注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录

前言
从今天开始我们就正式结束图的数据结构有关的学习了,进入基础数据结构的最后一部分——查找有关的学习了。这部分也是我大概能最后侃侃而谈的知识了,后续50天开始机器学习后,那就真的是从零开始的学习了,前面的知识更多还是学习Java,数据结构知识都是顺带回顾,顺带地整理曾经关于数据结构的理解。
一、计算机中的查找
查找是个很有意思的话题,现实生活中我们就面临各种查找,在箱子里面找螺丝刀,在超市找自己想要的商品,在手机里面找图片,查字典。在这些生活案例中,我们或多或少都有一些关于查找的心得,很多时候都成为我们不可言说的基本常识。比如在超市里面找某个东西,我们会事先在脑海中确定这个物品的属于哪一类物品,然后到超市的对应层对应片区去筛选;在手机里面找图片早期的图片,我们把相册翻到最低层,然后顺序地网上翻....
这些生活中的细节其实也是我们在计算机中实现查找的基本思路。计算机中我们已经接触线性表,树,图三大主要结构,但是查找这个部分本身不隶属于任何结构,本质上,它是我们根据功能的实现而探讨数据结构的搭配过程,因此是一种面向问题的研究。后续我们讨论的诸如排序等操作也是这样的目的,所以要准备号这样基本的思维转换。而今天我们就从最基本的操作开始回顾。
二、顺序查找与ASL
查找最基本的思想:一个一个找。这个内容暂且不说通过查找这个问题想到这个方法,它的逆向过程我们在回顾顺序表的博客中思考过这个问题,即在顺序表中完成基本的查找功能。
顺序表本身就是数据的最基本存储载体,也是在物理存储结构中最直观的体现,而理论上,只要这个信息存储载体是可遍历的,那么就应当是可查找。因此作为最简单的遍历结构——顺序表,它的查找也是最简单,最容易想到的。顺序表的查找只需要从一段到另一端进行逐一遍历就好,当发现我们的数据之后就返回“查找成功”,若遍历到最后一个元素都未发现就返回“查找失败”。
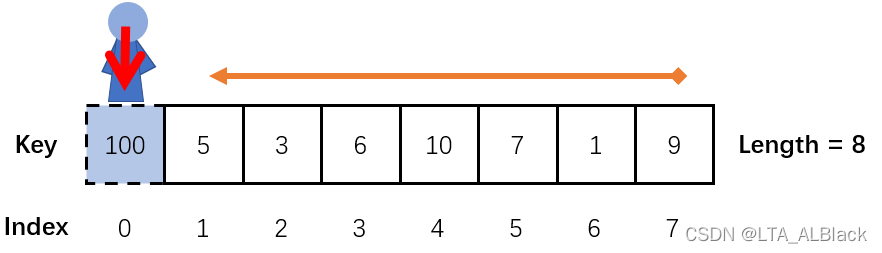
为了更方便量化这个过程,我们稍微统一下结束的条件:在顺序表中的一端设置一个冗余变量,命名为“哨兵”,同时将我们查找的目标值存放于哨兵之中,然后从哨兵相对的一端开始遍历,知道查找到与目标相同的元素时返回下标。整个顺序表中的有效元素中不包括这个哨兵,当我们在哨兵之前发现了我们希望的元素,说明找到了元素,正常返回下标即可。
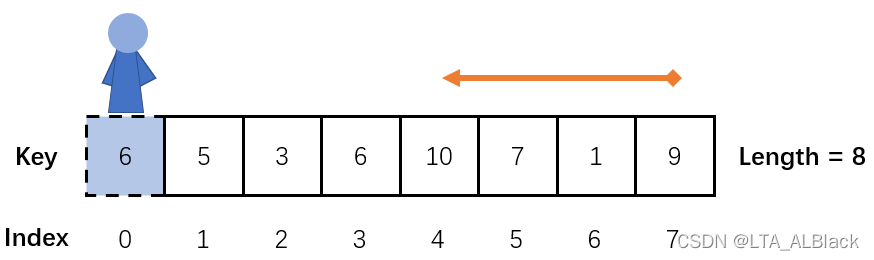
如果说全局都没发现元素,那么肯定地最终会遇到哨兵,必然地,我们会返回哨兵的下标。因此得到“ 全局搜索失败返回哨兵下标 ”的结论与结果。
假定除开哨兵,顺序表一共有\(n\)个元素,若给定的\(Key\)值元素,与表中的第\(i\)个元素相等,即定位第\(i\)个元素时,需进行\(n-i+1\)次关键字比较,设有\(C_{i}=n-i+1\),一次每个元素的查找等概率,为\(P_{i} = \frac{1}{n}\)。可得查找成功时,顺序查找的平均长度(Average Search Length)为:\[ASL_{success} = \sum_{i=1}^{n}P_{i}C_{i} =\sum_{i=1}^{n} \frac{n-i+1}{n} = \frac{n+1}{2}\]
(注:查找的平均长度是衡量查找效率的一个关键指标,因为查找的大量开销都花费在元素的比较上,因此我们把本身被选中的概率与比较的开销进行了基本的加乘得到了平均查找长度,具体定义有\(ASL = \sum_{i=1}^{n}P_{i}C_i\),\(P_{i}\)为查询第\(i\)元素的平均概率,\(C_i\)表示为第\(i\)个元素的比较次数)
那么哨兵方法和原本方法到底哪个好呢?我的评论是:差不多。两种相比彼此都没有非常明显的优点和缺点,详情请见我顺序表那篇博客:
三、关于折半查找
1.折半查找的规律
折半查找是针对顺序存起的有序表的一种非常独特查找方案,它最大化的利用了范围化的数据,将数据的范围条件作为信息定位的一个关键因素。这种思想诞生与数学中的二分法,即对于区间\([a,b]\)上连续不断且\(f(a)\cdot f(b)>0\)的函数\(y=f(x)\),通过不断地把函数\(f(x)\)的零点所在的区间一分为二得到中点\(x_0\),使区间的两个端点逐步逼近零点\(x_1\),进而得到零点近似值的方法。
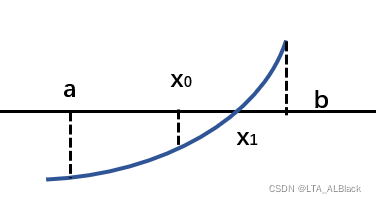
具体在程序中,我们针对一个从小大排序的有序表\(L\),待查找元素为\(Key\),在范围\([a,b]\)内查找第\(i\)个元素时,若发现第\(i\)个元素对应的关键字小于\(Key\),通过有序性可以断定\(Key\)值现在一定位于第\(i\)个元素的右侧,因此下一次搜索时就可以对于左端进行剪枝,收束范围到\([i,b]\)进一步查找。
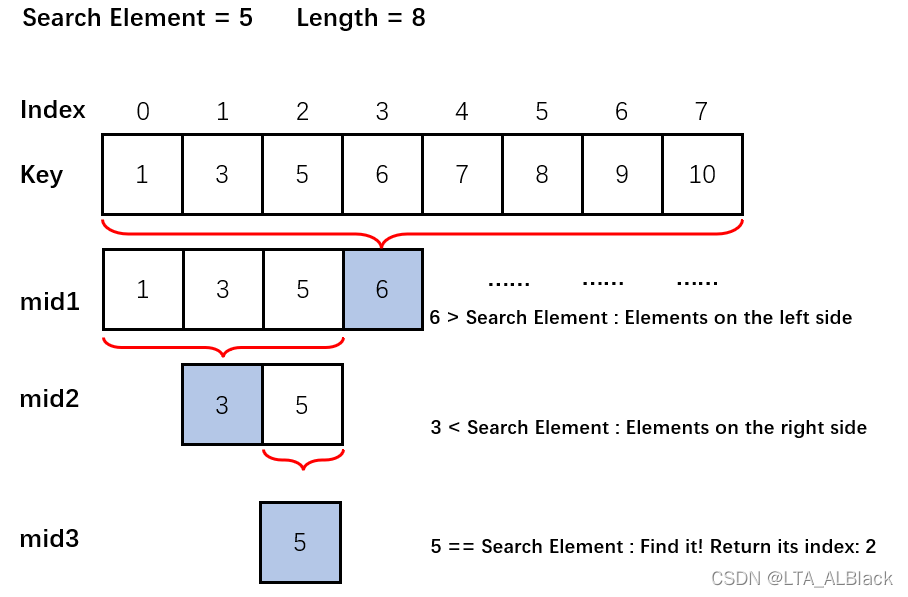
下面给出查找成功的一个案例。这里mid的计算方法是用范围内的最大下标与最大小标取和除2取得,可以发现,当我们不断计算,最终会出现一个关键mid值,若其与我们查询值一致便宣告算法结束并顺利找到元素。
2.失败的折半具有的价值
