注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录
一、快速排序的历史渊源
快速排序是排序算法中应用最广泛,最出名的一个算法。它诞生于1960年,首次被英国计算机科学家霍尔 (Sir Charles Antony Richard Hoare) 发现。其发现紧随shell排序之后,成为又一个突破\(O(N^2)\)的算法,但是因为其独树一帜的复杂度分析方式,让其成为一个高级排序算法,并且不断影响后世,成为了众多高级语言库自带的算法,同时其采用的双指针思维也不断推动着更多类似思想的算法的孕育。
· 霍尔与快速排序
霍尔出生于斯里兰卡,1956年毕业于牛津大学。然后的两年里他服役于英国皇家海军,因为当时的时代背景,霍尔的主要的重心就投入到俄国的现代军事的研究,也自然他开始接触俄语。之后在他结束服役后,他便以研究生的身份进入莫斯科大学主攻计算机翻译,这个过程中他与俄国的机器翻译专家相识,还在“机器翻译”(Machine Translation) 上发表过论文,可以说霍尔在机器翻译上也颇有建树。

上个世纪60年代,英国国家物理实验室 (National Physical Laboratory) 开始了一项将俄文自动翻译成英文新的计划。而霍尔因为在俄语以及机器翻译上的建树,自然而然也被选中并且参与其中。
在那个计算机早期年代,数据的存储并没有像如今遍历。当时俄文到英文的词汇列表是以字母顺序存储在一条长长的磁带上的。因此,当有一段俄文句子需要翻译时,第一步是把这个句子的词按照同样的顺序排列,这样机器就可以在磁带上只走一遍就可以找到所有的翻译。霍尔意识到,他必须找出一种能在计算机上实现的排序的算法来。
他想到的第一个算法是后人称作“ 冒泡排序 ”的算法。虽然他没有声明这个算法是他发明的,但他显然是独自得到这个算法的,但是很快因为其糟糕的\(O(N^2)\)效率将其放弃了。而后其通过冒泡的元素交换得到启发,提出了快速排序的实现,这个是霍尔想到的第二个算法,这个算法的计算复杂度是 \(O(NlogN)\),显然要比冒泡好多了。他却不知道,这个不经意为机器翻译而配套的辅助算法却深刻改变了排序算法的规则,成为第一个引入\(O(logN)\)的排序算法,至此彻底撕开了\(O(N^2)\)排序算法时代的遮羞布,并且快排也以本身内核的奇妙与对其他算法思想的贡献,一下荣升为20世纪最伟大的十大算法之一,同时霍尔他本人也被称为影响算法世界的十位大师之一(著名的霍尔逻辑也是出自这位大师之手,这是他对于计算机语言和数理逻辑的又一大贡献)并于1980年获得图灵奖。
(上述内容参考文章如下,若有侵权请联系我,我立即修改)
科学网—霍尔和快速排序法 - 蒋迅的博文 快速排序算法的发明者霍尔_多米学算法的博客-CSDN博客_冒泡排序是谁发明的
二、快速排序的内在逻辑
快速排序使用的双指针的技巧。这个技巧是处理线性结构的一个利器,通过构造首位指针,并且维护特定指针的特性,然后令两个指针向中心收束(有的双指针还可以采用间隔地同方向递进以构造类似于滑动窗口的特性)从而来实现数据处理的工作。
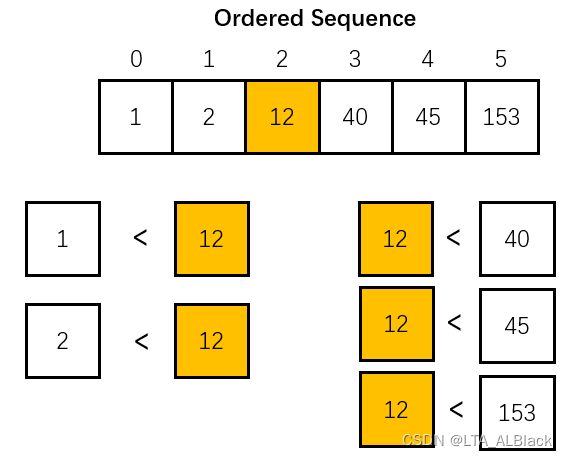
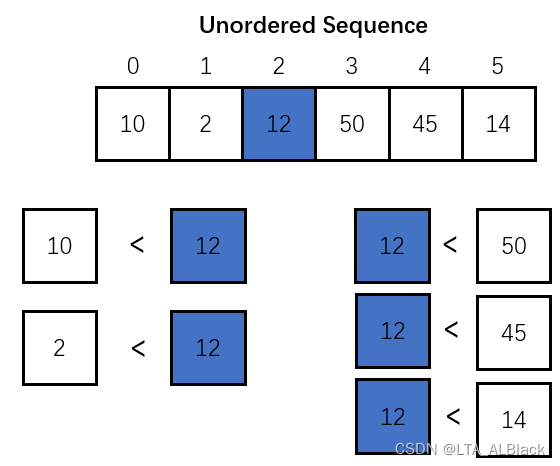
任何一个非递减的有序数组都有一个非常鲜明的特征,就是任意取一个不包含两端的下标\(i(0<i<n-1)\)都有\(L[k] ≤ L[i] ≤ L[j] (0 ≤ k < i < j ≤ n-1)\)。简单来说就是这个数组中任何一个元素的右边都比其小或者等于,而任何一个右边元素都比其大。这个理论其实可以细细品味下,从非递减的有序数组得到这个结论是个充分条件,但是并不是说只要存在一个元素,这个元素左侧都比其小或等于,右侧都比其大或者等那么这整个数组都是非递减有序的(见下图)。而是需要扩大条件为:说只要任意一个元素都能满足这样的条件,那么就可以能证明原数组是非递减有序的了(见上图)。
因此快排的思路就出现了,我们把构造一个有序的数组的操作分治为若干次构造针对下标为\(i\)元素的特殊数组的操作,这个特殊数组里,任何下标小于\(i\)的元素都比其小或等于,任何下标大于\(i\)的元素都比其大或者等于。而每次分治的下标\(i\)总不同。这样,只要分治\(n\)次似乎就能构造出,一个满足任意一个元素都能左小右大的数组,即有序数组!
这里有个疑问。双指针构造一个针对某个元素左小右大的数组需要复杂度为\(O(N)\),而要针对每个\(n\)元素都使用这个方法,那么我们的复杂度不还是\(O(N^2)\)吗?非也!“ 要针对每个\(n\)元素都使用这个方法 ” 这个说法是不准确的,因为在一个数组中,构造出\(i\)元素之前的\(i\)个元素都比它小的时候,若再在\([0,i-1]\)的这个范围内选择一个下标为\(k\)的元素,以其为标准构造一个左小右大的数组时,我们可以发现这时整个\([0,n-1]\)范围内的全部元素中的\([i,n-1]\)部分都已经比他大了,因为这部分数据在对下标为\(i\)的元素进行双指针调整时已经优化过了,再对这部分进行调整就显得多此一举了!所以我们可以采用分段递归!。以下标为\(k\)的元素为标准构造一个左小右大的数组时只需要选择范围\([0,i-1]\)就好了。(见下图)
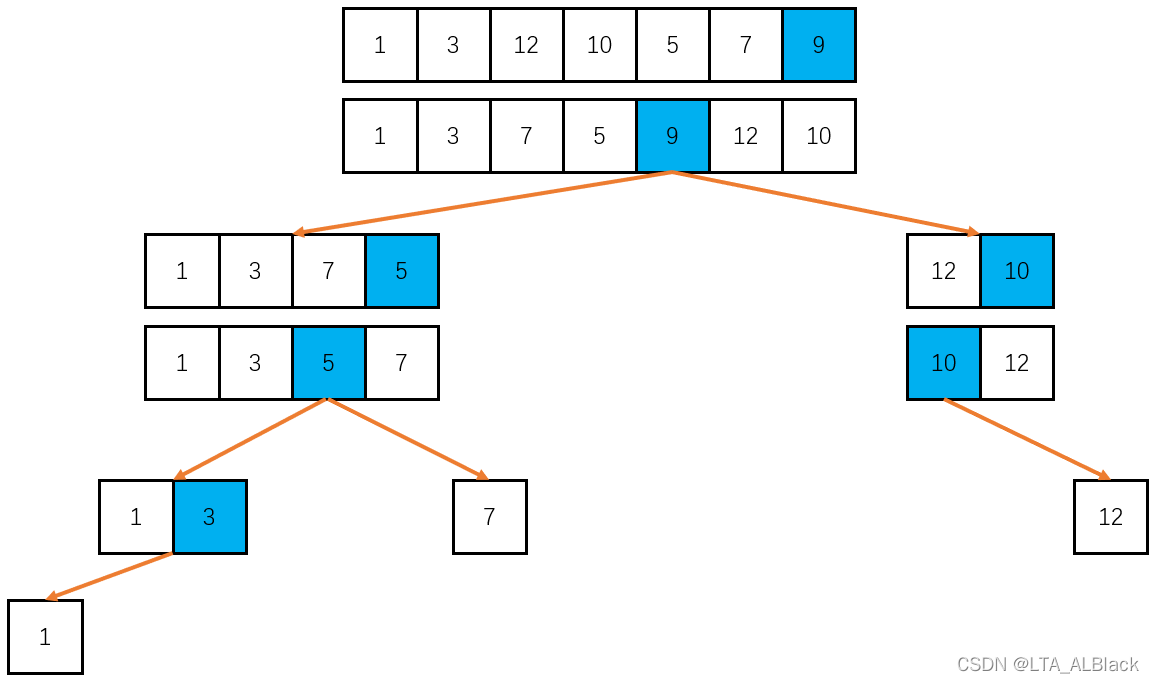
每次采用双指针构造时都特定地选择一个枢轴(Pivot),然后双指针以这个枢轴为基准进行构造,构造一个以这个枢轴元素为标准的左大右小的数组,然后把枢轴放于这个左大右小元素的中央。之后把枢轴左边的序列分裂出去单独讨论,右边部分也分裂出去单独讨论。而着每个单独讨论都是上述操作的重复,因此这里就构成同等规模操作的重现,典型得不能再典型的递归 (๑•̀ㅂ•́)و✧。当我们的数组被分割得只有一个时,操作结束!
近似地,只有同层各分段合并后复杂度才会近似\(O(N)\),底部某些层次似乎明显很难达到\(O(N)\)复杂度。同时,只要原序列足够混乱,那么这个这个枢轴最终基本能稳定在中央,那么这个线性表就可以尽可能地二分拆分,通过我们之前讲的折半二分的判定树高度特点,快排的递归树空间复杂度量级也能基本稳定在\(O(logN)\)。所以我们得出,总的平均复杂度可以保持在\(O(NlogN)\),自然地,最佳复杂度(完全逆序:递归树是完美的二分判定树)也是如此。
而最糟糕的复杂度往往出现在基本有序并且枢轴选择不当时,例如下面这个情况:

虽然整体已经有序,但是我们还是会逐个使用双指针去调整数组,去调整枢轴,这就导致我们的递归树呈现\(O(N)\)的空间复杂度,从而导致整体的排序接近\(O(N^2)\)。可见,快排也不是我们所理解的绝对意义上的 “ 最快的排序 ”,他还是有吃瘪的时候。
三、双指针实现快速细节与代码
刚刚上面我们将双指针实现的细节一带而过了,只说了其复杂度为\(O(N)\)。其实快排的双指针实现的代码并不是唯一的,每个人都有自己的实现方法,所以我打算将双指针结合我自己程序的代码来讲解,这样能更好地去理解。
快排具有鲜明的范围特征,这也是使用双指针的先决条件,因此在本轮讨论开始时,一旦排序的首位指针重叠或者错位了提前退出。这个条件判断保证了在快排分段递归进行到只有一个元素时能提前退出。
// Nothing to sort.
if (paraStart >= paraEnd) {
return;
} // Of if本代码为了简单没有设计自适应枢轴,而是默认采用最后元素即枢轴的简易操作,其实这样基本的枢轴对于大多数普遍混乱的数据来说已经有比较好的复杂度适应性了。
int tempPivot = data[paraEnd].key;
DataNode tempNodeForSwap;
int tempLeft = paraStart;
int tempRight = paraEnd - 1;同时确定了双指针的位置,如图:
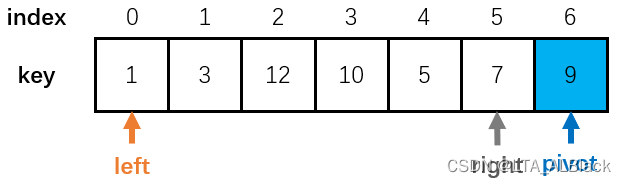
然后就是指针挪动的代码部分,left指针不断向右(left++)移动,直到遇到了一个大于或等于枢轴的元素,或者提前碰到了right指针,便停下来。然后right指针不断向左(right--)移动,直到遇到了一个小于枢轴的元素,或者提前碰到了left指针,便停下来。之后,交换这两个指针的内容,因为right指针要维护右侧元素大于枢轴,因此遇到了小的元素要停下来,并与此刻定然是比枢轴大的left指针指向的内容交换;而left指针也是持有这样类似的思想,彼有吾之所需,吾有彼之所要。
// Find the position for the pivot.
// At the same time move smaller elements to the left and bigger one to the
// right.
while (true) {
while ((data[tempLeft].key < tempPivot) && (tempLeft < tempRight)) {
tempLeft++;
} // Of while
while ((data[tempRight].key >= tempPivot) && (tempLeft < tempRight)) {
tempRight--;
} // Of while
if (tempLeft < tempRight) {
// Swap.
System.out.println("Swapping " + tempLeft + " and " + tempRight);
tempNodeForSwap = data[tempLeft];
data[tempLeft] = data[tempRight];
data[tempRight] = tempNodeForSwap;
} else {
break;
} // Of if
} // Of while交换的过程:
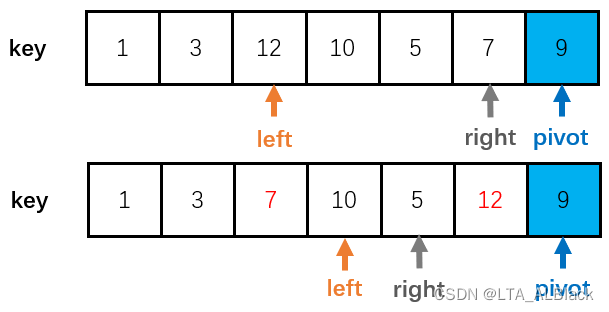
最终我们的代码在遇到left与right相同时便退出while循环,这个时候left指向的元素可能比pivot大也可能比pivot小,于是分情况讨论:
// Swap
if (data[tempLeft].key > tempPivot) {
tempNodeForSwap = data[paraEnd];
data[paraEnd] = data[tempLeft];
data[tempLeft] = tempNodeForSwap;
} else {
tempLeft++;
} // Of if
System.out.print("From " + paraStart + " to " + paraEnd + ": ");
System.out.println(this);
quickSortRecursive(paraStart, tempLeft - 1);
quickSortRecursive(tempLeft + 1, paraEnd);一般来说结束时right与left共同指的元素比pivot大,为何呢?
