注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录
3+4、比较分析各种排序算法与描述各种排序算法的特点和基本思想
1、比较分析各种查找算法
查找算法基本上是基于线性结构的查找、树形查找、哈希查找。
线性查找分为:
- 基于一般线性表的顺序查找:在一个无序的线性表当中查找某个特定元素,基本的时间复杂度是\(O(N)\),利用哨兵发权衡查找路径,可得查找成功的ASL为\(\frac{n+1}{2}\),查找失败的ASL为\(n+1\),平均ASL为\(\frac{n+1}{2}\)。
- 基于有序表的顺序查找:在一个有序的线性表中查找某个特定的元素,并且采用一般的线性检索方案。这种查找在有的算法当中直接并入第一种情况,因为他们的复杂度与效果是类似的\(O(N)\),查找成功与平均的ASL都是\(\frac{n+1}{2}\)。唯一不同是,查找失败是能提前结束而不用遍历到最后,失败ASL为\(\frac{n}{2} + \frac{n}{1+n}\)。(这个失败ASL的计算方案是通过判定树实现的,这里不赘述)
- 基于有序表的二分查找:在一个有序的线性表中查找某个特定的元素,但是采用二分的检索方案。这种查找具有分区域预判能力,能折半地减少不必要的判断,总的时间复杂度能缩小到\(O(logN)\)。查找ASL可以根据具体问题通过构造此线性表的二叉判定树得出,基本的ASL约为\(\left \lceil log_{2}(n+1) \right \rceil \)。
树形查找就是我们查找逻辑与存储上都采用树形结构,主要由索引与B树两大查找方案,B树可以看做是变异版本的索引结构:
- 索引顺序查找(在有序的块间采用顺序查找):索引顺序查找又称分块查找,我们先将顺序表分为若子块,子块之间可以按照块内某个最大元素确定整个块的权,然后块间保存有序而块内无须有序。在查找元素时我们可以先通过有序的分块确定我们目标元素所在的区间,然后再这个区间内查找。这种查找的ASL一般是根据块间查找的策略与块内查找策略共同决定。假若分为\(b\)块,块内有\(s\)个数据项,若在有序的块间采用顺序查找,ASL为\(\frac{b+1}{2}+\frac{s+1}{2}\)。在\(b = s = \sqrt n\),时有最佳ASL为\(\sqrt n + 1\)。
- 索引顺序查找(在有序的块间采用折半查找):本质同上,仅仅改变和块间的查找策略:有序的块间采用二分查找策略,ASL为\(\left \lceil log_{2}(b+1) \right \rceil+\frac{s+1}{2}\)。
- B树:B树能说的内容太多了,放在这里有点喧宾夺主了,简单来说。B树就是一个能实现自平衡的多路平衡树。当B树的阶数确定了,那么这个树的分支与结点的构成方案就唯一确定了;同时B树的每个结点能存储我们的目标信息,叶子节点并不存储信息,其查找的方案类似于平衡树的查找,但是块内的数据不是单独的一个数值,这就导致了它查找的过程又类似于索引的查找,并且上层块都构成了下层块的索引。基本来说查找的ASL是对数级的。
- B+树:B+树基本与B树类似,只不过略有改进,B+树的每个分支结点不再存储有效的记录而是分散到每个叶子节点来存储。同时叶子结点之间有指针连接,使得叶子之间能单独实现顺序存取,因此这个结构的使用更加灵活。
哈希查找不同于上述的所有查找,哈希表彻底改变了查找的策略与规则:
- 哈希表:哈希表通过分析查询的目标值本身的某种含义,从而设计出一种散列函数来构成目标值直接到具体存储位置的映射,从而避免了基于特定线性或者树形逻辑结构的依赖。因此复杂度能基本稳定在强悍的\(O(1)\)。但是哈希表也诞生了其余查找结构所不存在的一些问题,例如,散列函数可能会把两个以上的不同关键词映射到同一个地址,发生冲突。为了避免冲突,我们就需要设置健壮的散列函数与良好的冲突避免策略。总结来看,哈希表的效率受限于三个因素:散列函数的选择、解决冲突的方案、填装因子。
2、设计一个自己的 Hash 函数和一个冲突解决机制
我这里设置一个基于除留取余法的,利用拉链法与平衡树优化的解决冲突的方案。其Hash函数很简单,就是\[H(key) = key \% p\] 这里的\(p\)可以根据需要可以设置为小于等于长度的最小质数,或者就设置为数组长度都可以,这个不是我的设计的重点,重点在于拉链法解决冲突的方案:
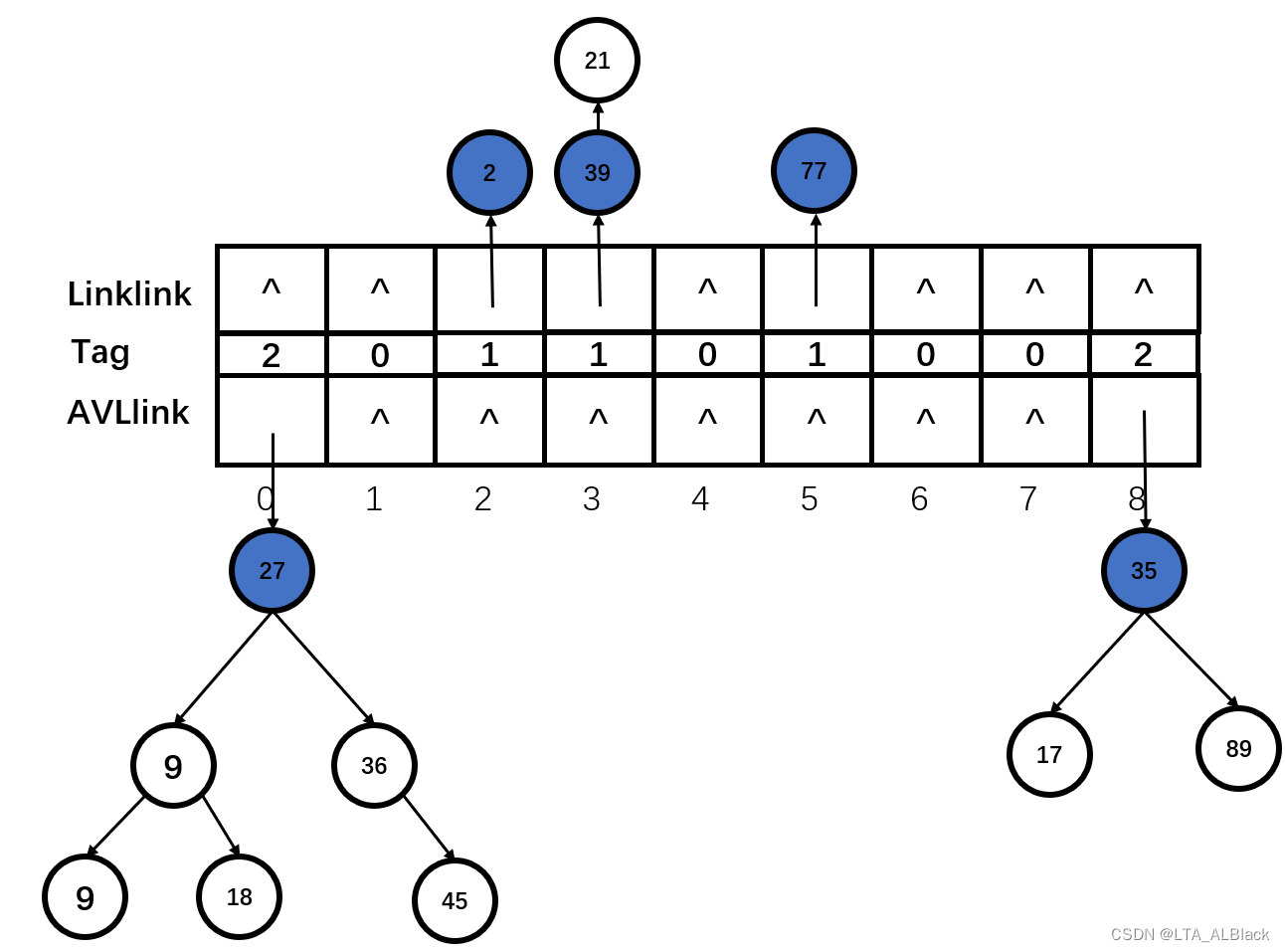
在这个方案里面,哈希表设置为有两个链域的顺序表。具体的数据结构定义如下:
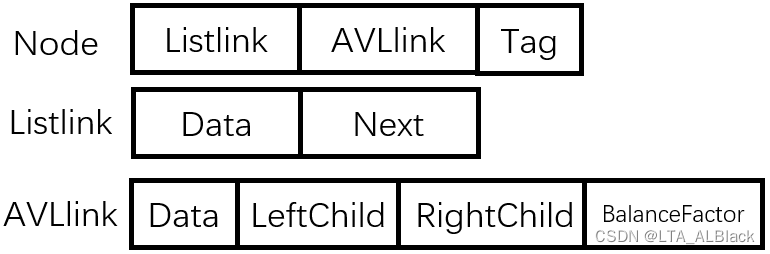
Node结构是我们顺序表的基本结点信息,其中Listlink域为一个线性链表类的指针,指向Listlink类结点构成的链表;而AVLlink域为二叉平衡树(AVL)的结点指针,可以指向一课二叉平衡树;Tag域用于记录当前Node结点的指针使用情况,当Tag = 0时说明没有指针在使用,也说明当前结点没有存放任何数据,是空位置,当Tag = 1是说明当前结点存储的只有线性的链表,当Tag = 2 说明当前存储的只是一颗平衡树。
我如此做的目的是用于解决查找元素时的平均消耗。当我的key通过取余操作后,确定了其存储的下标,若这个下标所在的结点的Tag = 0,那么说明这个位置是空余的,那么我就将我的数据插入链表中,并且修改Tag = 1,复杂度是\(O(1)\);若找到存储下标时观察其结点中的Tag = 1,说明发生了冲突,且此结点使用的链表存储同义词,于是将数据前插到链表中,复杂度为\(O(1)\);若找到存储下标时观察其结点中的Tag = 2,说明采用是AVL存储同义词,于是将数据存入AVL,平均复杂度为\(O(logN)\)。可见这样操作处理冲突的复杂度是非常低的,几乎是常数级别的。
查找元素时,虽然两种存储的时间复杂度分别是\(O(N)\)与\(O(logN)\),但是我们的策略决定了这个过程最终的复杂度不会很夸张。最开始虽然我们采用链表来保存这些同义词,但当同义词比较多时,我们会重构这条链表,将其变为一颗AVL然后挂载到AVL域内,并且删除原来的链表。因此查找元素如果遇到了链表存储,虽然复杂度是\(O(N)\),但是这个\(N\)并非是一个变量。例如当我们设定常数\(k\),当\(N>k\)时我们将其转换为AVL存储,这样的话我们关于链表查找的复杂度其实可以平均表示为\(O(k)\),理论上属于常数级别复杂度。就算某一个结点的同义词过多,我们也采用的是AVL存储,其\(O(logN)\)的复杂度的查找也是可接受的(除留余数法的\(p\)选择如若得当。那么元素彼此是能足够分散的,所以某几个结点元素过于集中的情况不会特别频繁地发生)。
总的来看,我的这种方案在略微牺牲传统拉链法插入元素的复杂度,换得了查找元素的整体效率。种这种根据数据个数调整数据结构的方式并不少见,Java内置的哈希表结构就用了类似的思路。
