《MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications 》
(一)论文地址:
《MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications 》
(二)解决的问题:
如今卷积神经网络已经证明了它在计算机视觉方向的优越性,越来越多的更深、更复杂的深度网络被提出来,准确率越来越高,而相应的这些网络在大小和处理速度上都没有更有效;
因此,在许多现实世界的应用中,比如机器人、无人驾驶、增强现实等,这些平台上往往都需要实时反馈和有限的计算能力,因此作者提出了
MobileNets 这一系列高效网络,实现了低延迟、高准确的平衡,可应用于多种视觉任务;
(三)
MobileNets 的核心思想:
MobileNets 的核心聚焦于实现一个低延迟、高效率的卷积神经网络,使其能够应用于各种计算能力有限的嵌入式系统中;

为此,作者提出了:
-
MobileNets 的网络结构,核心是将常规的卷积层分解成一个
depthwise
separable
convolutions(深度分离卷积层,简称
DWconv)和一个
pointwise
convolutions(即
1×1 卷积核大小的卷积层,简称
PWconv),从而有更小的参数,并且计算消耗更少;
- 两个网络模型构建的超参数(
hyper−parameters),用于轻松地根据嵌入式设备或平台的计算能力限制和任务需求,匹配合适的低延迟、高效率的网络结构;
(四)传统卷积的概念:
对于传统的卷积层(步长为
1 ),假设输入的特征图大小为
DF×DF×M,输出大小为
DF×DF×M(其中
Dk为特征图的宽度,
M、
N 是特征图的通道数),卷积核的宽度为
DK×DK,则图示表示为:
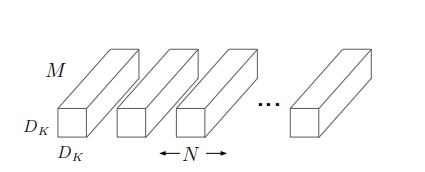
即卷积层的参数可表示为,大小为
DK×DK×M 的
N 组卷积;
此时参数量为:
DK×DK×M×N
卷积层的计算消耗为:
DK×DK×M×N×DF×DF
(五)
DWconv 的概念:
depthwise
separable
convolutions(深度分离卷积层,简称
DWconv)的核心是,不同于传统卷积方式,这里首先将特征图的每个
channel 分离,再分别用通道数为
1 的卷积核对特征图的每个
channel 分别做卷积;
假设输入的特征图大小为
DF×DF×M,卷积核的宽度为
DK×DK;
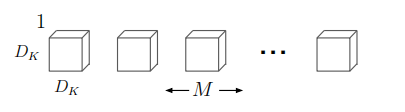
此时
DWconv 可以表示为,大小为
DK×DK×1 的
M 组卷积;
DWconv 的计算消耗为:
DK×DK×M×1×DF×DF
因此,
DWconv 的计算消耗仅为传统方式的
1/N 倍;
(六)
PWconv 的概念:
DWconv 存在的问题就是,输入输出特征图的通道数(
channels)必须相同,并且每个通道的输出是相互分离的;
为了解决这个问题,作者提出了使用
PWconv(即
1×1 卷积核大小的卷积层)来改变
DWconv 输出特征图通道数,并且将不同通道的输出进行线性融合;
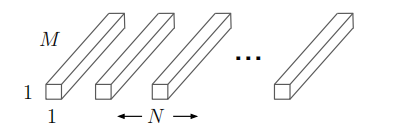
此时
PWconv 可以表示为,大小为
1×1×M 的
N 组卷积;
计算消耗为:
M×N×DF×DF
此时,对于一个传统卷积:
就可以将它转换成如图的结构:

(七)
MobileNets 的高效性:
由上可知,传统卷积的计算消耗为:
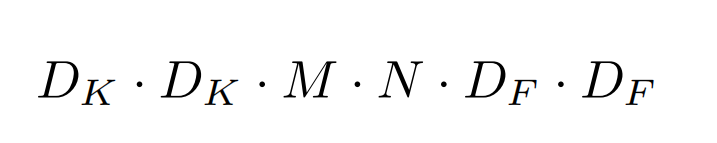
DWconv 加上
PWconv 代替传统卷积后的计算消耗为:
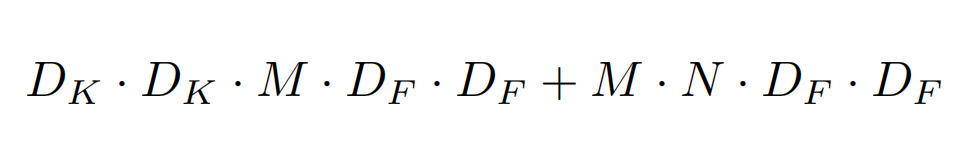
二者相比得:
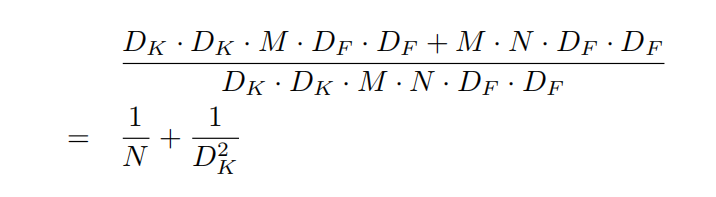
由于
N 远大于
DK2,而且在2014年的
ImageNet 中证明,小卷积核相比于大卷积核更有优势,故
DK2 通常为
3,因此
DWconv 加上
PWconv 的方法代替传统卷积,能够节省
8−9 倍的计算消耗,并且准确率下降很小;
同时由于
1×1 卷积不需要预先分配内存,因此可以快速地通过
GEMM(通用矩阵乘法)计算;
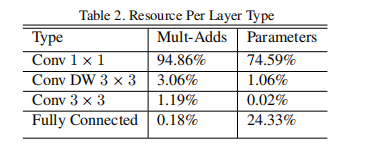
而且
MobileNets 中大部分的卷积都是
1×1 卷积,故大大提高了计算效率:
(七)
MobileNets 的网络结构:

需要注意的是,由于
MobileNets 注重于网络结构的高效性,参数较少,因此下采样没有采用
max
pooling 的方式,而是使用了
stride=2 的
DWconv 来实现;
并且参数较少也有效地防止了过拟合,因此
MobileNets 并不需要太多的数据增强或者正则化;
(八)
Width
Multiplier:更小的模型
作者提出的两个选择模型的超参数之一就是
Width
Multiplier,记为
α,用来进一步减小(或者说调整)
MobileNets 的大小;
对于一个给定的特征层,
α 可以取
1,0.75,0.5 之一,特征层的通道数
M 就变成了
α×M;
此时的计算消耗为:
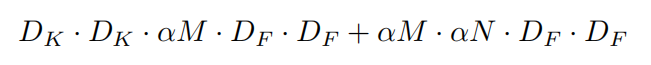
当
α=1 时就是一个典型的
MobileNets;
当
α<1 时,计算消耗大概减小为原来的
α2 倍;
(九)
Resolution
Multiplier:简化表示法
作者提出的第二个选择模型的超参数就是
Resolution
Multiplier,记为
β,用来进一步减小
MobileNets 的计算消耗;
对于一个给定的网络,
β 的取值范围为
(0,1],输入特征图的宽度
DF 就变成了
β×DF;
此时的计算消耗为:
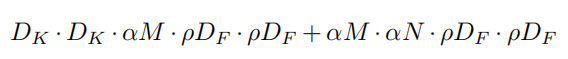
作者也列出了使用两个超参数之后,计算消耗的变化:

