关于小数在计算机内部存储造成精度误差
二进制在进行整型存储时非常精确,但是对于小数
比如0.7325
2-1=0.5
2-2=0.25
2-3=0.125
2-4=0.0625,
2-5=0.03125
…
0.7325=0.5+0.125+0.0625+0.03125+…
因为小数部分只能由2-1,2-2,2-3,2-4…构成( 计算机只能用这些个 1/(2^n) 之和来表达十进制的小数),但是因为计算机不可能提供无限的空间让程序去存储这些二进制小数,也就是不可能将小位数一直延申下去,这就必须省略掉一些极小的数,便会造成小数的不准确。
小数的存储
一个小数分正数部分和小数部分,在计算机中我们没办法在存储小数的时候灵活的规定小数点的位置,如果将一块内存空间划分成两块区域,一块用于正数部分的存储,一部分用于小数部分的存储,空间上并不灵活,还可能会造成极大的空间上的浪费。
所以我们采用科学计数的方法:
浮点数的机器格式分三个部分,数符(表示正负),阶码(表示通过科学计数小数点缩进的程度),尾数(科学计数后小数点后的所有数)
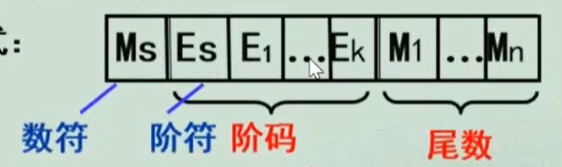
这种格式的非0浮点数真值为:(-1)数符 * 2阶码-127 * (1+尾数)
阶码只有八位(阶码表示的是指数为),尾数(23位)从第一位开始填,剩下的用0补齐
比如:
e1:
-(0.11)2,小数点右移,变成 -(1.1)* 2-1=-(1+0.1) * 2-1(-1是阶码真值,位数是0.1)
数符为1,阶码=阶码真值+127=-1+127=126=(01111110)2,尾数是0.10000…
所以答案就是1 01111110 10000…
e2:
11100.000112=1.110000011 * 24=(1+0.110000011) * 24
阶码=127+阶码真值=127+4=131
所以答案就是:0 10000011 110000011000…
根据存储方式我们可以得到
种类-------符号位-------------指数位----------------尾数位----
float—第31位(占1bit)—第30-23位(占8bit)----第22-0位(占23bit)
double–第63位(占1bit)—第62-52位(占11bit)—第51-0位(占52bit)
所以float的指数部分有8bit(2^8),由于是有符号型,所以得到对应的指数范围-128~128。
double的指数部分有11bit(2^11),由于是有符号型,所以得到对应的指数范围-1024~1024。
由于float的指数部分对应的指数范围为-128~128,所以取值范围为:
-2128到2128,约等于-3.4E38 — +3.4E38
代码实现浮点数存储形式的展现:
void show_bits_float(float* f)
{
int n = *(int*)f;
//f本来是float的指针类型,强制转换成int的指针类型,注意是指针类型的强制转换不是数值的强制转换
//然后再对int类型的指针取值赋给n
//操作原理:
// 不管是什么类型的指针变量,所存的值都是地址,声明不同类型的作用在于规定指针在内存中每次移动的字节数,int类型的指针和float类型的指针移动的字节数就不同
// 例如定义“int *pa = &a”,取值时,int类型占4个字节,指针就从首地址开始移动,读取4个字节。同理,short类型占2字节,指针就移动2字节。通过声明指针类型,告诉指针每次移动多少字节,来获取变量的值
//“值相同的两个指针变量”,意思是两个指针变量指向同一个首地址。但是如果指针变量的类型不同,因为指针移动的字节数量不同,就可能读取出不同的数据。
/*short a = 1;
short* p1 = &a;
int* p2 = (int*)p1;
printf("%d %d", *p1, *p2);
for (int i = 31; i >= 0; i--)
答案:1 -859045887 */
cout << ((n & (1 << i)) ? 1 : 0);
}
关于指针强制类型转换的理解参考这篇博客
用取地址符写也行:本质是一样的
void show_bits_float(float f)
{
int n = *(int*)(&f); // 直接找到f的地址这样,不用指针也行
for (int i = 31; i >= 0; i--)
cout << ((n & (1 << i)) ? 1 : 0);
}

int n = *(int*)f;因为括号() 优先级高于取值运算符*(指针变量),所以先进行(int*)f,再*取值,将与该float有着相同二进制的int类型的数赋值给n(n和f的二进制表示相同,都是32位,但是代表的数值不一样,为什么要这么转换呢,因为我们需要的位运算是有使用限制的)。
位运算是int型的操作,但是float在编译器里不允许位操作的,猜想是float的格式都是规定好的,位操作对原数据改动很大,而且一般情况下意义不大,例如int左移移位代表*2,float左移没有什么意义。那该怎么办呢?
数据和指令在内存中都是以01的方式存储的,计算机并不知道哪个是int,哪个是float,哪个是指令,内存中的数据解释成什么,还得靠我们来指定,例如我们定义一个int类型,相当于我们人为的将4个字节解释成int类型,如果你将这4个字节解释成float也可以,那么结果肯定会发生变化。
所以现在思路有了,先定义一个float类型的数,然后将其解释成int类型,然后再进行位操作取出所有的位,然后展示出来。
————————————————
原文链接:https://blog.csdn.net/wayway0554/article/details/84111889