Acceleration Structures and Ray Tracing In Vulkan
在本章中,我们将修改 C++ 和 GLSL 代码以对网格进行光线追踪。我们将展示如何:
- 使用tinyobjloader从 OBJ 文件加载网格;
- 为快速光线场景交叉创建加速结构(Acceleration Structres);
- 将加速结构的描述符添加到描述符集中;
- 修改计算着色器以使用光线查询和光线追踪网格。
8.1 Including Additional Headers
本章使用了三个额外的标题。我们使用 C++ 的<array>头文件 for std::array,这将有助于稍后在第8.7节中写入描述符数组 。
我们还使用 syoyo 的tinyobjloader 从 OBJ 文件加载网格。很像stb_image_write,tinyobjloader要求我们在包含它之前TINYOBJLOADER_IMPLEMENTATION在一个文件 ( main.cpp) 中定义它。
最后,本教程的主要部分还将使用该nvvk::RaytracingBuilderKHR对象来帮助构建常见类型的加速结构。NVIDIA Vulkan 光线追踪教程在[此处](https://nvpro-samples.github.io/vk_raytracing_tutorial_KHR/vkrt_tutorial.md.htm#accelerationstructure/bottom-levelaccelerationstructure/helperdetails:raytracingbuilder::buildblas()展示了这些帮助程序的实现)。
将顶部的包含块更改为main.cpp以下内容 - 我们突出显示了要添加的代码行:
#include <array>
#define STB_IMAGE_WRITE_IMPLEMENTATION
#include <stb_image_write.h>
#define TINYOBJLOADER_IMPLEMENTATION
#include <fileformats/tiny_obj_loader.h>
#include <nvh/fileoperations.hpp> // For nvh::loadFile
#include <nvvk/context_vk.hpp>
#include <nvvk/descriptorsets_vk.hpp> // For nvvk::DescriptorSetContainer
#include <nvvk/error_vk.hpp> // For NVVK_CHECK
#include <nvvk/raytraceKHR_vk.hpp> // For nvvk::RaytracingBuilderKHR
#include <nvvk/resourceallocator_vk.hpp> // For NVVK memory allocators
#include <nvvk/shaders_vk.hpp> // For nvvk::createShaderModule
#include <nvvk/structs_vk.hpp> // For nvvk::make
8.2 Refactoring Command Buffers
在本节中,我们将使用第二个命令缓冲区将顶点和索引数据上传到 GPU。为了更轻松地创建、使用和释放第二个命令缓冲区,让我们采用一些现有的命令缓冲区代码并将其移至自己的函数中。
首先,让我们创建一个函数来从命令池中分配命令缓冲区,然后开始记录它(告诉 Vulkan 我们只会使用命令缓冲区一次)。在之前添加以下代码 main():
VkCommandBuffer AllocateAndBeginOneTimeCommandBuffer(VkDevice device, VkCommandPool cmdPool)
{
VkCommandBufferAllocateInfo cmdAllocInfo = nvvk::make<VkCommandBufferAllocateInfo>();
cmdAllocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
cmdAllocInfo.commandPool = cmdPool;
cmdAllocInfo.commandBufferCount = 1;
VkCommandBuffer cmdBuffer;
NVVK_CHECK(vkAllocateCommandBuffers(device, &cmdAllocInfo, &cmdBuffer));
VkCommandBufferBeginInfo beginInfo = nvvk::make<VkCommandBufferBeginInfo>();
beginInfo.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
NVVK_CHECK(vkBeginCommandBuffer(cmdBuffer, &beginInfo));
return cmdBuffer;
}
现在,在里面main(),删除这段代码:
// Allocate a command buffer
VkCommandBufferAllocateInfo cmdAllocInfo = nvvk::make<VkCommandBufferAllocateInfo>();
cmdAllocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
cmdAllocInfo.commandPool = cmdPool;
cmdAllocInfo.commandBufferCount = 1;
VkCommandBuffer cmdBuffer;
NVVK_CHECK(vkAllocateCommandBuffers(context, &cmdAllocInfo, &cmdBuffer));
// Begin recording
VkCommandBufferBeginInfo beginInfo = nvvk::make<VkCommandBufferBeginInfo>();
beginInfo.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
NVVK_CHECK(vkBeginCommandBuffer(cmdBuffer, &beginInfo));
并将其替换为以下调用AllocateAndBeginOneTimeCommandBuffer:
// Create and start recording a command buffer
VkCommandBuffer cmdBuffer = AllocateAndBeginOneTimeCommandBuffer(context, cmdPool);
我们还创建一个函数,结束记录命令缓冲区,然后将其提交到队列,等待它完成,然后释放命令缓冲区。在之前添加以下代码main():
void EndSubmitWaitAndFreeCommandBuffer(VkDevice device, VkQueue queue, VkCommandPool cmdPool, VkCommandBuffer& cmdBuffer)
{
NVVK_CHECK(vkEndCommandBuffer(cmdBuffer));
VkSubmitInfo submitInfo = nvvk::make<VkSubmitInfo>();
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &cmdBuffer;
NVVK_CHECK(vkQueueSubmit(queue, 1, &submitInfo, VK_NULL_HANDLE));
