测试时的 BatchNorm (Batch Norm at Test Time)
Batch归一化将你的数据以mini-batch的形式逐一处理,但在测试时,你可能需要对每个样本逐一处理,我们来看一下怎样调整你的网络来做到这一点。

回想一下,在训练时,这些就是用来执行Batch归一化的等式。在一个mini-batch中,你将mini-batch的 值求和,计算均值,所以这里你只把一个mini-batch中的样本都加起来,我用 来表示这个mini-batch中的样本数量,而不是整个训练集。然后计算方差,再算 ,即用均值和标准差来调整,加上 是为了数值稳定性。 是用 和 再次调整 得到的。
请注意用于调节计算的 和 是在整个mini-batch上进行计算,但是在测试时,你可能不能将一个mini-batch中的6428或2056个样本同时处理,因此你需要用其它方式来得到 和 ,而且如果你只有一个样本,一个样本的均值和方差没有意义。那么实际上,为了将你的神经网络运用于测试,就需要单独估算 和 ,在典型的Batch归一化运用中,你需要用一个指数加权平均来估算,这个平均数涵盖了所有mini-batch,接下来我会具体解释。
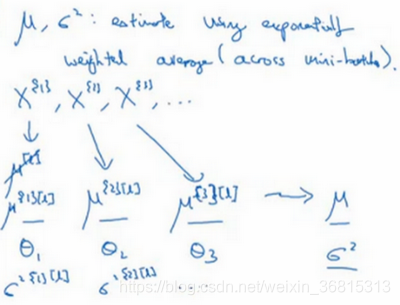
我们选择 层,假设我们有mini-batch, 以及对应的 值等等,那么在为 层训练 时,你就得到了 ,我还是把它写做第一个mini-batch和这一层的 吧,( )。当你训练第二个mini-batch,在这一层和这个mini-batch中,你就会得到第二个 ( )值。然后在这一隐藏层的第三个mini-batch,你得到了第三个 ( )值。正如我们之前用的指数加权平均来计算 的均值,当时是试着计算当前气温的指数加权平均,你会这样来追踪你看到的这个均值向量的最新平均值,于是这个指数加权平均就成了你对这一隐藏层的 均值的估值。同样的,你可以用指数加权平均来追踪你在这一层的第一个mini-batch中所见的 的值,以及第二个mini-batch中所见的 的值等等。因此在用不同的mini-batch训练神经网络的同时,能够得到你所查看的每一层的 和 的平均数的实时数值。

最后在测试时,对应这个等式( ),你只需要用你的 值来计算 ,用 和 的指数加权平均,用你手头的最新数值来做调整,然后你可以用左边我们刚算出来的 和你在神经网络训练过程中得到的 和 参数来计算你那个测试样本的 值。
总结一下就是,在训练时, 和 是在整个mini-batch上计算出来的包含了像是64或28或其它一定数量的样本,但在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算 和 ,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到 和 ,但在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的 和 的值。还可以用指数加权平均,有时也叫做流动平均来粗略估算 和 ,然后在测试中使用 和 的值来进行你所需要的隐藏单元 值的调整。在实践中,不管你用什么方式估算 和 ,这套过程都是比较稳健的,因此我不太会担心你具体的操作方式,而且如果你使用的是某种深度学习框架,通常会有默认的估算 和 的方式,应该一样会起到比较好的效果。但在实践中,任何合理的估算你的隐藏单元 值的均值和方差的方式,在测试中应该都会有效。
Batch归一化就讲到这里,使用Batch归一化,你能够训练更深的网络,让你的学习算法运行速度更快,在结束这周的课程之前,我还想和你们分享一些关于深度学习框架的想法,让我们在下一段视频中一起讨论这个话题。
课程PPT