1). 因为我们的代码是left先移动,right后移动。一旦left先动并且相遇right了,这个时候right一般来说比pivot大(因为本回合right还没移动,这个时候right指向的空间是上回合交换后的残余,那么既然交换过了,right值的空间内的数据肯定比pivot大,试着体会下)
2). 若是right后移动并与left相遇了,这时候left已经移动完了,那么left一定移动到一个大于pivot的元素上,因为这是left指针停下来的标志。
因此面对这样的结果,我们总是交换枢轴元素与left\right指针指向的元素,保证左小右大,如下:
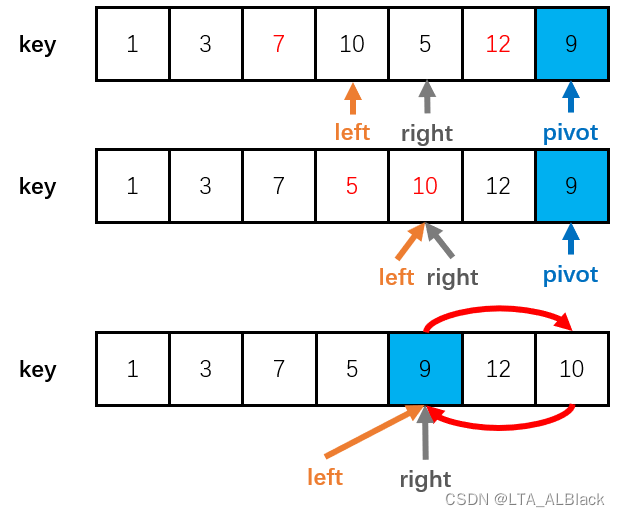
那么,就没有结束时right与left共同指的元素比pivot小吗?有的!
1). 第一回合,一旦left先动并且相遇right了,这个时候right没有上回合移动的残留,所以其本身值是多少完全是随机的,所以这个时候left与right相遇的共同指向元素的值也是随机的,所以其结果可能比pivot小。
遇到这种情况不用交换就好了,这里让left指针右移是为后续的递归的范围重新划定考虑的,因为这种情况出现的话,只有左侧递归,没有右侧递归。
最后我们给出左侧递归的最后几部模拟:
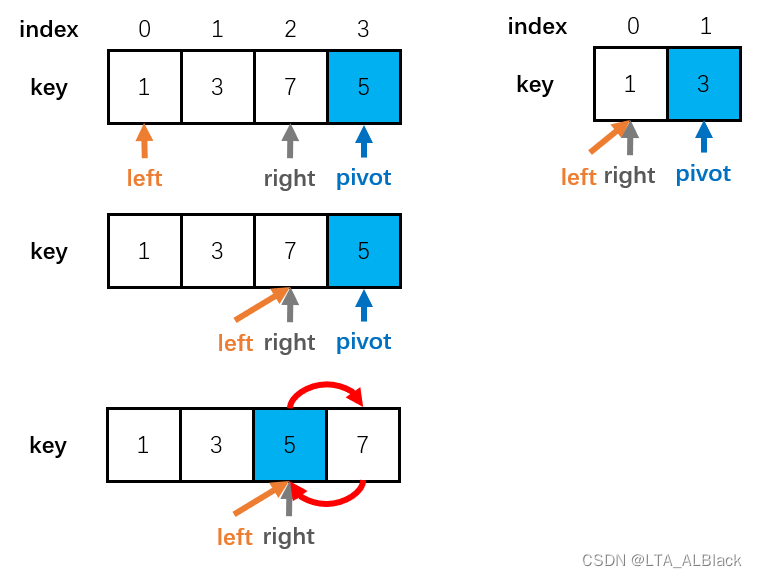
全部代码:
/**
*********************
* Quick sort recursively.
*
* @param paraStart The start index.
* @param paraEnd The end index.
*********************
*/
public void quickSortRecursive(int paraStart, int paraEnd) {
// Nothing to sort.
if (paraStart >= paraEnd) {
return;
} // Of if
int tempPivot = data[paraEnd].key;
DataNode tempNodeForSwap;
int tempLeft = paraStart;
int tempRight = paraEnd - 1;
// Find the position for the pivot.
