Networks Slimming-Learning Efficient Convolutional Networks through Network Slimming
2017年ICCV的一篇文章,属于channel pruning。
创新点:
- 利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(pruning)。
- 为约束γ的大小,在目标方程中增加一个关于γ的正则项,这样可以做到在训练中自动剪枝,这是以往模型压缩所不具备的。
Network slimming,利用BN层中的缩放因子γ,在训练过程当中来衡量channel的重要性,将不重要的channel进行删减,达到压缩模型大小,提升运算速度的效果。
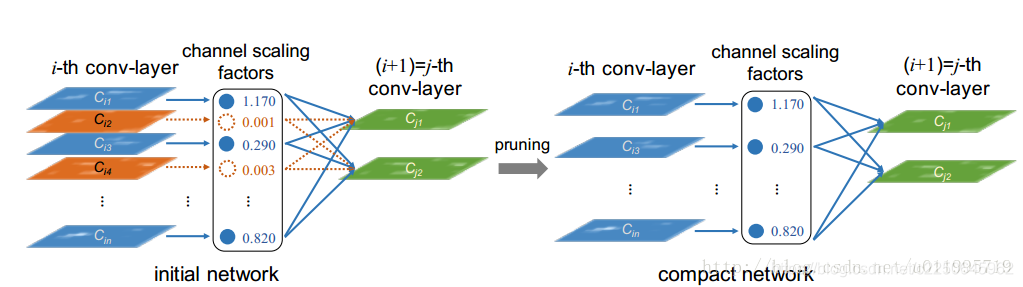
看一下模型图,左边为训练当中的模型,中间一列是scaling factors,也就是BN层当中的缩放因子γ,当γ较小时(如图中0.001,0.003),所对应的channel就会被删减,得到右边所示的模型。
目标函数如下:
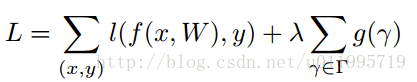
第一项是模型预测所产生的损失,第二项就是用来约束γ的,λ是权衡两项的超参,后面实验会给出,一般设置为1e-4 或者 1e-5。g(*)采用的是g(s)=|s|, 就是L1范,可达到稀疏的作用。
整体流程框图如下图所示:
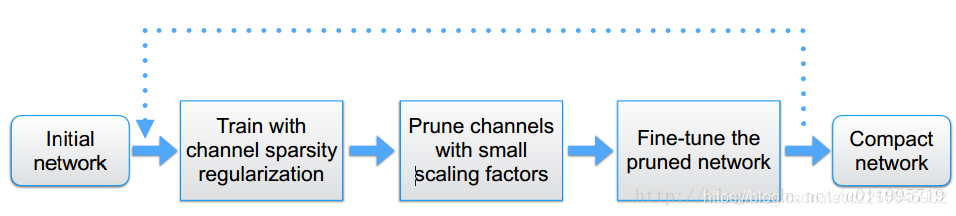
分为三部分,第一步,训练;第二步,剪枝;第三步,微调剪枝后的模型,循环执行。
具体操作细节:
γ通常取 1e-4或者1e-5,具体情况具体分析,
γ得出后,应该怎么剪,γ多小才算小? 这里采用与类似PCA里的能量占比差不多,将当前层的γ全都加起来,然后按从大到小的顺序排列,选取较大的那一部分,通常选取70%左右(具体情况具体分析)。
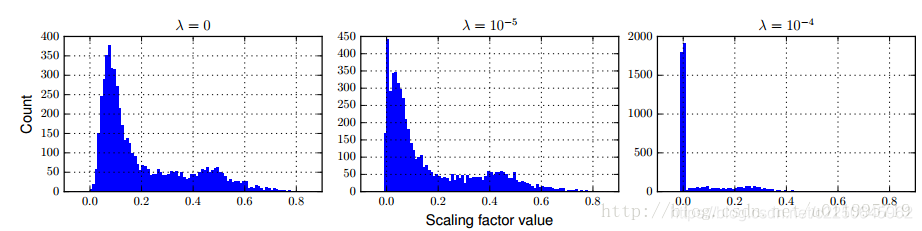
λ的选取对γ的影响如图所示: