用领域语料库和生物医学语料库的不同组合和大小来测试各种预训练策略,并分析每种语料库对预训练的影响。我们还提供了BERT和BioBERT的深入分析,以显示我们的预训练策略的必要性。
本文的贡献如下:
•BioBERT是第一个基于领域的基于BERT的模型,已在生物医学语料库上经过8天NVIDIA V100 GPU的预培训。
•我们显示,对BERT进行生物医学语料库的预培训可以大大提高其性能。与当前的最新模型相比,BioBERT在生物医学NER(0.62)和生物医学RE(2.80)中获得更高的F1评分,在生物医学QA中获得更高的MRR得分(12.24)。
•与以前的大多数主要专注于单个任务(例如NER或QA)的生物医学文本挖掘模型相比,我们的BioBERT模型在各种生物医学文本挖掘任务上均实现了最新的性能,而仅需进行最小的架构修改。
•我们公开提供了经过预处理的数据集,经过训练的BioBERT权重以及用于微调BioBERT的源代码。
3 Materials and methods
BioBERT基本上具有与BERT相同的结构。我们简要讨论了最近提出的BERT,然后详细介绍了BioBERT的预训练和微调过程。
3.1 BERT:来自变压器的双向编码器表示
从大量未注释的文本中学习单词表示法是一种悠久的方法。先前的模型(例如Word2Vec(Mikolov等人,2013),GloVe(Pennington等人,2014))专注于学习与上下文无关的单词表示,而最近的工作则专注于学习与上下文相关的单词表示。例如,ELMo(Peters等人,2018)使用双向语言模型,而CoVe(McCann等人,2017)使用机器翻译将上下文信息嵌入单词表示中。
BERT(Devlin等,2019)是一种基于上下文的词表示模型,该模型基于屏蔽语言模型并使用双向转换器进行了预训练(Vaswani等,2017)。由于无法看到将来的单词的语言建模的性质,以前的语言模型仅限于两个单向语言模型的组合(即,从左到右和从右到左)。 BERT使用掩蔽语言模型来预测序列中的随机掩蔽词,因此可用于学习双向表示。而且,它在大多数NLP任务上都具有最先进的性能,同时只需要最少的特定于任务的体系结构修改。 BERT的作者认为,合并双向表示而不是单向表示的信息对于以自然语言表示单词至关重要。我们假设这种双向表示在生物医学文本挖掘中也至关重要,因为生物医学语料库中经常存在生物医学术语之间的复杂关系(Krallinger等人,2017)。由于篇幅所限,我们请读者参考Devlin等。 (2019)进一步了解BERT。
3.2预训练BioBERT
作为通用语言表示模型,BERT在英语Wikipedia和BooksCorpus上进行了预培训。但是,生物医学领域文本包含大量领域特定的专有名词(例如,BRCA1,c.248T> C)和术语(例如,转录,抗微生物),这是生物医学研究人员普遍理解的。结果,为通用语言理解而设计的NLP模型通常在生物医学文本挖掘任务中表现不佳。在这项工作中,我们对BioBERT进行了PubMed摘要(PubMed)和PubMed Central全文文章(PMC)的预培训。表1列出了用于预训练BioBERT的文本语料库,表2列出了经过测试的文本语料库组合。为了提高计算效率,每当使用WikiþBooks语料库进行预训练时,我们都会使用Devlin等提供的预训练BERT模型。 (2019)。我们将BioBERT定义为一种语言表示模型,其预训练语料库包括生物医学语料库(例如BioBERT(þPubMed))。
对于令牌化,BioBERT使用WordPiece令牌化(Wu等人,2016),这减轻了语音不足的问题。使用WordPiece标记,任何新单词都可以由频繁的子单词表示(例如,Immunoglobulin 1⁄4> I ## mm ## uno ## g ## lo ## bul ## in)。我们发现,使用带格词汇(不是小写)可以在下游任务中获得更好的性能。尽管我们可以基于生物医学语料库构建新的WordPiece词汇表,但出于以下原因,我们使用了BERTBASE的原始词汇表:(i)BioBERT与BERT的兼容性,这使得可以重新使用在一般领域语料库上预先训练的BERT,并且可以更轻松地互换使用基于BERT和BioBERT的现有模型,并且(ii)仍然可以使用BERT的原始WordPiece词汇表对生物医学领域的任何新词进行表示和微调。
3.3微调BioBERT
只需进行最小的架构修改,即可将BioBERT应用于各种下游文本挖掘任务。我们针对以下三个具有代表性的生物医学文本挖掘任务对BioBERT进行了调整:NER,RE和QA。
命名实体识别
命名实体识别是最基本的生物医学文本挖掘任务之一,它涉及到识别生物医学语料库中的许多特定领域的专有名词。尽管以前的大多数工作都是基于LSTM和CRF的不同组合(Giorgi和Bader,2018年; Habibi等人,2017年; Wang等人,2018年),但BERT具有基于双向转换器的简单架构。 BERT基于来自最后一层的表示使用单个输出层来仅计算令牌级别的BIO2概率。请注意,虽然以前在生物医学NER中的工作经常使用在PubMed或PMC语料库上训练过的词嵌入(Habibi等人,2017; Yoon等人,2019),但BioBERT在预训练和微调期间直接学习WordPiece嵌入。对于NER的评估指标,我们使用了实体级别的准确性,召回率和F1得分。
关系提取是对生物医学语料库中命名实体的关系进行分类的任务。我们利用了BERT原始版本的句子分类器,该分类器使用[CLS]令牌进行关系分类。基于来自BERT的[CLS]令牌表示,使用单个输出层执行句子分类。我们使用预定义标签(例如@ GENE $或@ DISEASE $)使句子中的目标命名实体匿名。例如,具有两个目标实体(在这种情况下为基因和疾病)的句子表示为“ @ GENE $位置986上的丝氨酸可能是血管造影@ DISEASE $的独立遗传预测子。”报告RE任务的F1分数。
问题解答是根据相关段落回答以自然语言提出的问题的任务。为了对BioBERT进行质量检查进行微调,我们使用了与SQuAD相同的BERT架构(Rajpurkar等,2016)。我们使用了BioASQ事实数据集,因为它们的格式与SQuAD相似。答案短语开始/结束位置的令牌级别概率是使用单个输出层计算的。但是,我们观察到,在提取的质量检查设置中,约有30%的BioASQ类事实问题无法回答,因为确切的答案未出现在给定的步骤中。像Wiese等人。 (2017),我们从训练集中排除了具有无法回答问题的样本。同样,我们使用了Wiese等人的相同预训练过程。 (2017),它使用SQuAD,并在很大程度上提高了BERT和BioBERT的性能。我们使用了来自BioASQ的以下评估指标:严格的准确性,宽松的准确性和平均倒数排名。
4 Results
4.1数据集
表3列出了生物医学NER数据集的统计数据。我们使用Wang等提供的所有NER数据集的预处理版本。 (2018),但2010 i2b2 / VA,JNLPBA和Species-800数据集除外。
Wang,X. et al. (2018) Cross-type biomedical named entity recognition with deep multi-task learning. Bioinformatics, 35, 1745–1752.
我们将BERT和BioBERT与当前的最新模型进行比较,并报告其得分。请注意,每个最新模型都具有不同的体系结构和训练过程。例如,Yoon等人的最新模型。在JNLPBA数据集上训练的(2019)基于具有字符级CNN的多个Bi-LSTM CRF模型,而在LINNAEUS数据集上训练的Giorgi和Bader(2018)的最新模型使用Bi-LSTM CRF具有字符级LSTM的模型,并在银标准数据集中进行了进一步培训。另一方面,BERT和BioBERT具有完全相同的结构,并且仅使用黄金标准数据集,而不使用任何其他数据集。
Yoon,W. et al. (2019) Collabonet: collaboration of deep neural networks for biomedical named entity recognition. BMC Bioinformatics, 20, 249.
Giorgi,J.M. and Bader,G.D. (2018) Transfer learning for biomedical named entity recognition with neural networks. Bioinformatics, 34, 4087.
4.2 Experimental setups
用BERT基础模型在英语维基百科和BooksCorpus上进行预训练为了1M steps。BioBERT v1.0 (+PubMed +PMC) 是 BioBERT (+ PubMed +PMC) 训练了470K steps。在使用PubMed和PMC语料库时,发现PubMed和PMC分别采用200K和270K的预训练steps是最优的。初始释放BioBERT v1.0之后,预训练 BioBERT 在PubMed上1M steps,将这个版本称为BioBERT v1.1(+PubMed)。其他超参数,如批大小和训练前生物样本的学习速率调度与训练前BERT的相同,除非另有说明。
使用Naver Smart Machine Learning (NSML)对BioBERT进行预训练(Sung et al., 2017),该方法用于需要在多个GPU上运行的大型实验, 使用8个NVIDIA V100 (32GB) GPU进行预训练。最大序列长度固定为512,小批量大小设置为192,每次迭代得到98 304个单词。需要超过10天pre-train BioBERT v1.0(+PubMed+PMC)近23天BioBERT v1.1(+PubMed)在这个设置中。因为BERT (LARGE)的复杂性,这里仅仅用了基础的BERT。
我们使用一个NVIDIA Titan Xp (12GB) GPU微调每个任务的BioBERT。微调过程的计算效率比预训练的BioBERT更高。对于微调,选择批处理大小为10、16、32或64,学习率为5e-5,3e-5或者1e-5。对QA和RE任务的BioBERT进行微调所花费的时间不到一个小时,因为训练数据的大小远远小于Devlin等人(2019)使用的训练数据。另一方面,BioBERT在NER数据集上达到最高性能需要超过20个epochs。
4.3 Experimental results
NER的结果如表1所示。首先,我们观察到BERT在一般域语料库上进行预处理是非常有效的,但是BERT的micro averaged F1 score分数比最先进的模型低(低了2.01分)。另一方面,BioBERT在所有数据集上的得分都高于BERT。9个数据集中BioBERT在6个数据集上超过最先进的模型,BioBERT v1.1(+PubMed)优于最先进的模型0.62在micro averaged F1 评分上。LINNAEUS数据集得分相对较低的原因是:(i)缺乏用于训练以前的最先进模型的silver-standard数据集,(ii)以前工作中使用的不同的训练/测试集分割(Giorgi和Bader, 2018),这些数据集是不可用的。
表1(来自原文):

The best scores are in bold, and the second best scores are underlined.