// At the same time move smaller elements to the left and bigger one to the
// right.
while (true) {
while ((data[tempLeft].key < tempPivot) && (tempLeft < tempRight)) {
tempLeft++;
} // Of while
while ((data[tempRight].key >= tempPivot) && (tempLeft < tempRight)) {
tempRight--;
} // Of while
if (tempLeft < tempRight) {
// Swap.
System.out.println("Swapping " + tempLeft + " and " + tempRight);
tempNodeForSwap = data[tempLeft];
data[tempLeft] = data[tempRight];
data[tempRight] = tempNodeForSwap;
} else {
break;
} // Of if
} // Of while
// Swap
if (data[tempLeft].key > tempPivot) {
tempNodeForSwap = data[paraEnd];
data[paraEnd] = data[tempLeft];
data[tempLeft] = tempNodeForSwap;
} else {
tempLeft++;
} // Of if
System.out.print("From " + paraStart + " to " + paraEnd + ": ");
System.out.println(this);
quickSortRecursive(paraStart, tempLeft - 1);
quickSortRecursive(tempLeft + 1, paraEnd);
}// Of quickSortRecursive
/**
*********************
* Quick sort.
*********************
*/
public void quickSort() {
quickSortRecursive(0, length - 1);
}// Of quickSort
/**
*********************
* Test the method.
*********************
*/
public static void quickSortTest() {
int[] tempUnsortedKeys = { 1, 3, 12, 10, 5, 7, 9 };
String[] tempContents = { "if", "then", "else", "switch", "case", "for", "while" };
DataArray tempDataArray = new DataArray(tempUnsortedKeys, tempContents);
System.out.println(tempDataArray);
tempDataArray.quickSort();
System.out.println("Result\r\n" + tempDataArray);
}// Of quickSortTest测试结果:

· 针对本代码的特殊细节
这里要注意,两个指针挪动的while判定语句中,我们必须要求某个指针遇到相同元素后跳过,而另一个遇到相同元素不跳过;再或者两个指针遇到相同元素都跳过。为何要这样规定?我们看下面这个情况,假如说,我们要求左右指针遇到相同元素都不跳过,需要停下来,完成交换
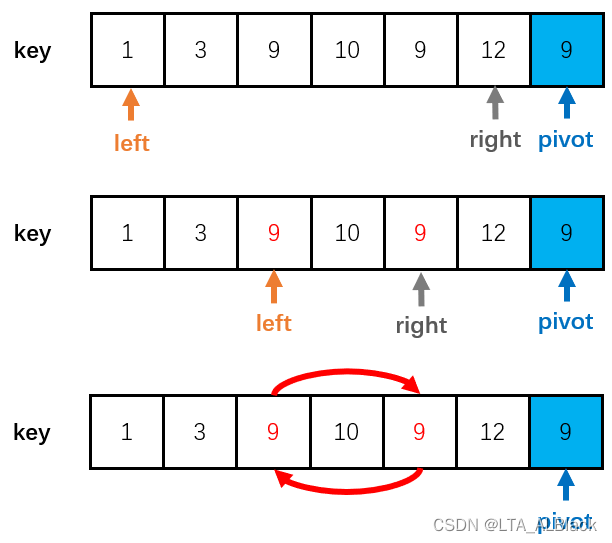
那么就会出现一个尴尬情况,上面的下标为2的元素与下标为4的两个9会发生一次交换,但是我们代码中没有交换后的强行指针挪动的代码,而是交给下一回合因为交换后,left与right指向内容不满足自身停下来的条件而导致的条件判断时“ 必然发生指针挪动 ”的机制完成的,这个机制实现的基础就在于left停下来的条件对于right来说必须是不能停下来的,对于right来说也是同理。一旦要求两个指针遇到相同于pivot的值便停下来,这种机制似乎就失效了,因为交换后......什么都没改变,和交换前一模一样,那么下回合它们会怎么做?再交换......那再下一回合呢?再交换......于是就死循环了。
