课程来源:吴恩达 深度学习课程 《神经网络基础》
笔记整理:王小草
时间:2018年5月15日
1.神经网络概览
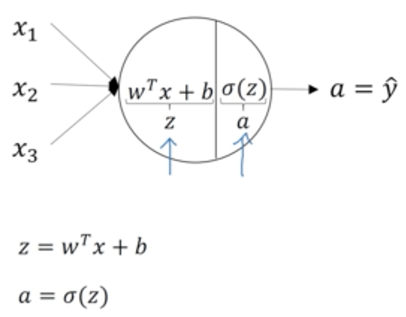
回顾逻辑回归的结构:

圆圈节点内的计算如下,先计算线性z,再过一个sigmoid函数得到a,然后计算损失函数,进行梯度下降法求最优参数。

推广到神经网络,每个圆圈节点都代表以上z,a两步计算(第一层用1表示,第而层用2表示)
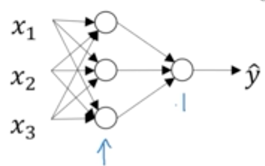
相当于如下计算过程:

同样使用反向传播可以计算出梯度,并寻找最优参数
2.神经网络表示
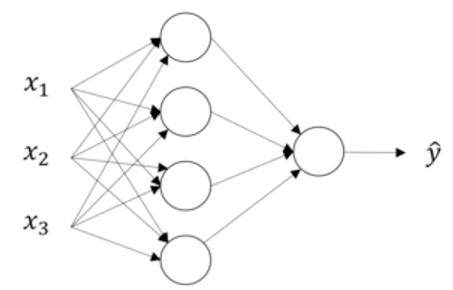
以上神经网络,第一层是输入层,第二层是隐藏层,第三层是输出层。因此这是一个两层的神经网络(一般我们不算输入层)。
输入层:
用a[i]表示第i层的计算结果,也就是第i+1层的输入。因此输入层传递给隐藏层的数据,就是输入x本身,即a[0] = x
隐藏层:
第一个隐藏层的计算结果用a[1]表示,由于隐藏层中有4个节点(神经元),每个节点的计算结果可以用a1j表示:
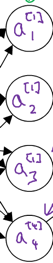
即a[1]可以表示成:

输出层:
输出层表示为a[2],即为最终的输出y^
3.神经网络输出
神经网络到底最后会计算出什么鬼?
每个神经元的计算如下:
隐藏层计算:
那么整个神经网络其实就是在重复以上过程的叠加。首先看隐藏层的四个节点,每个节点都先计算z,a:

将这四个等式用向量表示:
w用向量表示如下,由于前一层是3维,本层是4维,因此w矩阵的大小是(4,3)
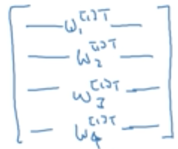
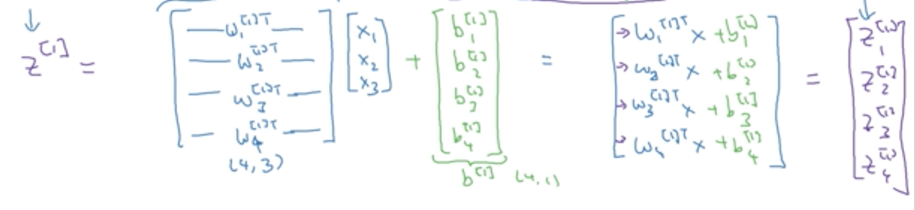
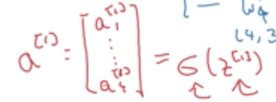
简写之后如下:
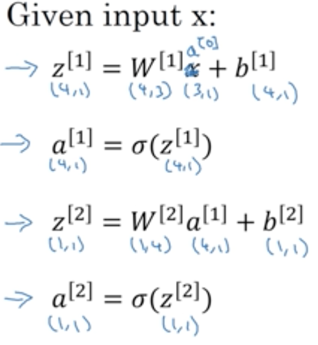
输出层计算:
将上一层的输出作为本层的输入,其实就是逻辑回归的过程。

