注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录
一、关于哈希表
哈希表,有时又可以称之为散列表。这种结构是查询中人们最喜欢看见的结构,因为其可以实现任何查询操作都无法比拟的\(O(1)\)复杂度查询速度,是对于查询优化的最高境界。现在随着许多语言都逐渐配备哈希相关的库结构,很多高阶算法的哈希优化已经从如何设计散列函数上升到如何设计哈希映射的规则已经怎么使用哈希表。但是重新回到设计散列函数的视角,重细节之处看哈希表是如何实现\(O(1)\)的时间复杂度。
所谓哈希表其实一种基于算术形成的映射规则,其本质来说是一种顺序表或者基于顺序表的混合结构。为何总有顺序表?因为哈希的\(O(1)\)就其本质是利用了顺序表的\(O(1)\)随机存取。
哈希表通过分析查询的目标值本身的某种含义,从而设计出一种散列函数来辅助确定这个目标值的存储下标或者广义上说在顺序表中的位置,从而直接利用顺序表的\(O(1)\)随机存储天赋对数据直接访问。这其中,“ 用散列函数来辅助确定这个目标值的存储下标 ”是算法的关键和核心开销。往往来说,在这个过程中会因为一些随机情况导致复杂度的抬升,因为函数计算出的值往往会因为映射的重叠性导致冲突(注:散列函数可能会把两个以上的不同关键词映射到同一个地址,这就是冲突的发送)。一方面,一旦散列函数设计不合理,会导致这种冲突加剧,极大影响哈希表\(O(1)\)的存取效果,另一方面,我们会设计一系列冲突避免的方案来避免冲突,挽救效率。
二、散列函数与冲突的避免策略
今天讲的散列函数大多数可能是我们数据结构基础教材上都提过的基础的、较通用办法,当然还有许多更高阶的散列方案。散列函数的设计方案可以针对不同问题提出更具有具体针对性的改进方向,所以,不要局限于下面我的讲述,合理的散列函数设计是一个复杂且需要经验、思维的复杂高阶的问题。
1.散列函数:直接定址法
最简单的散列函数是直接定址法。在这类方法中,我们的关键字存储数据集往往是连续的,因此我们也直接将其依次存放于连续的顺序表中。这类关键字与存储地址的差额一定是个定值,因此,通过简单的加减就可以完成关键字与存储地址的转换。
这个过程类似于操作系统的静态重定位的装入策略、相对地址到绝对地址的转换。在实际的编程中,我们也常用这种方法,因为这种方法几乎不用对顺序表做过多的改造,例如桶排序算法、ASCII字符到其他类型的映射数组。
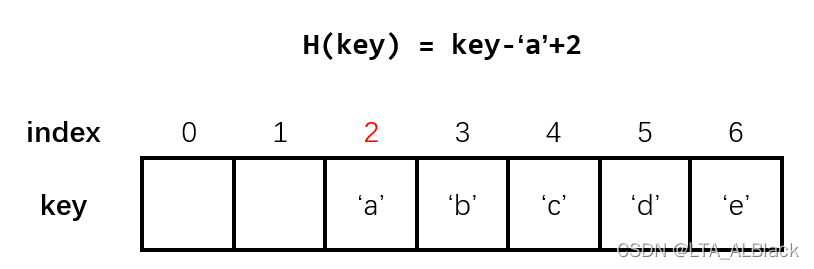
2.散列函数:除留余数法
除留余数法是我们在本科阶段接触的字面或者考试常见的算法,因为这种哈希构造的过程可以通过画图简单模拟出来(所以是个很好的出题点 ┑( ̄Д  ̄)┍)
假定散列表表长为\(m\),取一个不大于表长的数\(m\),利用散列公式:\[H(key)=key\%p\]从而计算出\(key\)值存储的地址\(H(key)\),这种哈希函数一般用于不规则数据集在有限长度的线性结构中的哈希存储。因为取模实现了长度范围内的值能与位置的同名存储,大于范围实现周期性地存储,限制了数据的扩大与分散。通过数论中的某些观点,这里用于取模的\(p\)采用质数最宜,因为质数取模具有分部更均匀的特性。
