文章目录
Alt, C., et al. (2019). Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction. Proceedings ofthe 57th Annual Meeting ofthe Association for Computational Linguistics: 1388–1398.
code
abstrac
远程监督的关系提取被广泛用于从文本中提取关系事实,但是却带有嘈杂的标签。当前的关系提取方法试图通过多实例学习并通过提供支持的语言和上下文信息来减轻噪声,以更有效地指导关系分类。在获得最新结果的同时,我们观察到这些模型偏向于以高精度识别有限的一组关系,而忽略了那些长尾巴的关系。为了解决这一差距,我们利用了预训练的语言模型OpenAI生成式预训练的变压器(GPT)(Radford et al。,2018)。GPT和类似的模型已经显示出可以捕获语义和句法特征,并且还捕获了大量的“常识”知识,我们假设这些知识是识别更多种关系的重要特征。通过将GPT扩展到远程监督的设置,并在NYT10数据集上对其进行微调,我们显示出它可以预测具有较高置信度的更多不同类型的关系。手动和自动评估我们的模型表明,它在NYT10数据集上达到了0.422的最新AUC评分,并且在更高的召回水平下表现尤其出色。
- 远程监督
- 问题:有噪音,知识库不完整
- 解决:多实例学习+语言和上下文信息
- 问题:多实例倾向于识别多的关系,而忽略long-tail的关系
- 解决:本文(使用GPT
- 预训练GPT
- the OpenAI Generative Pre-trained Transformer
- 类似的模型:
- 可以捕获语义
- 捕获句法特征
- 捕获常识
- 本文:DISTRE
- 假设:这些知识是识别更多关系的重要特征
- 我们假设,经过预训练的语言模型可为远程监督提供更强的信号,并基于无监督的预训练中获得的知识更好地指导关系提取。用隐式特征替换显式语言和辅助信息可改善域和语言的独立性,并可能增加公认关系的多样性。
- 做法:将GPT扩展到远程监督
- 选择性注意机制+GPT
- 选择性注意机制:用以处理多实例
- 这样可以最大程度地减少显式特征提取,并减少错误累积的风险。
- 选择性注意机制:用以处理多实例
- self-attention的体系结构允许模型有效地捕获远程依赖关系,
- 而语言模型则可以利用有关在无监督的预训练过程中获得的实体与概念之间的关系的知识。
- 选择性注意机制+GPT
- 数据集:NYT10
- 本文贡献
- 通过汇总句子级别的信息并有选择地关注以产生袋子级别的预测(第3节),我们将GPT扩展为处理远程监管数据集的袋子级别,多实例训练和预测。
- 我们在NYT10数据集上评估了精细调整的语言模型,并证明了它与RESIDE(Vashishth等人,2018)和PCNN + ATT(Lin等人,2016)相比,在持续评估中(§4,§5.1)获得了最新的AUC。
- 我们通过对排名预测进行手动评估来跟踪这些结果,这表明我们的模型预测了一组更多样化的关系,并且在较高的召回水平下表现尤其出色(第5.2节)。
- 假设:这些知识是识别更多关系的重要特征
1.Introduction
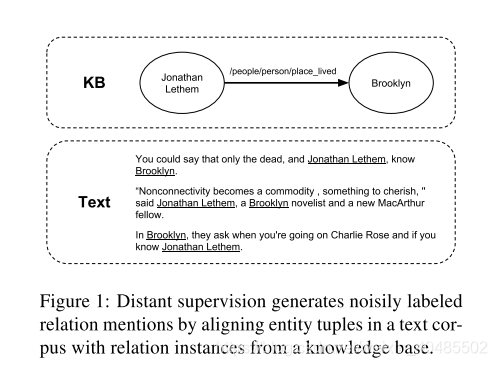
关系提取(RE)被定义为识别文本中提到的概念之间的关系的任务,是许多自然语言处理应用程序的重要组成部分,例如知识库(Ji和Grishman,2011)和问题解答(Yu等)。 。,2017)。远程监管(Mintz等人,2009; Hoffmann等人,2011)是一种流行的方法,可通过将文本中的实体元组与知识库中的已知关系实例对齐来启发式地生成用于训练RE系统的标记数据,但会产生嘈杂的标记和不完整的知识库信息(Min等人,2013; Fan等人,2014)。图1显示了三个标记有现有KB关系的句子的示例,其中两个是误报,实际上并未表达该关系。