那么如果说深度到最终mid后还没能取等呢?可见下图这个计算流程。我们把范围的头尾指针分别用紫色和蓝色标记出来,挪动的范围一目了然:一旦计算出mid,而查询值小于mid,那么就让尾指针的值等于mid-1;一旦计算出mid,而查询值大于mid,那么就让头指针的值等于mid+1。可以发现一旦最终mid不满足的话,会出现尾指针跑到头指针的前面去的情况;同时不难推导也有可能头指针跑到尾指针的后面去(比如下图中Search Element = 5.5)
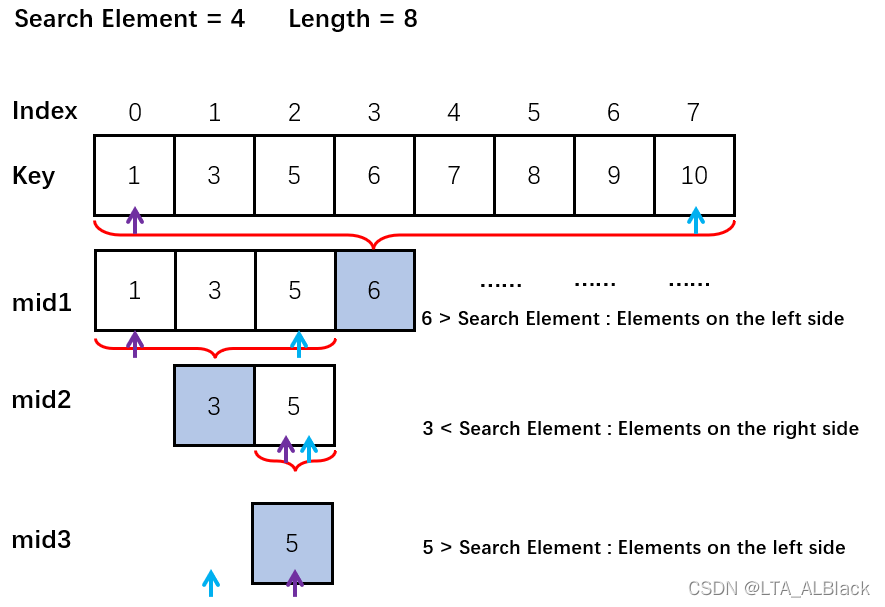
因此我们似乎发现了二分中循环的一个关键终止条件——头指针下标 ≥ 尾指针下标。同时不难发现一个关键特性:假如我们要查询的元素是paraKey,当查找失败的时候,虽然头、尾指针位置非法了,但是,恰好尾指针指向表中最后一个小于paraKey的元素!而头指针刚好指向第一个大于paraKey的元素!当然如果这里尾指针下标是-1,那么就说明没有元素比paraKey小;而如果这里头指针下标是length,那么就说明没有元素比paraKey大。这是一个非常关键的特性,可以用于快速估计paraKey元素在当前表位置关系,是一个极佳的优化策略。相关的实现有C++中的lower_bound方法与upper_bound方法。
3.折半二分查找的性能
通过上述演示可以发现折半法的搜索路径总是在折半分离,每步都仿佛都是在做一个二元的选择,这个过程似乎和从根开始向下的二元分叉的二叉树的逻辑意义很相似,不妨我们把二分法所有的分叉过程枚举出来,从而分析其特点。
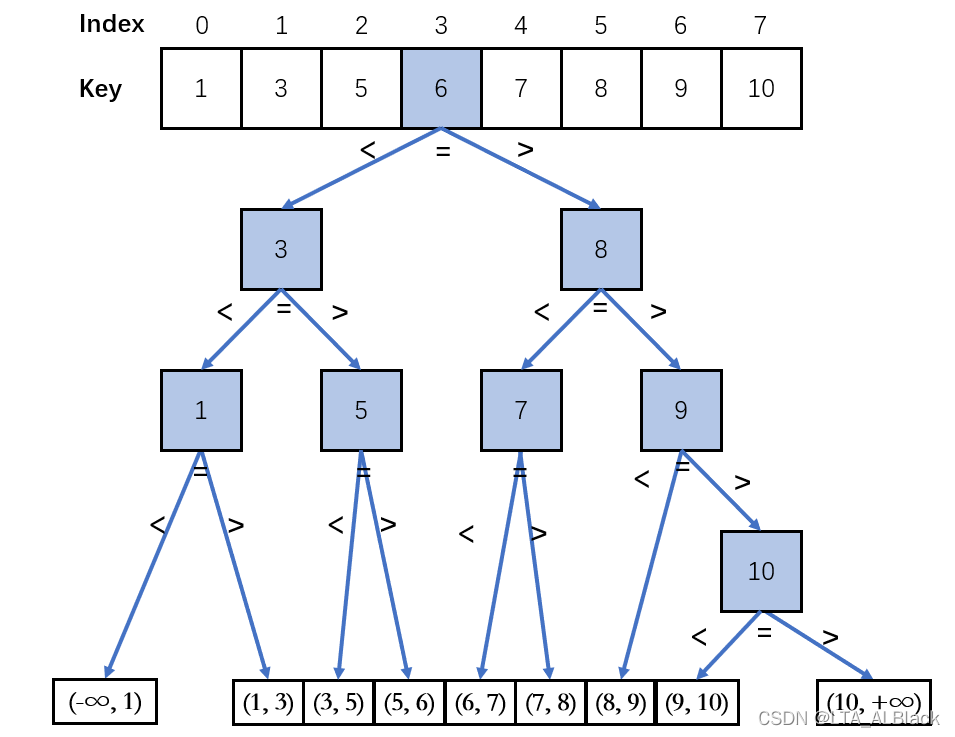
这个叫做折半查找过程过程的判定二叉树,在这里可以找到此有序表的任何查找路径。综上可以发现,一个具有\(n\)个结点的有序表构造的判定树一共具有\(n+1\)个叶子,而查询过程最终走到了叶子那么就预示着查询的失败,否则就确定地查询到了元素。从而还可以得知信息例如折半查找的复杂度是不会高于判定树的基本高度的。
只要枚举出了所有可能数值选择次数,那么就可以初略计算大概的ASL。通过大概(详见相关教材或者文章的推导)的计算,这里的\(ASL\)近似等于\(log_{2}(n+1)-1\)。这个结果在这种近似的树形的结构中不算少见,一旦一个结构的纵向越接近于分散的一棵树,那么其纵向深度就越接近\(log(N)\)的量级,这个特质需要记住。
因此总结来看,折半的查找的销量可以确定为\(log(N)\),当然要实现这样的效率的话,我们需要在计算出mid后直接得到L[mid]的值去比较,不可能说还要花费\(O(N)\)工夫去找到这个元素。因此我们要求此表必须有\(O(1)\)随机存取的特性。所以有个关键的结论:二分查找值只适用于顺序表。
四、代码编写
1.查找的表结构