今天我们的代码就从除留余数法出发分析。
3.最简单的冲突避免:开放定址法
当我们通过散列函数计算确定了当前关键字的预定存储位置,结果发现此存储位置已经存在元素,那么我们就要处理冲突了,即确定当前这关键字真正的存储位置到底在哪。
“ 此地不留爷,只有留爷处 ”。最常见的思路就是开放定制法,也就是换位置。开放定制法最简单的一种换位置的思路就是线性探测,即遇到冲突便不断向前增加自己的下标,从而探测当前新下标是否能存储,若增加到边缘则通过取余回到第一个位置继续向前探测。如此一来哪怕冲突发生,只要当前哈希存储空间够大,那我们的数据总能找到存储位置,但这就只是一个时间问题了。(下图给出除留余数法的哈希函数\(H(key)=key\%19\)在运行过程中遇到冲突的处理过程)
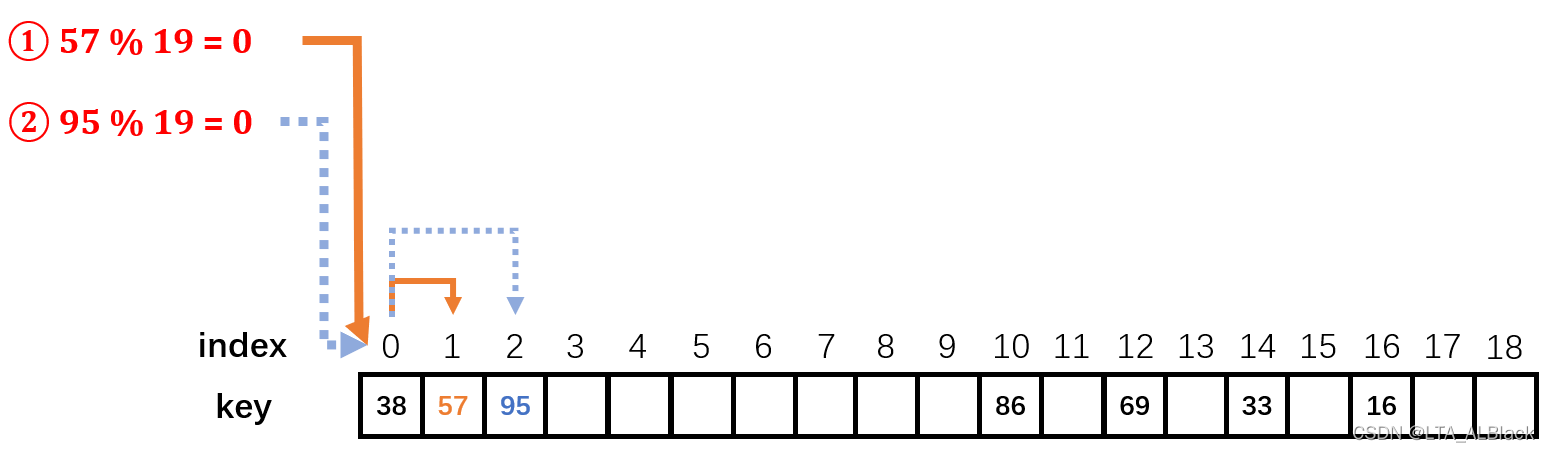
当然这样简单的冲突避免也存在很多问题,比如线性探测导致了冲突的数据往往集中存放在冲突点的周围,这就导致了关键字及其同义词(通过散列函数会映射到同一个的两个关键词)集中堆放,这将导致此关键字周围的数据冲突频发而且一旦发生就需要移动许多次下标来确定新位置。所以我们往往也会采用与以太网的CSMA/CD中避免冲突的二进制退避算法所类似的平方探测法来增大离散程度,或者为散列结果再设计一个散列函数的再散列法来提高数据的不稳定性,或者索性将可能性完全交给伪随机,采用伪随机数法来提高数据的随机性。
4.完美的冲突避免:拉链法
第二种思路就是不拘于一位的线性思维,而是扩展我们的视野到二维(这种一维到二维的创新让我想到了当年数学家们创新性地将虚数与一维数轴结合从而发现虚数的二维特性的例子)。
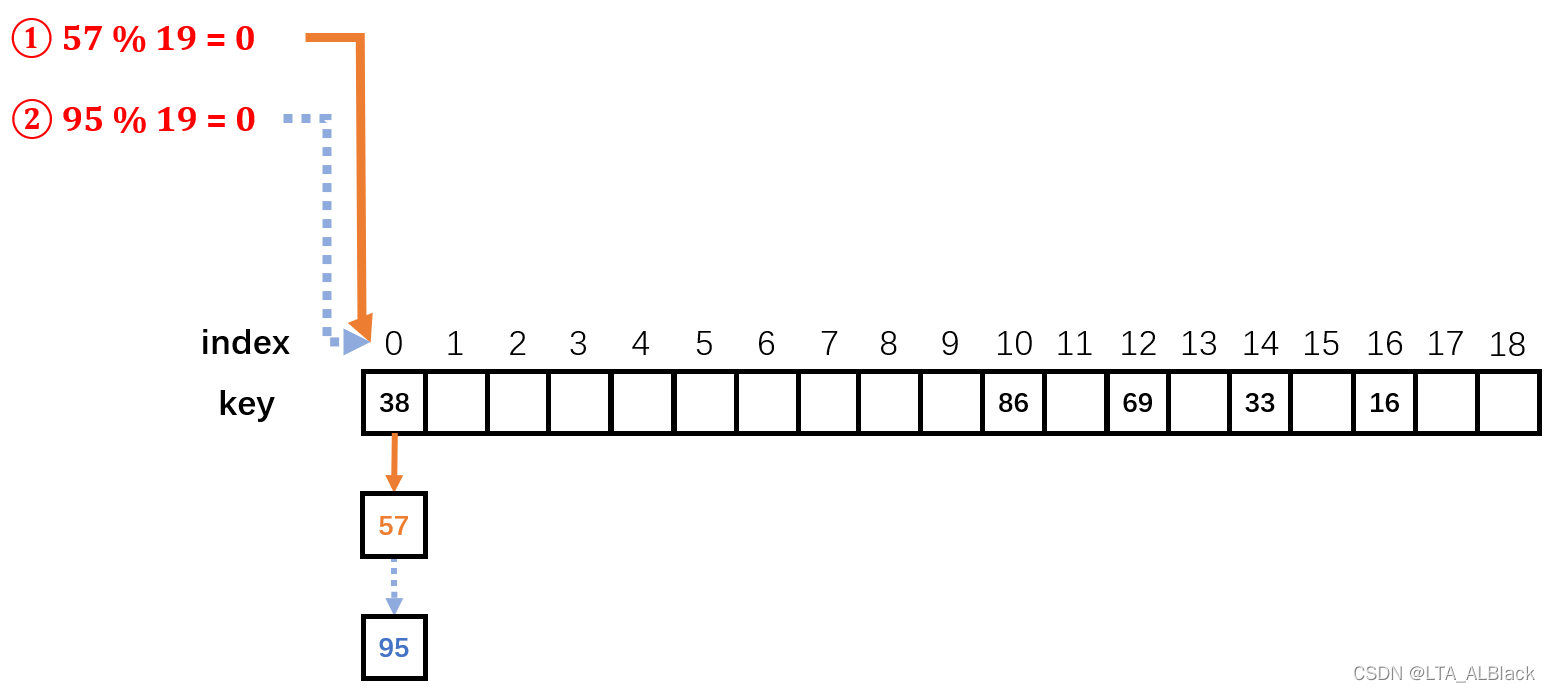
当冲突在一个位置\(i\)上发生的时候,我们可以将此冲突的同义词链到此位置\(i\)而延展出来的同一条链上。为了优化存储哈希表过程的时间复杂度开销,可以用头插法将新同义词插入到链表中,从而保证\(O(1)\)复杂度的插入。这也是目前所属的解决冲突方法中唯一一个能实现哈希表创建时的单个元素插入的绝对\(O(1)\)复杂度,因为开放定制法再怎么采用各种办法增加冲突同义词的位置分散性和随机性还是不可避免“ 碰上 ”恰好二次、三次散列冲突的可能性。
三、代码实现基于线性探测冲突避免的除留余数法哈希表
1.哈希表构造
首先是表结构的构造,此操作作为表一切查询的前提,因此采用了构造函数完成。其实懂得了散列函数的思路后,简单的哈希构造代码似乎就是一个非常容易模拟过程,按步完成即可。
/**
*********************
* The second constructor. For Hash code only. It is assumed that