当前最先进的RE方法试图通过应用多实例学习方法(Mintz等,2009; Surdeanu等,2012; Lin等,2016)并通过明确指导模型来应对这些挑战提供的语义和句法知识,例如词性标签(Zeng等,2014)和依存关系解析信息(Surdeanu等,2012; Zhang等,2018b)。最近的方法还利用辅助信息,例如释义,关系别名和实体类型(Vashishth et al。,2018)。但是,我们注意到这些模型通常偏向于以高精度识别有限的一组关系,而忽略了长尾关系(请参见5.2节)。
- 当前远程监督:
- 多实例学习:(Mintz等,2009; Surdeanu等,2012; Lin等,2016)
- 通过明确指导模型来应对这些挑战提供的语义和句法知识,
- 例如词性标签(Zeng等,2014)和
- 依存关系解析信息(Surdeanu等,2012; Zhang等,2018b)。
- 最近的方法还利用辅助信息,例如
- 释义,关系别名和实体类型(Vashishth et al。,2018)
深度语言表示,例如由Transformer(Vaswani等人,2017)通过语言建模(Radford等人,2018)学到的内容已被证明仅通过无监督的预训练即可隐式捕获文本的有用语义和句法属性(Peters等人, 2018年),如在各种自然语言处理任务上的先进表现所证明的那样(Vaswani等人,2017; Peters等人,2018; Radford等人,2018; Devlin等人, 2018),包括监督关系提取(Alt等人,2019)。Radford等。 (2019年)甚至发现语言模型在回答开放域问题时表现出色,而无需接受实际任务的培训,这表明它们捕获了数量有限的“常识”知识。
- 我们假设,经过预训练的语言模型可为远程监督提供更强的信号,并基于无监督的预训练中获得的知识更好地指导关系提取。用隐式特征替换显式语言和辅助信息可改善域和语言的独立性,并可能增加公认关系的多样性。
在本文中,我们介绍了一种用于关系提取的远程监督变压器(DISTRE)。我们通过选择性注意机制扩展了标准的Transformer体系结构,以处理多实例学习和预测,这使我们可以直接在远程监督的RE任务上微调预训练的Transformer语言模型。这样可以最大程度地减少显式特征提取,并减少错误累积的风险。另外,自我专注的体系结构允许模型有效地捕获远程依赖关系,而语言模型则可以利用有关在无监督的预训练过程中获得的实体与概念之间的关系的知识。与竞争基准模型相比,我们的模型在NYT10数据集上的最新AUC得分达到0.422,并且在较高的召回水平下表现尤其出色。我们选择GPT作为我们的语言模型是因为它的微调效率和合理的硬件要求,相比于基于LSTM的语言模型(Ruder和Howard,2018; Peters等,2018)或BERT(Devlin等,2018)。
- 本文贡献
- 通过汇总句子级别的信息并有选择地关注以产生袋子级别的预测(第3节),我们将GPT扩展为处理远程监管数据集的袋子级别,多实例训练和预测。
- 我们在NYT10数据集上评估了精细调整的语言模型,并证明了它与RESIDE(Vashishth等人,2018)和PCNN + ATT(Lin等人,2016)相比,在持续评估中(§4,§5.1)获得了最新的AUC。
- 我们通过对排名预测进行手动评估来跟踪这些结果,这表明我们的模型预测了一组更多样化的关系,并且在较高的召回水平下表现尤其出色(第5.2节)。
2 Transformer Language Model
- 介绍:the Transformer language model as introduced by Radford et al. (2018).
- 我们首先定义变压器解码器(第2.1节),
- 然后介绍如何通过语言建模目标函数学习上下文表示(第2.2节)。
2.1 Transformer-Decoder
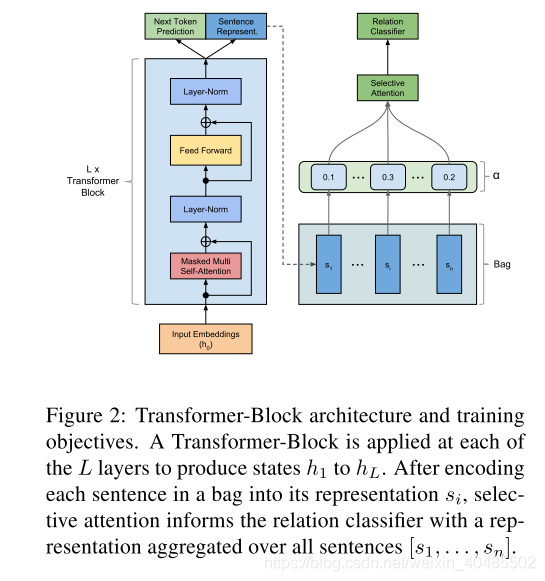
图2中所示的Transformer-Decoder(Liu等人,2018a)是原始Transformer的仅解码器变体(Vaswani等人,2017)。像原始的Transformer一样,该模型在多层(即Transformer块)上重复编码给定的输入表示形式,包括遮盖的多头自我注意,然后进行位置前馈操作。与原始解码器块相反,此版本不包含任何形式的非屏蔽自我关注,因为没有编码器块。形式化如下:
- Transformer-Decoder(Liu等人,2018a)
- 原始Transformer的仅解码器变体(Vaswani等人,2017)
- 在多层(即Transformer块)上
- 重复编码给定的输入表示形式,包括
- masked的多头自我注意,
- 然后进行位置前馈操作
- 重复编码给定的输入表示形式,包括
- 与origin不同:不包含任何形式的非屏蔽自我关注,因为没有编码器块
-
- T :is a matrix of one-hot row vectors of the token indices in the sentence
- We:word embedding
- Wp:position embedding
2.2 Unsupervised Pre-training of Language Representations
- 目标函数:极大似然估计
-
- C–语料,
- k-窗口尺寸
-
3 Multi-Instance Learning with the Transformer
3.1 Distantly Supervised Fine-tuning on Relation Extraction
- 标签r不可靠,所以用bag_level
- bag:
- 包的表达式:
- 包的表达式:
3.2input represent
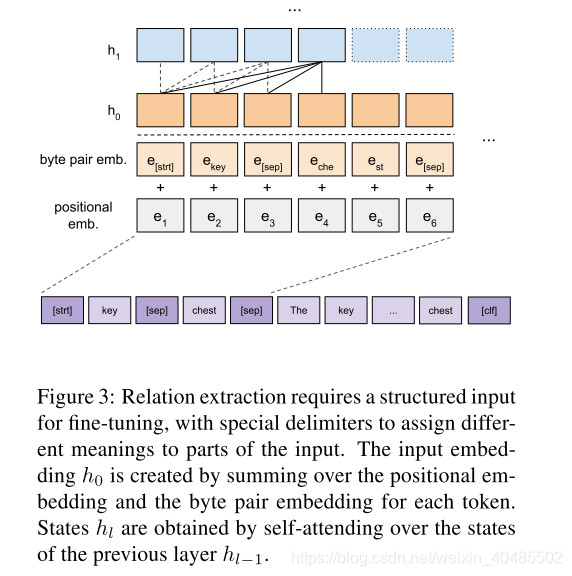
我们的输入表示形式(参见图3)将每个句子编码为标记序列。为了利用子词信息,我们使用
- 字节对编码(BPE)对输入文本进行标记化(Sennrich et al。,2016)。
- BPE算法创建以单个字符开头的子单词标记的词汇表。
- 然后,该算法将最频繁出现的令牌迭代合并到新令牌中,直到达到预定的词汇量为止。
- 对于每个令牌,我们通过将相应的令牌嵌入和位置嵌入相加来获得其输入表示。
虽然该模型在纯文本句子上进行了预训练,但是关系提取需要结构化的输入,即句子和关系参数。为了避免特定于任务的体系结构更改,我们采用类似于Radford等人的遍历样式方法。 (2018)。特定于任务的结构化输入被转换为有序序列,无需架构更改即可直接输入模型。图3直观地显示了输入格式。它从头和尾实体的标记开始,由定界符分隔,然后是包含实体对的句子的标记序列,并以特殊的分类标记结束。分类令牌向模型发出信号,以生成用于关系分类的句子表示。由于我们的模型是从左到右处理输入的,因此我们将关系参数添加到开头,以在处理句子的标记序列时将注意力机制偏向于标记表示。
- traversal-style approach similar to Radford et al. (2018).
- 纯文本–>有序序列:避免结构更改
4.实验
- 数据集:NYT10
- 其中2005-2006年用于培训,
- 2007年用于测试
- baseline:
- PCNN + ATTN(Lin等人,2016)
- 将每个输入语句分成实体对的左,中和右部分,然后进行卷积编码和选择性注意,以袋级表示形式通知关系分类器。
- RESIDE(Vashishth等人,2018)
- RESIDE使用双向门控循环单元(GRU)编码输入语句,然后
- 使用图卷积神经网络(GCN)编码显式提供的依存关系分析树信息。
- 然后,将其与命名实体类型信息组合在一起,以获得可以通过选择性注意进行汇总并转发给关系分类器的句子表示。
- PCNN + ATTN(Lin等人,2016)
4.2pre-train
- we reuse the language model3 published by Radford et al. (2018) for our experiments.
- 该模型在BooksCorpus上进行了训练(Zhu等人,2015年),其中包含约7,000种未出版的书籍,总共有超过8亿个单词的不同体裁。该模型由具有12个关注头和768维状态的解码器块以及3072维状态的前馈层组成。我们重用了该模型的字节对编码词汇byte-pair encoding,但使用任务特定的令牌(例如,开始,结束,定界符)对其进行了扩展。
4.3参数
- adam
5.Result
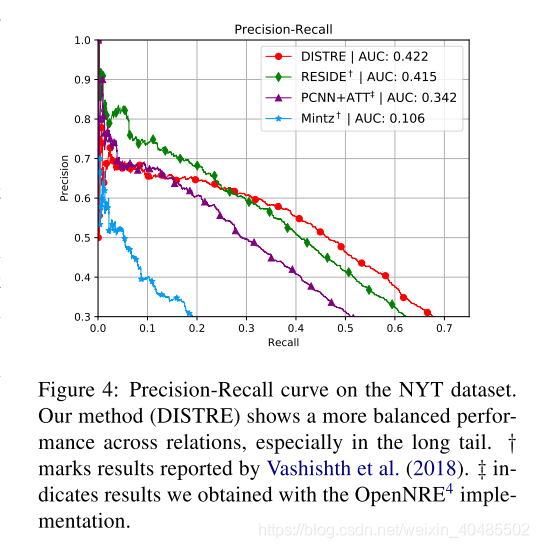
5.1 Held-out Evaluation
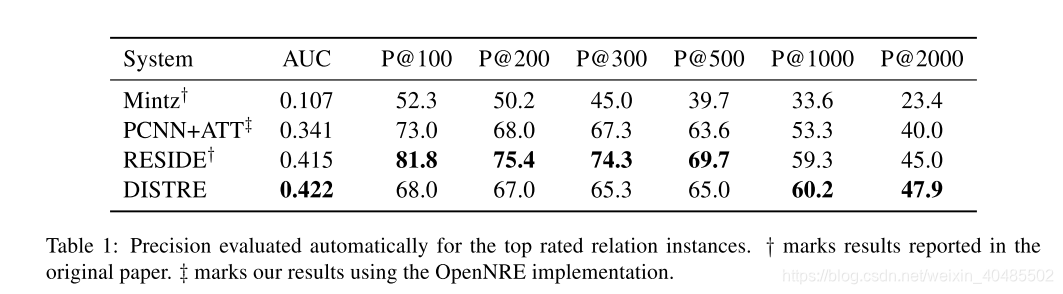
- 这表明PCNN模型对短模式和简单模式的排名高于参数之间距离较大的更复杂模式。
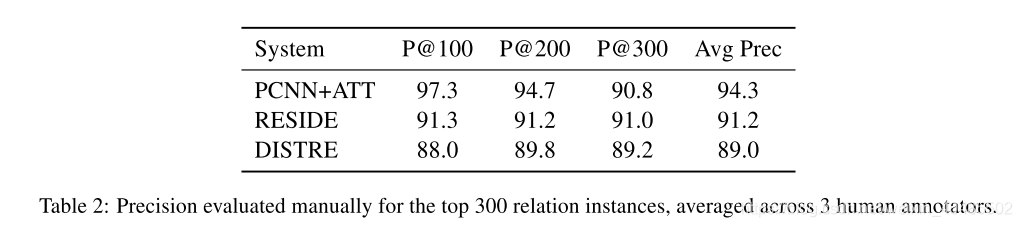
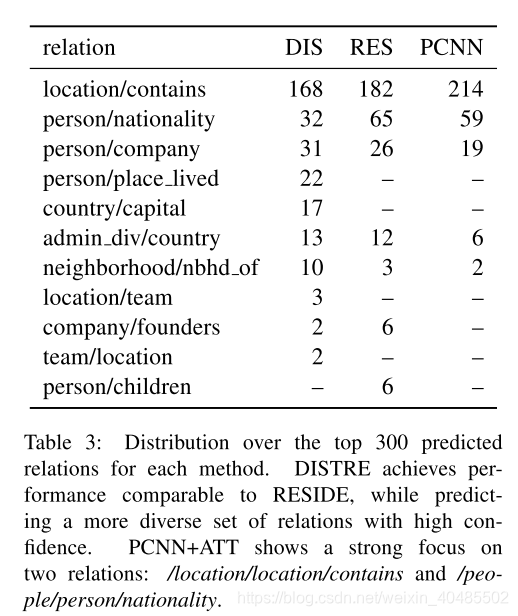
6.相关工作
- 关系提取RE中的初始工作使用统计分类器或基于内核的方法,结合离散的句法特征,
- 例如词性和命名实体标签,形态特征和WordNet上位词(Mintz等,2009; Hendrickx等。 ,2010)。
- 这些方法已被基于序列的方法所取代,包括
- 递归(Socher等人,2012; Zhang和Wang,2015)和
- 卷积神经网络(Zeng等人,2014,2015)。
- 因此,离散特征已被单词和句法特征的分布式表示所取代(Turian等,2010; Pennington等,2014)。
- 徐等。 (2015a,b)将最短依赖路径(SDP)信息集成到基于LSTM的关系分类模型中。
- 考虑到SDP对于关系分类很有用,因为它专注于句子中的动作和主体(Bunescu和Mooney,2005年; Socher等人,2014年)
- 。张等。 (2018b)通过将修剪和图卷积的组合应用于依赖树,为TACRED数据集上的关系提取建立了新的技术。
- 最近,Verga等人。 (2018)通过自定义架构扩展了Transformer架构,用于受监管的生物医学命名实体和关系提取。相比之下,我们微调了预训练的语言表示,只需要远距离监督的注释标签。
- 远程监督关系提取早期远程监督方法
- (Mintz等,2009)使用多实例学习(Riedel等,2010)和
- 多实例多标签学习(Surdeanu等,2012; Hoffmann等, (2011)建立模型,假设每个关系实例至少可以正确表达一个关系。
- 随着神经网络的日益普及,
- PCNN(Zeng等,2014)成为使用最广泛的架构,扩展了多实例学习(Zeng等,2015),
- 选择性注意(Lin等,2016; Han等,2018),
- 对抗训练(Wu等,2017; Qin等,2018),
- 噪声模型(Luo等,2017)和
- 软标签(Liu等,2017; Wang等)等(2018)。
- 最近的工作表明
- 图卷积(Vashishth等人,2018)和
- 胶囊网络(Zhang等人,2018a),先前应用于监督环境(Zhang等人,2018b),也适用于远距离监督环境。
- 此外,语言和语义背景知识对完成任务很有帮助,但建议的系统通常依赖于显式功能,例如
- 依赖关系树,命名实体类型和关系别名(Vashishth等人,2018; Yaghoobzadeh等人,2017) )或
- 任务和领域特定的预训练(Liu等人,2018b; He等人,2018),而
- distre仅依赖于语言模型在无监督的预训练过程中捕获的特征。
- 语言表示形式和迁移学习深度语言表示形式已被证明是无监督预训练的有效形式。
- 彼得斯等。 (2018)引入了来自语言模型(ELMo)的嵌入,这是一种通过训练双向LSTM来优化不相交的双向语言模型目标来学习上下文化单词表示的方法。他们的结果表明,用上下文化的词表示代替静态的预训练词向量(Mikolov等,2013; Pennington等,2014)可显着提高各种自然语言处理任务的性能,例如语义相似性,共指解析和语义。角色标签。
- Ruder和Howard(2018)发现无监督语言建模学习的语言表示形式可以显着提高文本分类性能,防止过度拟合并提高样本效率。
- Radford等。 (2018)证明了我们的模型所基于的通用域预训练和任务特定的微调在几个问题回答,文本分类,文本蕴涵和语义相似性任务上取得了最新的成果。
- Devlin等。 (2018)通过引入空位填充目标来共同训练双向语言模型,进一步扩展了语言模型的预训练。最近(Radford等人,2019)发现,语言模型的大小显着增加,可以更好地将其推广到下游任务,同时仍然不足以容纳大型文本语料库。