NVVK_CHECK(vkQueueWaitIdle(queue));
vkFreeCommandBuffers(device, cmdPool, 1, &cmdBuffer);
}
然后,在里面main(),删除这段代码:
// End recording
NVVK_CHECK(vkEndCommandBuffer(cmdBuffer));
// Submit the command buffer
VkSubmitInfo submitInfo = nvvk::make<VkSubmitInfo>();
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &cmdBuffer;
NVVK_CHECK(vkQueueSubmit(context.m_queueGCT, 1, &submitInfo, VK_NULL_HANDLE));
// Wait for the GPU to finish
NVVK_CHECK(vkQueueWaitIdle(context.m_queueGCT));
并将其替换为以下内容:
// End and submit the command buffer, then wait for it to finish:
EndSubmitWaitAndFreeCommandBuffer(context, context.m_queueGCT, cmdPool, cmdBuffer);
另外,删除vkFreeCommandBuffers末尾的调用main():
vkFreeCommandBuffers(context, cmdPool, 1, &cmdBuffer);
您应该仍然能够构建和运行应用程序。
接下来,我们将展示如何从 OBJ 文件加载三角形网格。
8.3 Triangle Meshes
大多数 3D 对象使用三角形网格表示。(计算机图形学中的其他一些常见对象表示——所有这些都可以在光线追踪框架中实现——是 3D 体积、程序对象、基于样条的曲面、粒子、直线和曲线。)
OBJ 文件格式使用一组顶点(它们是 3D 点,但也可以具有一些其他属性,例如我们不会使用的每个顶点的颜色)和一组三个索引的数组来表示网格。每组三个索引对应三个顶点,它们代表一个三角形。
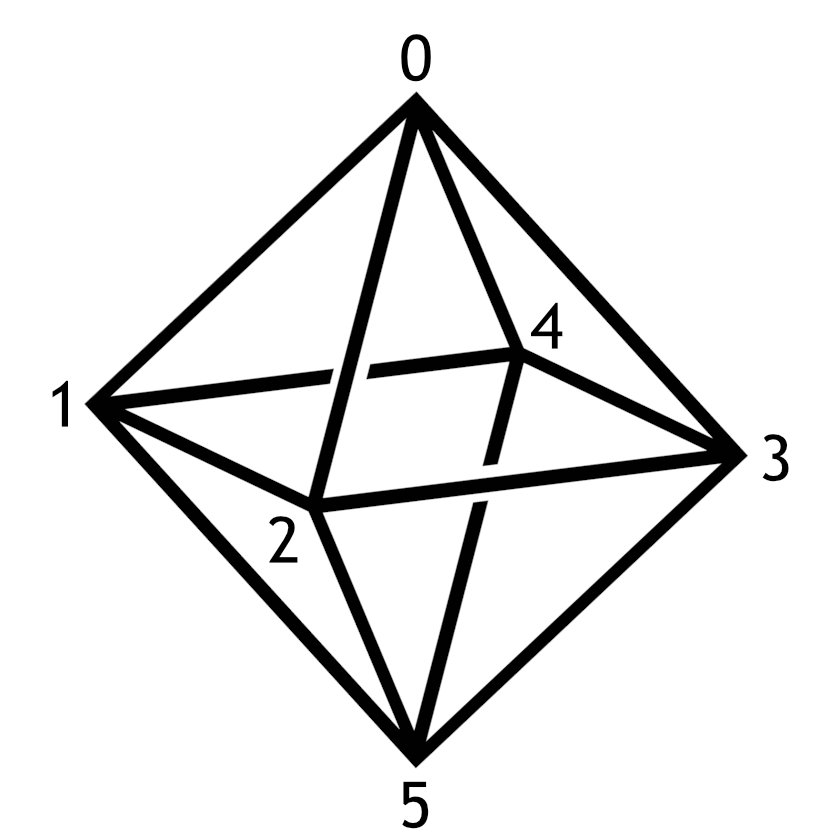 标有六个顶点的八面体线框。
标有六个顶点的八面体线框。
例如,三个索引{0, 1, 2}表示在上面的八面体中按顺序连接顶点 0、1 和 2 的三角形。
一个八面体有 6 个顶点和 8 个面。如果我们float为每个顶点的 X、Y 和 Z 坐标使用三个 4 字节的,则顶点数组将使用 4 × 3 × 6 = 72 字节。由于有 8 个面,我们将使用 3 × 8 = 24 个索引,这可能是unsigned ints,因此索引数组将使用 4 × 24 = 96 个字节。
例如,要在下面描述的右手 Y 向上坐标系中表示这个八面体,我们可能会使用以下顶点数组:
{
0., 1., 0., // Vertex 0
0., 0., 1., // Vertex 1
1., 0., 0., // Vertex 2
0., 0., -1., // Vertex 3
-1., 0., 0., // Vertex 4
0., -1., 0.} // Vertex 5
和以下索引数组:
{
0, 1, 2, // Indices of face 0
0, 2, 3, // Indices of face 1
0, 3, 4, // ...
0, 4, 1, //
5, 2, 1, //
5, 3, 2, //
5, 4, 3, //
5, 1, 4} // Indices of face 7
但是,有很多方法可以表示网格。对于这个八面体,某些引擎可能只使用每个索引 16 位(或更少)。其他人可能使用三角形条带或三角形扇形,或者使用三个顶点而不是每个三角形的索引(这不是很节省内存)。创建加速结构时,我们将告诉 Vulkan 应用程序如何表示内存中的每个网格。
8.4 Loading an OBJ File
我们现在将tinyobjloader用于加载位于vk_mini_path_tracer/media/scenes/CornellBox-Original-Merged.obj. 该文件包含一个三角形网格,它是著名的Cornell Box 测试模型的单色版本:

首先,让我们创建一个tinyobj::ObjReader对象,并将文件加载到内存中。更换定义的直线searchPaths与
// Load the mesh of the first shape from an OBJ file
const std::string exePath(argv[0], std::string(argv[0]).find_last_of("/\\") + 1);
std::vector<std::string> searchPaths = {
exePath + PROJECT_RELDIRECTORY, exePath + PROJECT_RELDIRECTORY "..",
exePath + PROJECT_RELDIRECTORY "../..", exePath + PROJECT_NAME};
tinyobj::ObjReader reader; // Used to read an OBJ file
reader.ParseFromFile(nvh::findFile("scenes/CornellBox-Original-Merged.obj", searchPaths));
assert(reader.Valid()); // Make sure tinyobj was able to parse this file
以下是获取 OBJ 文件中所有顶点的方法。(如果我们想读取诸如顶点颜色之类的东西,我们可以通过获取 的其他成员来实现reader.GetAttrib())
const std::vector<tinyobj::real_t> objVertices = reader.GetAttrib().GetVertices();
接下来,我们需要获取网格的索引。OBJ 文件可以包含多个形状,每个形状包括一个网格、一组线和一组点。我们得到形状列表,确保文件只包含一个形状(网格),然后得到那个形状:
const std::vector<tinyobj::shape_t>& objShapes = reader.GetShapes(); // All shapes in the file
assert(objShapes.size() == 1); // Check that this file has only one shape
const tinyobj::shape_t& objShape = objShapes[0]; // Get the first shape
为了获得网格的索引,我们遍历 中的每个index_t索引objShape.mesh.indices。OBJ 文件格式的一个不寻常之处在于,每个index_t索引都可以指向不同的顶点索引、法线索引和纹理坐标索引(稍后会详细介绍法线)。我们只需要顶点索引。
// Get the indices of the vertices of the first mesh of `objShape` in `attrib.vertices`:
std::vector<uint32_t> objIndices;
objIndices.reserve(objShape.mesh.indices.size());
for(const tinyobj::index_t& index : objShape.mesh.indices)
{
objIndices.push_back(index.vertex_index);
}
我们现在已经检索到网格的顶点和索引了!
