NS
机构
Tsinghua,Intel
【Pruning系列:二】Learning Efficient Convolutional Networks through Network Slimming|YOLOv3实践 |Pytorch 总结
motivation
训练中的剪枝
基于BN(Batch Normalization)层的广泛使用,在BN层加入channel-wise scaling factor 并对之加L1 regularizer使之稀疏,然后裁剪scaling factor值小的部分对应权重
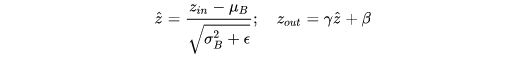
-
用 BN 层的 y 来表示卷积核的重要程度,y 小对应卷积核重要性低
γ 非常小时,送入下一层的值就非常小,可以直接剪掉
-
虽然可以通过删减 γ 值接近零的channel,但是一般情况下, γ 值靠近0的channel还是属于少数
于是作者采用 L1 or smooth-L1 惩罚 γ ,来让 γ 值倾向于0
method
目标函数:
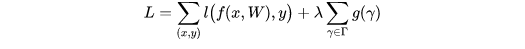
-
第一项是模型预测所产生的损失
-
第二项是用来约束γ的(引导稀疏的惩罚函数)
-
λ是权衡的超参,一般设置为1e-4 或者 1e-5
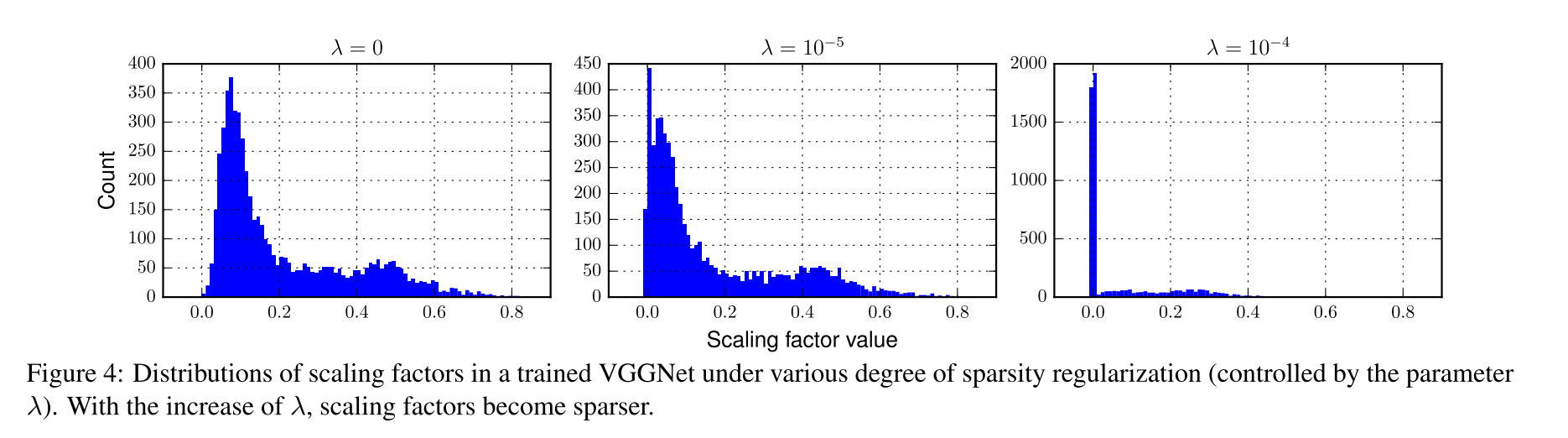
- λ为0的时候,目标函数不会对γ进行惩罚
- λ等于1e-5时,整体都向0靠近。
- λ=1e-4时,对γ有了更大的稀疏约束
-
g(*)采用的是g(γ)=|γ|(也可以采用 smooth L1在零点为光滑曲线)
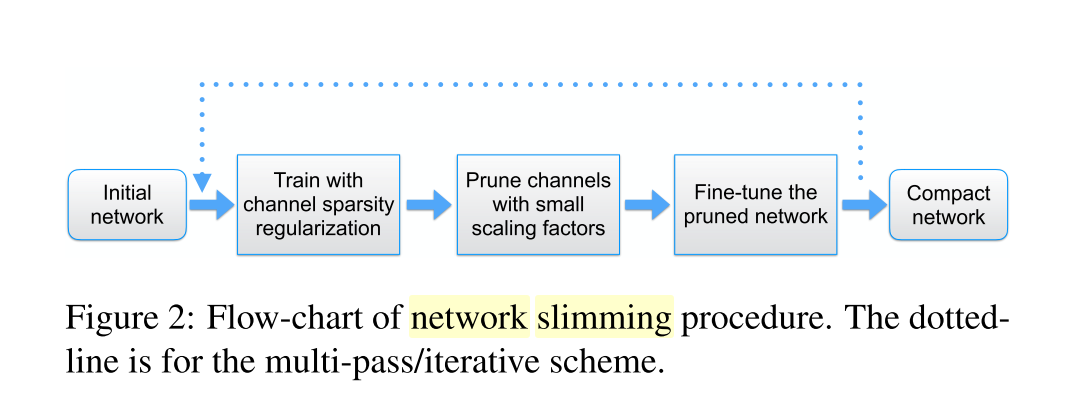
pipeline
- 初始化网络
- 稀疏化 y
- 根据 y 排序,基于统一的 prune rate 剪枝不重要的层(全局)
- fine tuning
- 回到第二步 实现多次精简网络
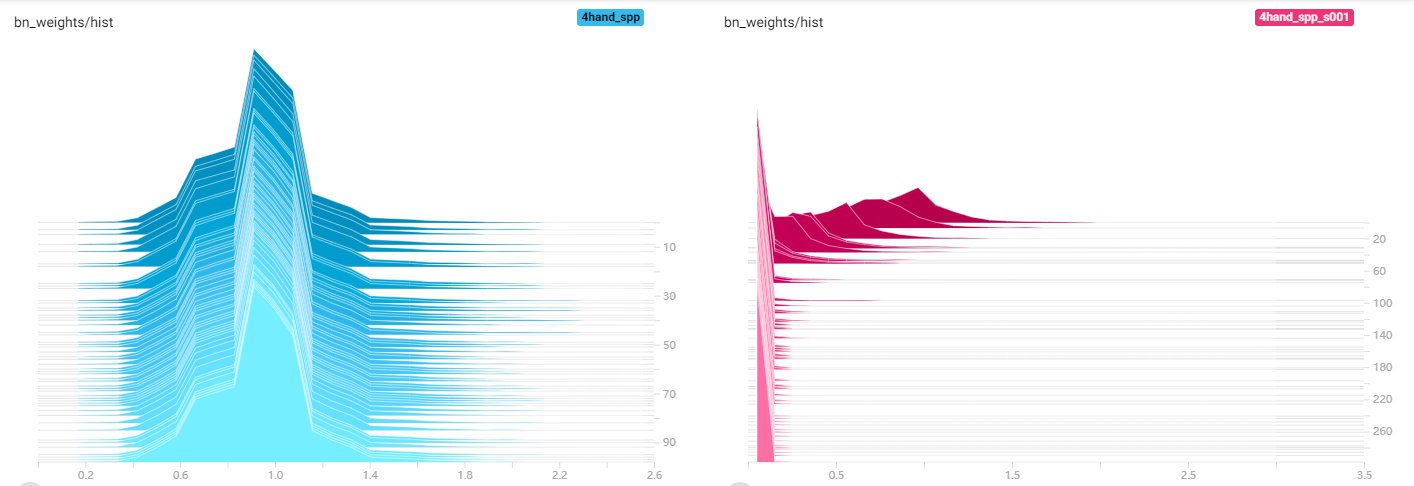
左图可以看到正常训练时Gmma总体上分布在1附近类似正态分布
右图可以看到稀疏过程Gmma大部分逐渐被压到接近0,接近0的通道其输出值近似于常量,可以将其剪掉
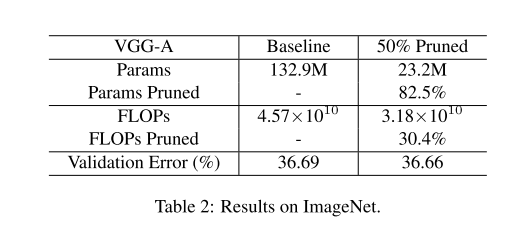
result