归一化网络的激活函数 (Normalizing Activations in a Network)
在深度学习兴起后,最重要的一个思想是它的一种算法,叫做Batch归一化,由Sergey loffe和Christian Szegedy两位研究者创造。Batch归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会是你的训练更加容易,甚至是深层网络。让我们来看看Batch归一化是怎么起作用的吧。

当训练一个模型,比如logistic回归时,你也许会记得,归一化输入特征可以加快学习过程。你计算了平均值,从训练集中减去平均值,计算了方差,接着根据方差归一化你的数据集,在之前的视频中我们看到,这是如何把学习问题的轮廓,从很长的东西,变成更圆的东西,更易于算法优化。所以这是有效的,对logistic回归和神经网络的归一化输入特征值而言。
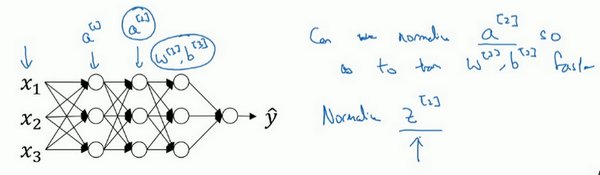
那么更深的模型呢?你不仅输入了特征值 ,而且这层有激活值 ,这层有激活值 等等。如果你想训练这些参数,比如, 那归一化 的平均值和方差岂不是很好?以便使 的训练更有效率。在logistic回归的例子中,我们看到了如何归一化 ,会帮助你更有效的训练 和 。
所以问题来了,对任何一个隐藏层而言,我们能否归一化 值,在此例中,比如说 的值,但可以是任何隐藏层的,以更快的速度训练, 因为 是下一层的输入值,所以就会影响 的训练。简单来说,这就是Batch归一化的作用。尽管严格来说,我们真正归一化的不是 ,而是 ,深度学习文献中有一些争论,关于在激活函数之前是否应该将值 归一化,或是否应该在应用激活函数 后再规范值。实践中,经常做的是归一化 ,所以这就是我介绍的版本,我推荐其为默认选择,那下面就是Batch归一化的使用方法。

在神经网络中,已知一些中间值,假设你有一些隐藏单元值,从 到 ,这些来源于隐藏层,所以这样写会更准确,即 为隐藏层, 从1到 ,但这样书写,我要省略 及方括号,以便简化这一行的符号。所以已知这些值,如下,你要计算平均值,强调一下,所有这些都是针对 层,但我省略 及方括号,然后用正如你常用的那个公式计算方差,接着,你会取每个 值,使其规范化,方法如下,减去均值再除以标准偏差,为了使数值稳定,通常将 作为分母,以防 的情况。
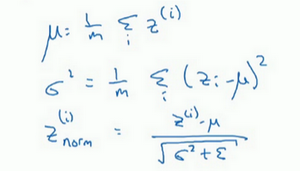
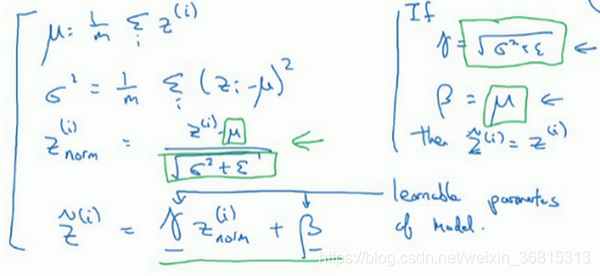
所以现在我们已把这些 值标准化,化为含平均值0和标准单位方差,所以 的每一个分量都含有平均值0和方差1,但我们不想让隐藏单元总是含有平均值0和方差1,也许隐藏单元有了不同的分布会有意义,所以我们所要做的就是计算,我们称之为 , ,这里 和 是你模型的学习参数,所以我们使用梯度下降或一些其它类似梯度下降的算法,比如Momentum或者Nesterov,Adam,你会更新 和 ,正如更新神经网络的权重一样。

请注意 和 的作用是,你可以随意设置 的平均值,事实上,如果 ,如果 等于这个分母项( 中的分母), 等于 ,这里的这个值是 中的 ,那么 的作用在于,它会精确转化这个方程,如果这些成立( ),那么 。
通过对 和 合理设定,规范化过程,即这四个等式,从根本来说,只是计算恒等函数,通过赋予 和 其它值,可以使你构造含其它平均值和方差的隐藏单元值。
所以,在网络匹配这个单元的方式,之前可能是用 等等,现在则会用 取代 ,方便神经网络中的后续计算。如果你想放回 ,以清楚的表明它位于哪层,你可以把它放这。
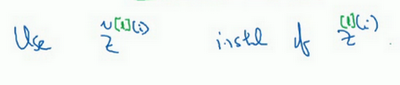
所以我希望你学到的是,归一化输入特征 是怎样有助于神经网络中的学习,Batch归一化的作用是它适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。你应用Batch归一化了一些隐藏单元值中的平均值和方差,不过训练输入和这些隐藏单元值的一个区别是,你也许不想隐藏单元值必须是平均值0和方差1。
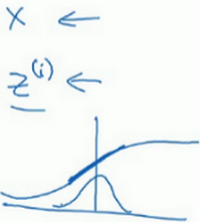
比如,如果你有sigmoid激活函数,你不想让你的值总是全部集中在这里,你想使它们有更大的方差,或不是0的平均值,以便更好的利用非线性的sigmoid函数,而不是使所有的值都集中于这个线性版本中,这就是为什么有了 和 两个参数后,你可以确保所有的 值可以是你想赋予的任意值,或者它的作用是保证隐藏的单元已使均值和方差标准化。那里,均值和方差由两参数控制,即 和 ,学习算法可以设置为任何值,所以它真正的作用是,使隐藏单元值的均值和方差标准化,即 有固定的均值和方差,均值和方差可以是0和1,也可以是其它值,它是由 和 两参数控制的。
我希望你能学会怎样使用Batch归一化,至少就神经网络的单一层而言,在下一个视频中,我会教你如何将Batch归一化与神经网络甚至是深度神经网络相匹配。对于神经网络许多不同层而言,又该如何使它适用,之后,我会告诉你,Batch归一化有助于训练神经网络的原因。所以如果觉得Batch归一化起作用的原因还显得有点神秘,那跟着我走,在接下来的两个视频中,我们会弄清楚。
课程PPT