OBJ 文件中的非三角形面 这不是一个完整的 OBJ 文件导入器 - 而不仅仅是三角形,OBJ 文件中的面可以是四边形、五边形或一般多边形。不幸的是,构建一个可以对多边形 进行三角剖分的完整 OBJ 文件阅读器超出了本教程的范围。
8.5 Uploading Data to the GPU
接下来,让我们将顶点和索引数据发送到 GPU,以便我们可以对其进行渲染。之前,我们创建了一个空缓冲区,在 GPU 上写入,然后在 CPU 上读回。这一次,我们将使用 的重载allocator.createBuffer来创建缓冲区并将 CPU 数据上传到 GPU。
allocator.createBuffer我们将使用 的重载如下所示:
template <typename T>
nvvk::Buffer createBuffer(const VkCommandBuffer& cmdBuf, // A command buffer to add upload commands to
const std::vector<T>& data_, // The data to upload to the command buffer
VkBufferUsageFlags usage_, // Specifies in advance how the buffer can be used
// By default, the final buffer exists in GPU-local memory, which means
// that the CPU can't access it. (We created `buffer` with memory properties
// that allowed us to map it to and from the CPU.)
VkMemoryPropertyFlags memProps_ = VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT)
{
return createBuffer(cmdBuf, sizeof(T) * data_.size(), data_.data(), usage_, memProps_);
}
为了使用它,我们将创建一个命令缓冲区,记录上传两个数组的指令,然后结束命令缓冲区并等待它完成。
在调用 之后vkCreateCommandPool,添加以下代码以启动命令缓冲区:
// Upload the vertex and index buffers to the GPU.
nvvk::Buffer vertexBuffer, indexBuffer;
{
// Start a command buffer for uploading the buffers
VkCommandBuffer uploadCmdBuffer = AllocateAndBeginOneTimeCommandBuffer(context, cmdPool);
然后调用allocator.createBuffer两次以创建缓冲区并记录命令以创建和上传数据。我们还需要提前指定我们将如何使用数据。我们将获得它们的设备地址(即它们在 GPU 上的内存地址),我们将buffer在下一章中将它们用作存储缓冲区(就像我们目前使用的一样),以及在构建加速结构时作为输入。
// We get these buffers' device addresses, and use them as storage buffers and build inputs.
const VkBufferUsageFlags usage = VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT
| VK_BUFFER_USAGE_ACCELERATION_STRUCTURE_BUILD_INPUT_READ_ONLY_BIT_KHR;
vertexBuffer = allocator.createBuffer(uploadCmdBuffer, objVertices, usage);
indexBuffer = allocator.createBuffer(uploadCmdBuffer, objIndices, usage);
最后,结束、提交、等待并释放命令缓冲区。分配器还会分配一些临时 暂存内存来执行这些上传到 GPU 本地内存,因此我们告诉分配器在命令缓冲区完成后释放此内存:
EndSubmitWaitAndFreeCommandBuffer(context, context.m_queueGCT, cmdPool, uploadCmdBuffer);
allocator.finalizeAndReleaseStaging();
}

此处补充:
此处描述的流程大致如下,将暂存区内存映射到CPU(因为对于CPU而言 GPU的内部缓冲区的申请分配对CPU是未知不可见的),然后通过memcpy将数据进行复制,然后再取消映射
auto data = stagingBufferMemory.Map(0, bufferSize);
memcpy(data, vertices.data(), (size_t)bufferSize);
stagingBufferMemory.Unmap();
8.6 Acceleration Structures
当GPU追踪一条射线时,它会找到一条射线与场景相交的地方。我们可能想找到最近的交叉点(对于像不透明表面这样的东西),所有的交叉点(对于像传输这样的东西),或者满足某些条件的最近的交叉点(对于具有alpha切割纹理的场景,其中多边形的某些部分是看不见的)。
假设我们现在只想找到射线与网格相交的位置。一种方法是在网格中选取每个三角形,并测试射线是否与该三角形相交。然而,这将是低效的–例如,一个场景可能有5000万个三角形;如果3840×2160图像的每个像素只追踪一条进入场景的光线,那么一个单帧将需要计算超过414万亿个光线-三角形相交点
(其实此处就是AABB),只不过Nvdia叫成AS(Acceleration Structures),那就跟他一起叫吧(
加快速度的一种方法是使用加速结构,例如 边界体积层次结构。这将根据三角形在网格中的位置将三角形组合成一个边界框树。现在,当光线穿过这个加速结构时,它必须只考虑一组小得多的潜在交叉点。(在计算复杂度方面,对于足够好的情况,这减少了从 O ( n ) O(n) O(n)到 O ( l o g n ) O(logn) O(logn), 其中 n n n 是网格中三角形的数量。)
此外,RTX GPU 包含 RT Cores,它们是实现加速结构遍历和光线三角形交叉的硬件单元。与没有 RT 核心的类似 GPU 相比,这使得光线追踪速度明显更快。因此,例如,RTX 2080 Ti在标准测试模型上每秒可以计算超过 100 亿个最近命中的射线网格交叉点。
我们上面描述的是单个网格的加速结构。但是,场景通常包含许多网格,包括具有不同比例、旋转和位置的同一网格的多个实例。为了快速进行光线追踪,Vulkan 可以在其他加速结构的实例上使用加速结构!