* paraKeyArray.length <= paraLength.
*
* @param paraKeyArray The array of the keys.
* @param paraContentArray The array of contents.
* @param paraLength The space for the Hash table.
*********************
*/
public DataArray(int[] paraKeyArray, String[] paraContentArray, int paraLength) {
// Step 1. Initialize.
length = paraLength;
data = new DataNode[length];
for (int i = 0; i < length; i++) {
data[i] = null;
} // Of for i
// Step 2. Fill the data.
int tempPosition;
for (int i = 0; i < paraKeyArray.length; i++) {
// Hash.
tempPosition = paraKeyArray[i] % paraLength;
// Find an empty position
while (data[tempPosition] != null) {
tempPosition = (tempPosition + 1) % paraLength;
System.out.println("Collision, move forward for key " + paraKeyArray[i]);
} // Of while
data[tempPosition] = new DataNode(paraKeyArray[i], paraContentArray[i]);
} // Of for i
}// Of the second constructor为了鲜明表现部分空间尚未被关键词“ 占据 ”,这里在顺序表中引入了值为null的“ 坏域 ”。初始给整个二元数组data分配了足够长度的连续引用空间,然后填满null,以预示数据尚未载入。
之后遍历用户输入的键值paraKeyArray数组依次载入元素,这个过程中采用散列函数确定存放位置tempPosition。tempPosition确定后尚有可能并非最终位置,采用while进行一个冲突判断并且维持一个线性探测:tempPosition = (tempPosition + 1) % paraLength。
2.哈希表的查询与性能分析
*********************
* Hash search.
*
* @param paraKey The given key.
* @return The content of the key.