这部分表结构稍微有些特殊,因为查找这部分学习我们关心的内容基本都是定值查找而非按序查找,而定值查找在以往的单体结构表中常见的应用无非是“ 按值Key查下标 ”。这个目的显得有些单薄了,于是我们扩充了一个信息域content,从而将目的变为“ 按值Key值查content ”,这样查询就变得有意义起来。
顺带一提,这样做也是有为后面的哈希结构做考量的。
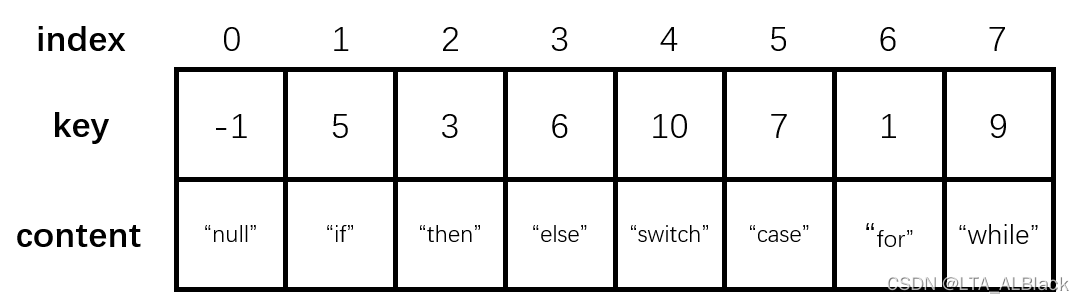
这种结构中,我们所有查询的依据都是依靠key值,但是这个值也许并不是我们最终使用这个结构去解决问题所关心的部分,因此额外我们设置了content值域。当然今天我们不用在意content的内容,今天的查询基准都是基于key值而定的。
/**
* An inner class for data nodes. The text book usually use an int value to
* represent the data. I would like to use a key-value pair instead.
*/
class DataNode {
/**
* The key.
*/
int key;
/**
* The data content.
*/
String content;
/**
*********************
* The first constructor.
*********************
*/
DataNode(int paraKey, String paraContent) {
key = paraKey;
content = paraContent;
}// Of the second constructor
/**
*********************
* Overrides the method claimed in Object, the superclass of any class.
*********************
*/
public String toString() {
return "(" + key + ", " + content + ") ";
}// Of toString
}// Of class DataNode
/**
* The data array.
*/
DataNode[] data;
/**
* The length of the data array.
*/
int length;
/**
*********************
* The first constructor.
*
* @param paraKeyArray The array of the keys.
* @param paraContentArray The array of contents.
*********************
*/
public DataArray(int[] paraKeyArray, String[] paraContentArray) {
length = paraKeyArray.length;
data = new DataNode[length];
for (int i = 0; i < length; i++) {
data[i] = new DataNode(paraKeyArray[i], paraContentArray[i]);
} // Of for i
}// Of the first constructor
/**
*********************
* Overrides the method claimed in Object, the superclass of any class.
*********************
*/
public String toString() {
String resultString = "I am a data array with " + length + " items.\r\n";
for (int i = 0; i < length; i++) {
resultString += data[i] + " ";
} // Of for i
return resultString;
}// Of toString
2.顺序查找
这里采用我们刚刚讲述的哨兵算法。因为哨兵算法隐藏了“找到”与“没找到”的差异,而且哨兵的末端设置也省略了边界判定,因此判断语句极大地简化为1个,而剩下的无非就是基本递增和初始化语句......这个结果不是和for循环的基本搭配一模一样吗?所以可以用一个空内容的for循环完成我们的顺序查找。
/**
*********************
* Sequential search. Attention: It is assume that the index 0 is NOT used.
*
* @param paraKey The given key.
* @return The content of the key.
*********************
*/
public String sequentialSearch(int paraKey) {
data[0].key = paraKey;
int i;
// Note that we do not judge i >= 0 since data[0].key = paraKey.
// In this way the runtime is saved about 1/2.