4.多个样本向量化
上文是单个样本的向量化计算,下面推广到多个样本的向量计算,从而避免使用for循环。
对于一个样本
若有m个样本,则有m个输入x(i),m个输出y(i):
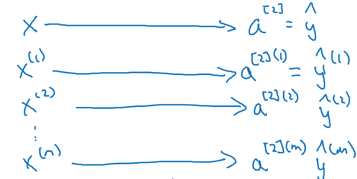
a[l](i)表示第l层的第i个样本。
若使用for循环遍历每个样本,则会有这般光景:
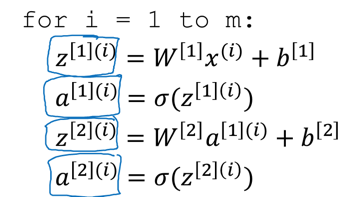
若使用向量化计算,则又是这般天地:
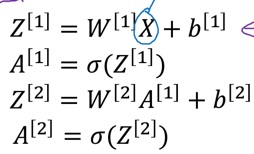
其中X如下:每一列为一个样本,每个样本有n维特征,矩阵大小为n*m,则:
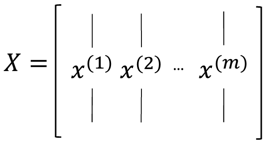
Z1如下,每一列荏苒是对应一个样本
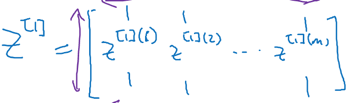
A1如下,每一列仍然是对应一个样本,是每个样本的激活值,每一列的元素个数于改隐藏层的神经元个数一致:
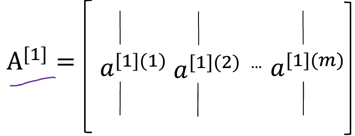
5.向量化实现的解释
解释向量计算的过程,假设有如下3个样本

则过程如下:

W1表示第一个隐藏层的权重矩阵,有n行N1列,n是对应样本x的特征维度,N1代表第一个隐藏层的神经元个数
将W1与X相乘之后,会得到m*k大小的Z矩阵,每一列对应一个样本,每一列的元素个数对应神经元的个数
为何要一列为一个样本呢?
因为这样W于X两个矩阵相乘之后得到的z也是一列为一个样本,这样保证里X于Z的对齐。
6.激活函数
6.1 sigmoid函数
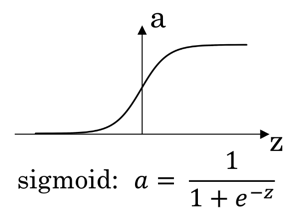
sigmoid函数在神经网络中一般不太用,一般用于二分类中,因为而分类需要得到0/1类,而sigmoid函数刚好是在[0,1]之间
6.2 tanh函数

tanh优于sigmoid函数,因为其均值为0,实现了数据中心化的效果。
若神经网络是用于二分类的, 则为了实现最后输出[0,1],可以在最后一层用sigmoid函数,前面用其他激活函数。可见,在同一个网络中不同层可根据不同需求使用不同的激活函数。
但无论是sigmoid函数还是tanh函数都有一个致命的缺点,当输入z无穷大时, a回无限接近于0/1或-1/1, 即其鞋履接近0,在梯度下降时回拖慢梯度下降的效率,因此实践中一般回使用更受欢迎的Relu函数
6.3 Relu函数
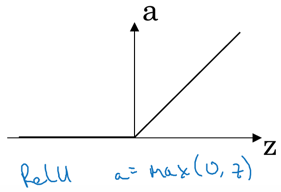
当z<=0时, a=0。若经过这个激活函数出现了很多0,那也没事,可以自己给这些0赋其他值。若做二分类,则最后一层用sigmoid函数,其他层可以用Relu函数。
6.4 Leaky Relu函数

Leaky Relu解决了Relu多0的问题,但实际中用Relu更多。但无论是Leaky Relu还是Relu都比sigmoid函数要快很多,因为没有鞋履接近于0的情况。
6.5 为何需要使用非线性函数
若使用线性函数作为激活函数,则神经网络的计算如下:
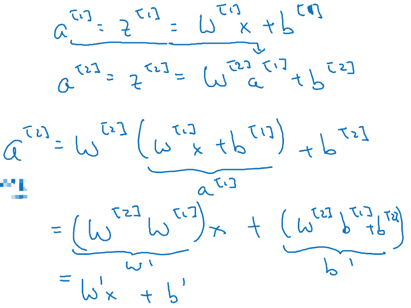
可见经过线性激活函数,无论神经网络设多少层,都是在计算线性函数而已。
但线性函数也不是一无是处,比如在做线性回归时可以使用线性激活函数,再比如当腰预测一个实数时,可在神经网络的最后一层设置线性激活函数。
7.激活函数的导数
7.1 sigmoid的导数
函数:

导数:
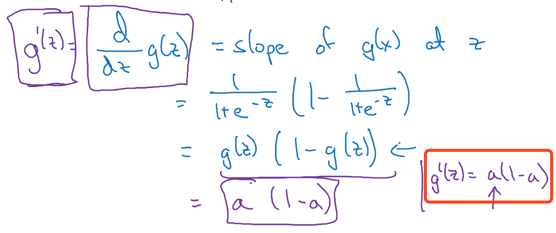
7.2 tanh的导数
函数:
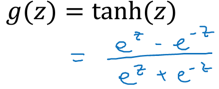
导数:
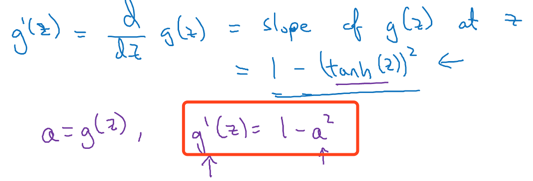
7.3 ReLU和Leaky RelU的导数
函数:

导数:
ReLu导数:
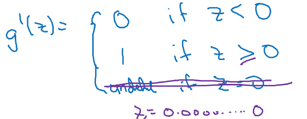
Leaky RelU导数:
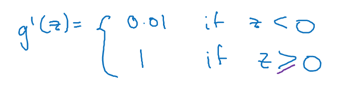
8.神经网络的梯度下降法
以一个2层的神经网络来做示范计算梯度下降
首先,明确参数:

接着,明确成本函数:

然后,可以进行梯度下降的迭代了,重复以下过程
(1)第一步,先前向计算出每个样本的预测值y^(1)…y^(m)
(2)根据成本函数,计算每个参数的导数:
(3)根据学习率更新参数:
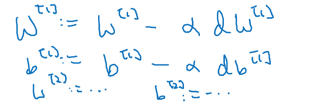
将以上过程用公式的形式表示:
(1)第一步,前向计算没个样本点预测值:
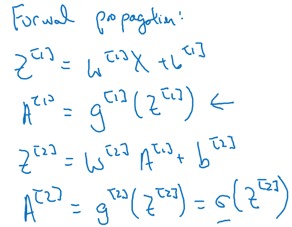
(2)反向传播:
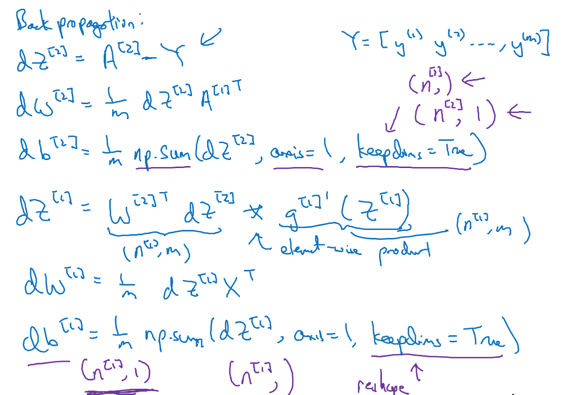
9.直观理解反向传播
9.1 逻辑回归反向传播
回顾逻辑回归:

逻辑回归的反向传播过程如下:
先计算a的导数da:
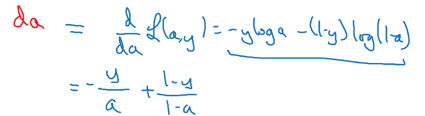
再计算z的导数dz:

从而计算w与b的倒数:
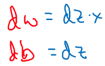
9.2 神经网络反向传播
神经网络前向计算如下:

同理的反向传播
先计算da2,然后一步一步往回退,求各参数的导数:
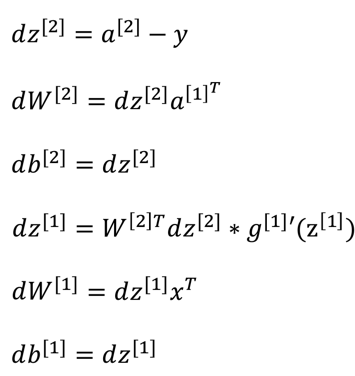
用向量来表示(大写字母表示vector):
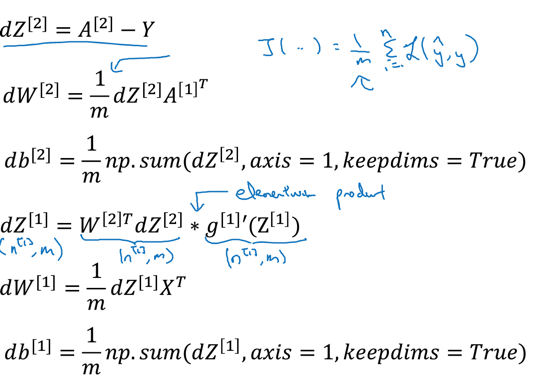
10.随机初始化
权重的初始化也很重要,影响模型接下去的效果。
假如权重初始化得太小,比如都接近于0:

则同一层中的神经元的值都会相等,从而反向传播计算的梯度也会相等。

但其实我们更希望每个神经元能学习不同的特征,有不同的值。
但权重也不能太大,若w大,则z大,则经过sigmoid或者tanh之后,都接近于1/0或1/-1,再反向传播时会出现导数为0.但若不适用sigmoid或者tanh,则w大一点也无所谓的。