加速结构图。三角形有三个底层加速结构(BLASes),一个包含四个实例的顶层加速结构。两个实例指向同一个 BLAS;这可用于在场景中的不同位置包含模型的多个副本(可能有变化)。来自NVIDIA Vulkan 光线追踪教程。
更具体地说,Vulkan 光线追踪使用了两级加速结构格式。 底层加速结构(BLASes)是三角形(或过程对象的边界框)的加速结构, 顶层加速结构是实例的加速结构,每个实例指向一个BLAS,包括一个变换(描述位置、旋转、平移和使用 3 × 4 仿射变换矩阵的实例倾斜),还包括下面描述的一些附加信息。


为了建立一个加速结构,我们描述对象(比如三角形或实例),然后把这个描述交给Vulkan–在大多数情况下,GPU就会负责生成树状结构。然而,由于有如此多的方法来指定几何图形,有许多问题我们必须回答。
例如,以下是创建 BLAS 时需要指定的一些内容:
- GPU 上的顶点和索引缓冲区在哪里?
- 顶点在内存中是如何排列的?(在这种情况下,它们是连续排列的 3 个浮点数的集合。)
- 索引使用什么格式?(在这种情况下,它们都是无符号整数。)
- 有多少个顶点?
- BLAS 是否包含三角形或程序对象(最初由轴对齐的边界框表示)?
- 有多少个三角形?
- 什么是起始三角形和终止三角形?
- AS 构建器应该优先快速构建 AS,还是优先构建 AS,以便调用可以更快地跟踪光线?
- AS应该被压缩吗?(这是使 AS 使用更少内存的步骤。)
- AS应该是可更新的吗?(这使得如果网格随时间改变形状,AS 可以在不改变树结构的情况下快速重新拟合,而不是重建。此示例仅渲染一帧,因此我们不会使用它。)
另一方面,在创建 TLAS 时,nvvk::RaytracingBuilderKHR可以使用nvvk::RaytracingBuilderKHR::Instance实例对象列表,这需要较少的规范。
也就是说,从总体上看,创建 BLAS 和 TLAS 不会花费太长时间——大约有 48 行,这将构成程序的大部分其余部分。让我们开始吧!
8.6.1 Adding GetBufferDeviceAddress
首先,让我们添加一个函数来获取 a 的设备地址VkBuffer。如上所述,设备地址就像 GPU 上一块内存的地址。为了获取缓冲区的地址,我们创建了一个VkBufferDeviceAddressInfo指定 的对象VkBuffer,然后调用vkGetBufferDeviceAddress。
在 之后添加以下函数EndSubmitWaitAndFreeCommandBuffer:
VkDeviceAddress GetBufferDeviceAddress(VkDevice device, VkBuffer buffer)
{
VkBufferDeviceAddressInfo addressInfo = nvvk::make<VkBufferDeviceAddressInfo>();
addressInfo.buffer = buffer;
return vkGetBufferDeviceAddress(device, &addressInfo);
}
8.6.2 Creating the BLAS
我们通过将nvvk::RaytracingBuilderKHR::BlasInput对象向量(用于创建 BLAS 的输入信息)传递给 来创建底层加速结构nvvk::RaytracingBuilderKHR::buildBlas。
要创建nvvk::RaytracingBuilderKHR::BlasInput,我们需要创建三个对象:
VkAccelerationStructureGeometryTrianglesDataKHR指定在哪里可以找到顶点和索引缓冲区,以及它们在内存中的布局(例如我们如何格式化顶点和索引),以及我们使用的顶点数组中的最大索引。VkAccelerationStructureGeometryKHR指向第一个对象,并添加几何标志(在这种情况下,表示几何没有透明表面)。VkAccelerationStructureBuildRangeInfoKHR指定要使用的数据范围,包括三角形的数量。可以使用它来告诉 AS 构建器只包含三角形的前半部分,向所有索引添加一个常量值,或者查找要从另一个缓冲区应用的变换矩阵,但我们将使用 most-default设置。
8.6.2.1 VkAccelerationStructureGeometryTrianglesDataKHR
在上传顶点和索引缓冲区后添加以下代码。
首先定义BlasInput对象的向量,开始创建,然后获取顶点缓冲区和索引缓冲区的设备地址:
// Describe the bottom-level acceleration structure (BLAS)
std::vector<nvvk::RaytracingBuilderKHR::BlasInput> blases;
{
nvvk::RaytracingBuilderKHR::BlasInput blas;
// Get the device addresses of the vertex and index buffers
VkDeviceAddress vertexBufferAddress = GetBufferDeviceAddress(context, vertexBuffer.buffer);
VkDeviceAddress indexBufferAddress = GetBufferDeviceAddress(context, indexBuffer.buffer);
然后,描述VkAccelerationStructureGeometryTrianglesDataKHR对象。这个对象说:
- 顶点格式为
VK_FORMAT_R32G32B32_SFLOAT(即一个顶点由三个 32 位浮点坐标按 X、Y、Z 顺序组成)。 - 顶点可以在 中找到
vertexBufferAddress。 - 每个顶点开始 3 * sizeof ( float ) = 123*大小(漂浮)=12下一个字节之后。(如果有一个缓冲区,例如一个顶点有一组 XYZ 坐标,然后是 RGB 颜色,然后是另一组 XYZ 坐标,等等,这将很有用。)
- 我们将使用顶点 0 到
objVertices.size()/3 - 1。除以 3 是因为objVertices是一个浮点数向量,每个顶点使用 3 个浮点数。 - 索引格式为
VK_INDEX_TYPE_UINT32(即一个索引是一个 32 位无符号整数)。 - 可以在 找到索引
indexBufferAddress。 - 没有变换矩阵。(这可以是指向设备内存中矩阵的指针——但这里我们使用 0 来表示构建器应该使用单位矩阵,这不会影响顶点的位置。)
// Specify where the builder can find the vertices and indices for triangles, and their formats:
VkAccelerationStructureGeometryTrianglesDataKHR triangles = nvvk::make<VkAccelerationStructureGeometryTrianglesDataKHR>();
triangles.vertexFormat = VK_FORMAT_R32G32B32_SFLOAT;
triangles.vertexData.deviceAddress = vertexBufferAddress;
triangles.vertexStride = 3 * sizeof(float);
triangles.maxVertex = static_cast<uint32_t>(objVertices.size()/3 - 1);
triangles.indexType = VK_INDEX_TYPE_UINT32;
triangles.indexData.deviceAddress = indexBufferAddress;
triangles.transformData.deviceAddress = 0; // No transform
8.6.2.2 VkAccelerationStructureGeometryKHR
这个对象说:
- 几何体是一个三角形网格(与实例边界框列表或程序对象相反)。
- 描述三角形网格的对象是
triangles。 - 几何图形使用