所以可以保证合理的代码只能是下面三种:
while ((data[tempLeft].key < tempPivot) && (tempLeft < tempRight)) {
tempLeft++;
} // Of while
while ((data[tempRight].key >= tempPivot) && (tempLeft < tempRight)) {
tempRight--;
} // Of while while ((data[tempLeft].key <= tempPivot) && (tempLeft < tempRight)) {
tempLeft++;
} // Of while
while ((data[tempRight].key > tempPivot) && (tempLeft < tempRight)) {
tempRight--;
} // Of while while ((data[tempLeft].key <= tempPivot) && (tempLeft < tempRight)) {
tempLeft++;
} // Of while
while ((data[tempRight].key >= tempPivot) && (tempLeft < tempRight)) {
tempRight--;
} // Of while最后这个代码直接避开了取等停下来这个恶心的条件,也是可以的。
上面分析的情况只是针对本代码的细节,采用其他的快排代码可能不会有这个问题。这个问题不具有一般性,请注意。
性能与特性分析
关于复杂度的来历以及糟糕情况的原因在上面已经讲过原因了,这里列出定义和结论即可:
快速排序的空间复杂度针对递归栈的深度而定,空间复杂度最好是\(O(logN)\),最差是\(O(N)\),这个情况视pivot的选定与数组最初情况而定,当数组基本有序时,递归栈接近最糟糕的\(O(N)\),当基本无需时效果会好些,当完全逆序时递归栈是最完美的\(O(logN)\)。快排的总体时间复杂度的优劣受空间复杂度而定,每层的操作的时间复杂度接近\(O(N)\),因此,快排最佳时间复杂度为\(O(NlogN)\),最差复杂度是\(O(N^2)\)。而每层的操作的时间复杂度往往只是接近\(O(N)\),因此平均复杂度可以基本稳定在\(O(NlogN)\)。
同时,快排是个不稳定的算法,因为双指针的移动有不确定性;快排一般对于顺序表适用,但是理论上链表也能适用,因为其采用的双指针双向移动可以用链表指针模拟,但是一般来说:单链表难以实现,双链表相对方便,但是还是远不如顺序表来得便利;当于排序中途停下来观察数组,这时那些被选为枢轴的元素所在的下标就是排序结束后其最终位置,除此之外,其余元素无法确定。
总结
快速排序可以是说是排序当中的明星了,因为我们在遇到大型排序问题的时候,总会试着先尝试用快排去解决。在高级排序大家族里面,论递归,快排不会像归并那样疯狂开销空间以及频繁地复制元素造成时间开销;相比于堆排,不会存在建堆打乱数据原有的相对选择顺序,导致数据有序度降低,没有频繁的比较与交换造成开销;在处理数据量足够大且足够混乱的数据时,相比于简单排序,快排更是碾压级别的。这些优势使得它坐实了“ 快速 ”排序的名号。
当然,算法各有优劣,没有谁是完全一家独大的。快排优势确实很大,但是也要量体裁衣,具体问题具体分析,快排吃瘪也不在少数。要论外部排序,快排作为内部排序肯定没法胜任,而归并这个内外排序都能兼顾的\(O(NlogN)\)级佼佼者就有风头了。在元素动态变化的有序序列中,快排似乎就在堆排面前完全败下挣来,堆排不仅在最初排序时参与,在后续添加元素的时时刻刻都参与其中,提过时时刻刻\(O(logN)\)修改复杂度,而快排只能在数组建立之初参与,之后的数组维护方面根本无法参与。当然这些是其次,快排最大的吃瘪还是当我们的元素基本有序时,快排的效率甚至不及大多数简单排序。
所以说,我们为什么要了解各种各样的排序?因为,不存在某个真正厉害的排序,而是总存在最合适于问题的排序。