https://github.com/jacobgil/pytorch-pruning
[ICLR’17]论文链接:https://arxiv.org/abs/1611.06440
这篇论文来自NVIDIA,论文中提出了一种用于修剪神经网络中的卷积核的新公式,以实现有效的推理。
剪枝之后的VGG准确率从98.7% 掉到97.5%.
网络大小从 538 MB压缩到 150 MB.
在i7 CPU上,对一张图的推断时间从 0.78 减少为 0.277 s,几乎是3倍加速。
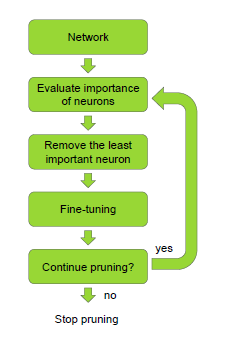
裁剪filter的依据是:
用Taylor展开来近似pruning的优化问题。
需要注意的是,裁剪某一层的filter后,下一层的weight也需要更新。
ref
https://blog.csdn.net/qq_23225921/article/details/78807652
https://blog.csdn.net/liujianlin01/article/details/80654681?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control