// This for statement is equivalent to
//for (i = length - 1; data[i].key != paraKey; i--);
for (i = length - 1; data[i].key != paraKey; i--) {
;
}//Of for i
return data[i].content;
}// Of sequentialSearch3.折半查找
折半查找在上面已经讲述得足够详细,这里要注意一些基本写法。折半查找有多种完成手段,这里我们采用的是:
- 头结点≤尾节点的循环条件
- 头尾指针每次通过mid+1或者mid-1的移动策略
其实还有一种可以采用的策略:
- 头结点<尾节点的循环条件
- 头尾指针每次直接指向mid的移动策略
然后上面的这些除了可以用迭代实现也可以用递归实现。
/**
*********************
* Binary search. Attention: It is assume that keys are sorted in ascending
* order.
*
* @param paraKey The given key.
* @return The content of the key.
*********************
*/
public String binarySearch(int paraKey) {
int tempLeft = 0;
int tempRight = length - 1;
int tempMiddle = (tempLeft + tempRight) / 2;
while (tempLeft <= tempRight) {
tempMiddle = (tempLeft + tempRight) / 2;
if (data[tempMiddle].key == paraKey) {
return data[tempMiddle].content;
} else if (data[tempMiddle].key <= paraKey) {
tempLeft = tempMiddle + 1;
} else {
tempRight = tempMiddle - 1;
}
} // Of while
// Not found.
return "null";
}// Of binarySearch五、数据测试
顺序表单元测试(这里的测试样例与上文介绍时使用的测试用例是一致的):
/**
*********************
* Test the method.
*********************
*/
public static void sequentialSearchTest() {
int[] tempUnsortedKeys = { -1, 5, 3, 6, 10, 7, 1, 9 };
String[] tempContents = { "null", "if", "then", "else", "switch", "case", "for", "while" };
DataArray tempDataArray = new DataArray(tempUnsortedKeys, tempContents);
System.out.println(tempDataArray);
System.out.println("Search result of 10 is: " + tempDataArray.sequentialSearch(10));
System.out.println("Search result of 5 is: " + tempDataArray.sequentialSearch(5));
System.out.println("Search result of 4 is: " + tempDataArray.sequentialSearch(4));
}// Of sequentialSearchTest测试结果:

折半查找单元测试(这里的测试样例与上文介绍时使用的测试用例是一致的):
/**
*********************
* Test the method.
*********************
*/
public static void binarySearchTest() {
int[] tempSortedKeys = { 1, 3, 5, 6, 7, 9, 10 };
String[] tempContents = { "if", "then", "else", "switch", "case", "for", "while" };
DataArray tempDataArray = new DataArray(tempSortedKeys, tempContents);
System.out.println(tempDataArray);
System.out.println("Search result of 10 is: " + tempDataArray.binarySearch(10));
System.out.println("Search result of 5 is: " + tempDataArray.binarySearch(5));
System.out.println("Search result of 4 is: " + tempDataArray.binarySearch(4));
}// Of binarySearchTest
测试结果:

总结
折半是一个非常重要的思想,任何能保证有序的结构中折半都是降低时间复杂度的常用查找方案,是一种小巧且巧妙的优化查询的常用方案。比如在插入排序中就有附带的折半插入排序的优化,在索引结构中,对于分块有序的地方可以采用折半查找进行优化。而在一些计算机参与的数学方法中,因为折半查找代表着数学中的二分法,因此在一些MATLAB中的一些用于拟合的函数中也会采用类似的思想。
其实要是只把折半查询视为元素有序结构的解决思路,那么格局就小了,其实折半算法的更重要精髓在于通过一次查询或者某种操作,确定当前环境与我们希望达到的目标的关系,然后进一步通过当前新环境对查询目标进行优化或者迭代。这种思路比1/2地折半本身更加重要,这就是对于一类算法思维的迁移,从小问题中看出算法的内核,并用这种内核去解决更加复杂的问题。比如,读者们不妨认真想想,快排是否就是用的如此类似的思想呢?