VK_GEOMETRY_OPAQUE_BIT_KHR标志。(有关标志的完整列表,请参阅https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkGeometryFlagBitsNV.html。)
// Create a VkAccelerationStructureGeometryKHR object that says it handles opaque triangles and points to the above:
VkAccelerationStructureGeometryKHR geometry = nvvk::make<VkAccelerationStructureGeometryKHR>();
geometry.geometry.triangles = triangles;
geometry.geometryType = VK_GEOMETRY_TYPE_TRIANGLES_KHR;
geometry.flags = VK_GEOMETRY_OPAQUE_BIT_KHR;
blas.asGeometry.push_back(geometry);
8.6.2.3 VkAccelerationStructureBuildOffsetInfoKHR
如上所述,我们不使用此结构的任何功能;唯一不为零的字段是primitiveCount,它是这种情况下的三角形数量(因为我们说这是 中的三角形网格geometry.geometryType)。
// Create offset info that allows us to say how many triangles and vertices to read
VkAccelerationStructureBuildRangeInfoKHR offsetInfo;
offsetInfo.firstVertex = 0;
offsetInfo.primitiveCount = static_cast<uint32_t>(objIndices.size() / 3); // Number of triangles
offsetInfo.primitiveOffset = 0;
offsetInfo.transformOffset = 0;
blas.asBuildOffsetInfo.push_back(offsetInfo);
blases.push_back(blas);
}
8.6.2.4 Running buildBlas
最后,创建光线追踪构建器,告诉它 Vulkan 上下文、内存分配器和要使用的队列,然后构建 BLAS。在这里,我们告诉它更喜欢快速的光线追踪性能,而不是更喜欢快速的 AS 构建。
// Create the BLAS
nvvk::RaytracingBuilderKHR raytracingBuilder;
raytracingBuilder.setup(context, &allocator, context.m_queueGCT);
raytracingBuilder.buildBlas(blases, VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR);

8.6.3 Creating the TLAS
要创建 TLAS,我们需要创建一个nvvk::RaytracingBuilderKHR::Instance对象。这个对象有四个字段:
blasId是要使用的 BLAS 的索引。我们要使用第一个 BLAS,即索引 0。transform是一个 4 × 4 矩阵变换(仅使用前 3 行),可用于平移、缩放、旋转和倾斜实例。但是,我们使用单位矩阵,它不会改变顶点位置。请参阅下面的详细信息。instanceCustomId和hitGroupId是 24 位和 32 位值(分别),允许实例具有如上所述的不同外观。但是,我们不会在本教程的主要部分使用它们。
// Create an instance pointing to this BLAS, and build it into a TLAS:
std::vector<nvvk::RaytracingBuilderKHR::Instance> instances;
{
nvvk::RaytracingBuilderKHR::Instance instance;
instance.transform.identity(); // Set the instance transform to the identity matrix
instance.instanceCustomId = 0; // 24 bits accessible to ray shaders via rayQueryGetIntersectionInstanceCustomIndexEXT
instance.blasId = 0; // The index of the BLAS in `blases` that this instance points to
instance.hitGroupId = 0; // Used for a shader offset index, accessible via rayQueryGetIntersectionInstanceShaderBindingTableRecordOffsetEXT
instance.flags = VK_GEOMETRY_INSTANCE_TRIANGLE_FACING_CULL_DISABLE_BIT_KHR; // How to trace this instance
instances.push_back(instance);
}
最后,通过调用启动 TLAS 构建nvvk::RaytracingBuilderKHR::buildTlas:
raytracingBuilder.buildTlas(instances, VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR);
现在在 C++ 方面剩下的就是将 TLAS 添加到描述符集!
仿生变换矩阵
Vulkan光线追踪使用3×4仿生变换矩阵来变换网格。这些矩阵可以用来定位、旋转、缩放和倾斜物体。(instance.transform使用的是4×4的矩阵,但实现时删除了最后一行来传递给Vulkan光线追踪。)
当使用instance.transform矩阵M来表示转换后的BLAS时,该实例就像所有v=(x,y,z)顶点都被应用了以下转换一样。
第二个方程说这是3×3矩阵-向量乘法的总和,再加上一个平移。
如果我们使用去除第四行的4×4身份矩阵。

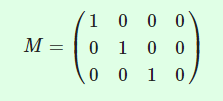
那么顶点就没有变化。
有关转换的一些示例,请参阅附加内容的本章和本文。
8.7 Adding the TLAS to the Descriptor Set
要跟踪来自着色器的光线,我们需要将加速结构添加到描述符集。为此,让我们通过在addBinding代码中添加另一行,使绑定 1 成为可以从计算着色器访问的加速结构描述符:
// Here's the list of bindings for the descriptor set layout, from raytrace.comp.glsl:
// 0 - a storage buffer (the buffer `buffer`)
// 1 - an acceleration structure (the TLAS)
nvvk::DescriptorSetContainer descriptorSetContainer(context);
descriptorSetContainer.addBinding(0, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1, VK_SHADER_STAGE_COMPUTE_BIT);
descriptorSetContainer.addBinding(1, VK_DESCRIPTOR_TYPE_ACCELERATION_STRUCTURE_KHR, 1, VK_SHADER_STAGE_COMPUTE_BIT);
我们还必须使描述符集中的这个描述符指向 TLAS。找到以下代码块:
// Write a single descriptor in the descriptor set.