*********************
*/
public String hashSearch(int paraKey) {
int tempPosition = paraKey % length;
while (data[tempPosition] != null) {
if (data[tempPosition].key == paraKey) {
return data[tempPosition].content;
} // Of if
System.out.println("Not this one for " + paraKey);
tempPosition = (tempPosition + 1) % length;
} // Of while
return "null";
}// Of hashSearch通过散列函数求得键值Key的下标位置tempPosition,然后使用一个while函数判断是否冲突并且维护冲突的线性探测判断。哈希表的查询操作其实是哈希表建立过程内部的核心子过程,因此在实现过程中可以参照哈希表建立的代码。
这里可以看见哈希表查询的核心时间开销就在这个while循环,但是绝不是说跑这个函数的时间复杂度就是\(O(N)\),如果散列函数设置合理并且冲突处理后的元素位置得当的话,这个循环的开销是足够低的。但是这个“ 得当 ”是怎么断言的呢?这里自然地就引出了一个现状:我们惯常地采用的常规复杂度去评判哈希方法似乎会有失偏颇。因为哈希表的构造极大地受到散列函数的构造方法与冲突避免手段的影响,这些方法和手段难以从代码中分析出来,更多是在设计阶段需要通过数学方法估量得到的。一般来说,衡量散列表的查找效率这个的指标依旧可以采用\(ASL\)完成,以及通过一个填装因子\(\alpha\)来进行分析:\[ \alpha = \frac{n}{m} \]
这里\(n\)象征表中记录数目,而\(m\)反映散列表的长度。直观来看,\(\alpha\)越大,表填装得就越满,冲突发生的概率就越大,反之亦最小。因此填装因子\(\alpha\)常常与散列函数的构造方法与冲突避免手段三者一同决定哈希构造的健壮性与复杂度。
3.单元测试
今天的单元测试案例就是上面讲解线性探测法使用的示例图。填装了7个关键词,其中填装57时与0号位置的38发生了冲突,经过一次线性探测移动到空余位置1号位,并填装;之后在填装95时首先与0号位置的38冲突,然后进行一次线性探测移动到1号位置又与57发生冲突,然后又进行了一次线性探测,进入了正常的空余的2号位置。
代码:
/**
*********************
* Test the method.
*********************
*/
public static void hashSearchTest() {
int[] tempUnsortedKeys = { 16, 33, 38, 69, 57, 95, 86 };
String[] tempContents = { "if", "then", "else", "switch", "case", "for", "while" };
DataArray tempDataArray = new DataArray(tempUnsortedKeys, tempContents, 19);
System.out.println(tempDataArray);
System.out.println("Search result of 95 is: " + tempDataArray.hashSearch(95));
System.out.println("Search result of 38 is: " + tempDataArray.hashSearch(38));
System.out.println("Search result of 57 is: " + tempDataArray.hashSearch(57));
System.out.println("Search result of 4 is: " + tempDataArray.hashSearch(4));
}// Of hashSearchTest输出结果:

总结
今天我们了解的内容很大程度上并不会真的在我们的代码中逐一体现,毕竟现在往往都是采用各种高级语言的库来帮助我们完成这个繁杂操作了。而且这些内置的库要比我们的这些技巧要高明太多了,而且它们还完美兼容范式编程,使得各种数据结构都能实现哈希映射。
在C++中我们常用的哈希表unordered_map的内部机理是采用一个链表数组完成的,它首先声明超大空间的桶空间,然后对于用户构造键值key进行映射到不同区域(桶)进行保存。因为要兼容范式编程,这个映射存在中间过程:事先会将key转换为某个hashCode,而再通过hashCode转换为对应的桶标号,这里取得hashCode用了一些巧妙地反复的操作。而Java的HashMap库,则是更加取巧将数组、单向链表、红黑树三种混合采用,针对不同的存储大小采用不同的数据结构。可见,随着如今高级语言库的完善,更多时候,我们只是考虑如何去设计一个符合我们目的的哈希映射,并且如何去应用哈希结构去解决我们的问题;不用用去花费时间去考虑设计散列函数和冲突的问题。
哈希表是一种对于算法进行复杂度优化的非常关键的工具,在算法的优化中我们总是向着最优靠近,而\(O(1)\)的常数级优化对于任何编程人员都有无可比拟的吸引。哪怕不是对问题的全体造成\(O(1)\)的优化,在局部完成这样的优化也会很大程度上消除我们对时间开销的部分担忧。灵活地在算法设计中使用哈希表不仅能很大程度提高复杂度,另一方面来说,这种单纯且暴力的映射也能极大增大我们代码的可读性,不用再去耗费大量的变量以及代码去修饰某个循环体、去说明某个繁杂的功能,只需要简简单单一个哈希即可消除你的一切忧虑!这将是判定初学者与经验者的一个显著的指标。