3+4、比较分析各种排序算法与描述各种排序算法的特点和基本思想
我将从下面几个指标来比较本科阶段接触的基础数据结构中的排序算法:
- 空间复杂度
- 时间复杂度
- 稳定性
- 最佳与最差情况
- 适用性
- 排序中途观察,是否可以确定一些元素的最终位置
- 其他特性
这些指标在我43天~49天的博客中的性能与特性分析部分有详解,还有一些算法特有的小特性可以详见具体博客。
关于复杂度:
| 算法 | 空间复杂度 | 最好时间复杂度 | 最差时间复杂度 | 平均时间复杂度 |
| 直接插入排序 | \(O(1)\) | 有序时\(O(N)\) | 逆序时\(O(N^2)\) | \(O(N^2)\) |
| 希尔排序 | \(O(1)\) | 优于\(O(N^2)\) | \(O(N^2)\) | 优于\(O(N^2)\) |
| 冒泡排序 | \(O(1)\) | 有序时\(O(N)\) (单趟发现全有序提前结束) | \(O(N^2)\)(逆序时要比较\(\frac{n(n-1)}{2}\)次) | \(O(N^2)\) |
| 快速排序 | 最好\(O(logN)\) 最差\(O(N)\) (取决于栈的深度) |
\(O(NlogN)\)(取决于栈的深度) | \(O(N^2)\)(取决于栈的深度) | \(O(NlogN)\) |
| 简单选择排序 | \(O(1)\) | \(O(N^2)\) 永远比较\(\frac{n(n-1)}{2}\)次 |
||
| 堆排序 | \(O(1)\) | \(O(NlogN)\) | ||
| 归并排序 | \(O(N)\) | \(O(NlogN)\) | ||
关于其他指标:
| 算法 | 稳定性 | 最好与最坏效果 | 适用性 | 排序中途观察,是否可以确定一些元素的最终位置 |
| 直接插入排序 | 稳定 | 整体基本有序时效果最好 | 顺序存储与链式存储都适用 | 无法确定 |
| 希尔排序 | 不稳定 | 选择较好的增量序列后有较好效果 | 顺序存储 | 无法确定 |
| 冒泡排序 | 稳定 | 整体基本有序时效果最好 | 顺序存储与链式存储都适用 | 可以确定 |
| 快速排序 | 不稳定 | 整体基本有序时 如果选取pivot不当效果最差 整体顺序随机时效果最好 |
适用于顺序表,理论上可以用链表实现但非常麻烦 | 可以确定一次划分时选取的pivot值的位置 |
| 简单选择排序 | 不稳定 | 排序效果与初始状态无关 效果永恒 |
顺序存储与链式存储都适用 | 可以确定 |
| 堆排序 | 不稳定 | 排序效果与初始状态无关 效果永恒 |
顺序存储 | 可以确定 |
| 归并排序 | 稳定 | 排序效果与初始状态无关 效果永恒 |
顺序存储与链式存储都适用 | 无法确定 |
关于算法的思想:
- 直接插入排序:利用了线性表的插入思想。
- 希尔排序:利用线性表的插入思想,同时也利用了直接插入排序在元素基本有序时的高效率等特性。
- 冒泡排序:利用了并列元素交换的传递性,以及无序序列到有序序列转换的思想。
- 快速排序:利用分治的思想,双指针的思想,递归思想。
- 简单选择排序:擂台思想,以及无序序列到有序序列转换的思想。
- 堆排序:堆思想,线性结构抽象为逻辑树的下标映射思想,无序序列到有序序列转换的思想。
- 归并排序:利用了分治思想,有序序列合并思想。