VkDescriptorBufferInfo descriptorBufferInfo{
};
descriptorBufferInfo.buffer = buffer.buffer; // The VkBuffer object
descriptorBufferInfo.range = bufferSizeBytes; // The length of memory to bind; offset is 0.
VkWriteDescriptorSet writeDescriptor = descriptorSetContainer.makeWrite(0 /*set index*/, 0 /*binding*/, &descriptorBufferInfo);
vkUpdateDescriptorSets(context, // The context
1, &writeDescriptor, // An array of VkWriteDescriptorSet objects
0, nullptr); // An array of VkCopyDescriptorSet objects (unused)
并用以下代码替换它:
// Write values into the descriptor set.
std::array<VkWriteDescriptorSet, 2> writeDescriptorSets;
// 0
VkDescriptorBufferInfo descriptorBufferInfo{
};
descriptorBufferInfo.buffer = buffer.buffer; // The VkBuffer object
descriptorBufferInfo.range = bufferSizeBytes; // The length of memory to bind; offset is 0.
writeDescriptorSets[0] = descriptorSetContainer.makeWrite(0 /*set index*/, 0 /*binding*/, &descriptorBufferInfo);
// 1
VkWriteDescriptorSetAccelerationStructureKHR descriptorAS = nvvk::make<VkWriteDescriptorSetAccelerationStructureKHR>();
VkAccelerationStructureKHR tlasCopy = raytracingBuilder.getAccelerationStructure(); // So that we can take its address
descriptorAS.accelerationStructureCount = 1;
descriptorAS.pAccelerationStructures = &tlasCopy;
writeDescriptorSets[1] = descriptorSetContainer.makeWrite(0, 1, &descriptorAS);
vkUpdateDescriptorSets(context, // The context
static_cast<uint32_t>(writeDescriptorSets.size()), // Number of VkWriteDescriptorSet objects
writeDescriptorSets.data(), // Pointer to VkWriteDescriptorSet objects
0, nullptr); // An array of VkCopyDescriptorSet objects (unused)
这将创建一个VkWriteDescriptorSets数组,而不是一个VkWriteDescriptorSet用于传递给s的数组vkUpdateDescriptorSets。
8.8 Cleaning Up
最后,我们必须在程序结束时销毁光线追踪构建器以及顶点和索引缓冲区。在之后添加这三行descriptorSetContainer.deinit():
raytracingBuilder.destroy();
allocator.destroy(vertexBuffer);
allocator.destroy(indexBuffer);
本章的 C++ 代码到此结束!我们现在已经编写了本教程的几乎所有 C++ 代码;下一章将把顶点和索引缓冲区添加到描述符集中,但在那之后,我们将专门修改着色器代码。
现在让我们转向修改计算着色器以添加针孔相机,并将光线追踪到场景中。到本章结束时,我们将能够渲染康奈尔盒子。
现在也是main.cpp与main.cppin的参考版本进行比较8_ray_tracing并检查任何拼写错误的绝佳时机。
8.9 GLSL: Adding the GL_EXT_ray_query Extension
首先,这个新的计算着色器需要GL_EXT_ray_query扩展来跟踪光线。将以下代码行添加到#extension顶部的指令块中raytrace.comp.glsl:
#extension GL_EXT_ray_query : require
8.10 GLSL: Accessing the TLAS
接下来,让我们让计算着色器可以访问新的 TLAS 描述符。与 不同imageData,TLAS 是单个变量,而不是存储缓冲区,因此我们使用uniform接口限定符:
layout(binding = 1, set = 0) uniform accelerationStructureEXT tlas;
8.11 GLSL: A Virtual Camera
删除main()以定义的行开头的所有代码const vec3 pixelColor。(不要删除if((pixel.x >= resolution.x) ...检查。) GLSL 代码的其余部分将为每个像素:
- 定义一个位于 (−0.001, 1, 6) 处的虚拟相机;
- 求相机光线通过像素中心的方向;
- 初始化一个射线查询;
- 跟踪光线,直到找到与光线相交的最近表面;
- 获取射线的t 值;
- 将t值变成灰度颜色;
- 将灰度颜色写入缓冲区。
在 Vulkan 光线追踪中,光线由其原点定义 ○○和它的方向 dd. (这些变量以粗体表示,表示它们是向量。)
 一条原点为 o 方向为 d 的射线,沿其标记了一些点
一条原点为 o 方向为 d 的射线,沿其标记了一些点
r ( t ) = o + t d \mathbf{r}(t) = \mathbf{o} + t\mathbf{d} r(t)=o+td
例如,点 o o o的 t t t值为0, o + d o+d o+d的 t t t值为1, o + 1.5 d o+1.5d o+1.5d的 t t t值为1.5,以此类推。t值也是沿射线的一个点与射线原点的距离,除以d的长度。
这是我们场景的示意图。此场景使用OBJ 坐标系,其中 x 轴正指向右,y 轴正指向上,Z 轴正从康奈尔盒指向相机。这是一个右手 Y 向上坐标系。
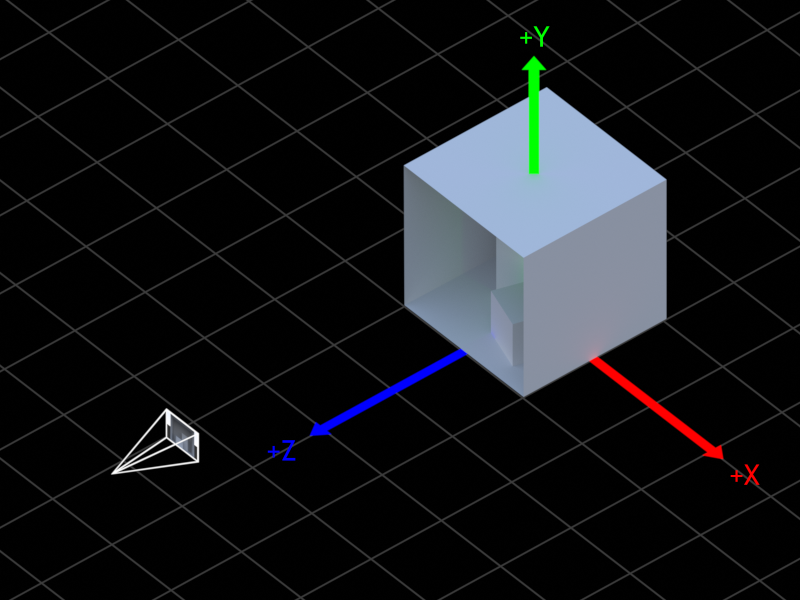
场景图,显示相机、其视野、康奈尔盒以及坐标系的正 X(红色)、Y(绿色)和 Z(蓝色)轴
我们将使用位于 (−0.001, 1, 6) 的虚拟相机对该场景进行光线追踪。(换句话说,我们将从那个角度渲染场景。)这个相机将是一个针孔相机,所以所有光线的原点都在 (-0.001, 1, 6),每个像素都有不同的方向。
要确定每个像素的方向,想象一下在相机原点前面放置一个计算机屏幕 1 个单位,分辨率为 resolution.xx resolution.y。每条光线将从 (-0.001, 1, 6) 开始,并且最初会通过每个像素的中心。让我们定义的垂直视野的说,从屏幕伸出相机是 y = 1 − 1 / 5 y=1-1/5 y=1−1/5到 是 y = 1 + 1 / 5 y=1+1/5 y=1+1/5(这控制康奈尔盒子出现的大小)。
让我们在这个屏幕上找到一个像素的坐标。首先,我们将像素坐标转换为如下所示,其中一种 是屏幕的纵横比(宽/高,在我们的例子中是 800/600 = 4/3):

( pixel.x + 0.5 , pixel.y + 0.5 ) (\text{pixel.x} + 0.5, \text{pixel.y} + 0.5) (pixel.x+0.5,pixel.y+0.5)
减去一半的分辨率得到坐标 [ − r e s o l u t i o n . x / 2 , r e s o l u t i o n . x / 2 ] [-resolution.x/2,resolution.x/2] [−resolution.x/2,resolution.x/2] x [ − r e s o l u t i o n . y / 2 , r e s o l u t i o n . y / 2 ] [-resolution.y/2,resolution.y/2] [−resolution.y/2,resolution.y/2]:
( pixel.x + 0.5 − resolution.x 2 , pixel.y + 0.5 − resolution.y 2 ) . \left(\text{pixel.x} + 0.5 - \frac{\text{resolution.x}}{2}, \text{pixel.y} + 0.5 - \frac{\text{resolution.y}}{2}\right). (pixel.x+0.5−2resolution.x,pixel.y+0.5−2resolution.y).
我们可以乘以 1 / 分 辨 率 . y 1 /分辨率.y 1/分辨率.y 获取 [ − a / 2 , a / 2 ] x [ − 1 / 2 , 1 / 2 ] [-a/2, a/2] x [−1/2, 1/2] [−a/2,a/2]x[−1/2,1/2]中的坐标,同时保持像素为正方形:
( pixel.x + 0.5 − resolution.x / 2 resolution.y , pixel.y + 0.5 − resolution.y / 2 resolution.y ) . \left(\frac{\text{pixel.x} + 0.5 - \text{resolution.x}/2}{\text{resolution.y}}, \frac{\text{pixel.y} + 0.5 - \text{resolution.y}/2}{\text{resolution.y}}\right). (resolution.ypixel.x+0.5−resolution.x/2,resolution.ypixel.y+0.5−resolution.y/2).
最后,将 x 坐标乘以 2,将 y 坐标乘以 −2(翻转 y 轴)以得到屏幕坐标,在 [ − a , a ] x [ − 1 , 1 ] [-a, a] x [−1, 1] [−a,a]x[−1,1] 中:
screenUV = ( 2 pixel.x + 1 − resolution.x resolution.y , − 2 pixel.y + 1 − resolution.y resolution.y ) \textbf{screenUV} = \left(\frac{2 \text{pixel.x} + 1 - \text{resolution.x}}{\text{resolution.y}}, -\frac{2 \text{pixel.y} + 1 - \text{resolution.y}}{\text{resolution.y}}\right) screenUV=(resolution.y2pixel.x+1−resolution.x,−resolution.y2pixel.y+1−resolution.y)
下面是如何从屏幕 UV 和视野的垂直斜率中获取光线方向:
rayDirection = ( fovVerticalSlope ∗ screenUV.x , fovVerticalSlope ∗ screenUV.y , − 1.0 ) . \textbf{rayDirection} = (\text{fovVerticalSlope} * \text{screenUV.x}, \text{fovVerticalSlope} * \text{screenUV.y}, -1.0). rayDirection=(fovVerticalSlope∗screenUV.x,fovVerticalSlope∗screenUV.y,−1.0).
将以下代码添加到main()inraytrace.comp.glsl以定义相机原点和光线原点,并计算像素的光线方向:
// This scene uses a right-handed coordinate system like the OBJ file format, where the
// +x axis points right, the +y axis points up, and the -z axis points into the screen.
// The camera is located at (-0.001, 1, 6).
const vec3 cameraOrigin = vec3(-0.001, 1.0, 6.0);
// Rays always originate at the camera for now. In the future, they'll
// bounce around the scene.
vec3 rayOrigin = cameraOrigin;
// Compute the direction of the ray for this pixel. To do this, we first
// transform the screen coordinates to look like this, where a is the
// aspect ratio (width/height) of the screen:
// 1
// .------+------.
