一:AutoEncoder基本概念
将输入的比较高维度信息,不管是语音,文字,图像经过encoder转成一个中间状态的向量(也叫做latent code),这是一个低维度的数据,再通过decoder 还原重建成原来的信息的过程。
中间这个向量啊,就是某一种形式的embeeding表示,它最基本的用法就是可以用做其他下游任务的输入。
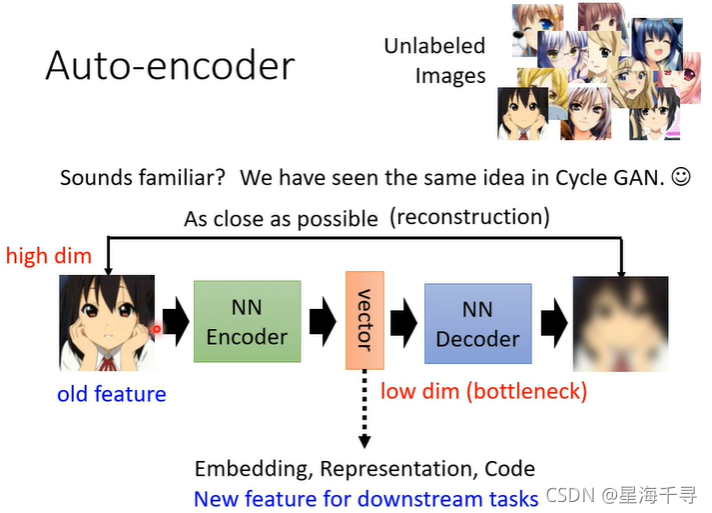
为什么这种方式是可以的呢?
我们虽然输入的图像的表象很多,但是其样式种类可能不是很多哈,比如颜色和纹理等特征,而且维度之间很多冗余和相关的信息,因此很有可能只使用少量的维度数据就可以表示和编码这个高维数据了。

它有一个常见的变形,就是De-nosing Auto-Endocoder,就是给原始信息加上噪声,这个时候decoder需要学习到去掉噪声后的信息。

当然除了做下游任务以外,还可以有有一些其他好玩的方向。
二:Feature Disentanglement(特征分解)
当图像输入到encoder,latent code包含了图像的物体信息,颜色信息,和纹理信息等。
当语音输入到encoder,latent code包含了语音的内容信息,音频信息,和语者信息等。
当文字输入到encoder,latent code包含了文本的语法信息,和语义信息等。

但是这些信息都是杂糅在一个向量一起的,我们有没办法知道哪些维度是代表了什么资讯呢?要搞清楚哪些维度代表了什么信息,这个技术就是Feature Disentanglement。
代表的论文如图所示:

这个有什么用处呢?比如可以做语音转换。简单来来说呢就是能一个人的语音latentcode按照自己想要的部分和另一个人的语音latentcode的其他部分结合起来,或者多个混杂随便组合,就能产生出不一样的信息出来。

三:Dicrete Latent Repesentation
到目前为止,我们可能印象就是latentcode是一串浮点数啊啥的。现在也许latentcode会是被强制成为二进制的序列,也或者是one-hot向量哦。
二进制序列的好处就是,某一个维度可能就是明确代表了某个特征的有无,简单明了。
one-hot向量就是明确这个物体的种类,可以做到非监督的分类,比如文字数字识别的分类。

四:其他更多的运用场景
latentcode还可以是文字,比如做文章的摘要提取,如下结构所示。

一个autoencoder在训练出来后,除了得到encoder,还有一个就是decoder。它就是GAN里面的generator的功能啊。

除了以上,还可以做压缩的功能,不过呢会是有损压缩。

还可以做异常检测,我们通常只能获得正常的信息,异常的信息很少或者几乎获取不到,且千奇百怪,怎么能运用AE来做异常检测呢?在机器学习的部分我们学习到的是通过比较信息维度的相似度,各种方法啊,比如建立正常信息高斯分布,求新信息的分布概率。
那么AE所能做的就是将高维特征压缩到低维度的latentcode,通过比较latentcode的相似度来做异常点检测了。
这个要比监督学习的二元分类要好的地方就是,不用通过获得异常点的数据即可。