// | | |
// -a + ---- 0 ---- + a
// | | |
// '------+------'
// -1
const vec2 screenUV = vec2(2.0 * (float(pixel.x) + 0.5 - 0.5 * resolution.x) / resolution.y, //
-(2.0 * (float(pixel.y) + 0.5 - 0.5 * resolution.y) / resolution.y) // Flip the y axis
);
// Next, define the field of view by the vertical slope of the topmost rays,
// and create a ray direction:
const float fovVerticalSlope = 1.0 / 5.0;
vec3 rayDirection = vec3(fovVerticalSlope * screenUV.x, fovVerticalSlope * screenUV.y, -1.0);
8.12 GLSL: Ray Queries
现在,我们将向场景中投射光线。为此,我们将使用光线查询来回答“场景的哪些部分与这条光线相交”的问题?
我们将首先初始化一个射线查询。然后我们将重复调用rayQueryProceedEXT循环遍历光线与几何相交的所有位置。光线查询会自动跟踪最近的交叉点,当这个循环结束时,我们将能够找到关于这个最近的交叉点的信息(以及是否有任何交叉点)。
现在,GLSL 射线查询函数的最佳文档是GLSL_EXT_ray_query扩展规范本身,可以在此处找到。
为了初始化光线查询,我们调用rayQueryInitializeEXT:
- 射线查询对象
- 顶层加速结构
- Ray 标志允许我们自定义或加速交叉点的搜索,并且可以覆盖实例标志。我们将使用
gl_RayFlagsOpaqueEXT标志,意思是“没有透明度”。(有关完整列表,请参阅GL_EXT_ray_tracing) - 一个 8 位的光线掩码。(实例具有 8 位掩码;只有在射线掩码和实例掩码中至少有一位处于相同位置时,射线才能与实例相交。这意味着可以将实例划分为不同的细节级别,例如实例,并告诉光线仅跟踪特定级别的细节。我们使用 0xFF 的光线遮罩,并且所有实例遮罩都是 0xFF。有关更多详细信息,请参见下面的框。)
- 射线源
- 光线的最小 t 值,tMin
- 射线方向
- 射线的最大 t 值,tMax
tMin和tMax让我们在单个线段中搜索交点,即光线的一部分吨分钟≤ t ≤吨最大限度吨分钟≤吨≤吨最大限度,而不是整个射线。

添加此代码以初始化光线查询对象:
// Trace the ray and see if and where it intersects the scene!
// First, initialize a ray query object:
rayQueryEXT rayQuery;
rayQueryInitializeEXT(rayQuery, // Ray query
tlas, // Top-level acceleration structure
gl_RayFlagsOpaqueEXT, // Ray flags, here saying "treat all geometry as opaque"
0xFF, // 8-bit instance mask, here saying "trace against all instances"
rayOrigin, // Ray origin
0.0, // Minimum t-value
rayDirection, // Ray direction
10000.0); // Maximum t-value
接下来,我们将在一个循环中调用rayQueryProceedEXT。通常,每次我们调用此函数时,它都会进入下一个交叉点,并更新已提交的交叉点,这是迄今为止最近(接受)的交叉点。rayQueryProceedEXT返回false一旦我们遍历了所有的射线场景交叉点,rayQueryProceedEXT就会返回false。
添加以下代码:
// Start traversal, and loop over all ray-scene intersections. When this finishes,
// rayQuery stores a "committed" intersection, the closest intersection (if any).
while(rayQueryProceedEXT(rayQuery))
{
}
由于我们使用了gl_RayFlagsOpaqueEXT标志,rayQueryProceedEXT会立即找到最近的交点,然后返回false,而不执行块内的任何代码。不过,在这里使用while循环有助于避免错误——它可以确保即使使用不同的标志,代码也是正确的,我们将在下一章中看到如何创造性地使用它。
光线投射现在已经完成,并rayQuery存储最近的交叉点(具有最低 t 值的交叉点)!添加此代码以获取已提交交集的 t 值:
// Get the t-value of the intersection (if there's no intersection, this will
// be tMax = 10000.0). "true" says "get the committed intersection."
const float t = rayQueryGetIntersectionTEXT(rayQuery, true);
8.13 GLSL: Depth Mapping
这里,t是沿射线的场景深度。让我们将其除以 10 以将 0 到 10 之间的深度映射到 0 到 1 的范围,然后将其存储为颜色:
// Get the index of this invocation in the buffer:
uint linearIndex = resolution.x * pixel.y + pixel.x;
// Give the pixel the color (t/10, t/10, t/10):
imageData[linearIndex] = vec3(t / 10.0);
您现在应该能够构建和运行程序,并看到它out.hdr使用光线追踪渲染了康奈尔盒子的深度图!较暗的值距离较近,较亮的值较远。
如果应用程序无法构建或呈现错误,请对照您的代码main.cpp并raytrace.comp.glsl检查是否有任何拼写错误。

8.14 Summary
现在我们已经到了本章的结尾,我们终于构建了一个应用程序,它使用 Vulkan 光线追踪来渲染 3D 模型的深度图。我们已经完成了几乎所有的 C++ 代码,此时应该有大约 274 行长。
为了从本章中的仅缓冲区计算着色器转变为光线追踪器,我们:
- 使用从 OBJ 文件加载网格
tinyobjloader; - 将该网格上传到 GPU;
- 创建了一个 BLAS 和一个 TLAS 使用
nvvk::RaytracingBuilderKHR; - 将 TLAS 添加到描述符集中;和
- 改写了计算着色器来使用
rayQueryInitializeEXT,rayQueryProceedEXT和rayQueryGetIntersectionTEXT做光线投射。
在接下来的章节中,我们将看到如何主要修改 GLSL 代码以将其从深度图渲染器转变为路径追踪器。