论文《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》的完整翻译,如有翻译不当之处敬请评论指出,蟹蟹!(2019-10-17)
作者:Qilong Wang1, Banggu Wu1, Pengfei Zhu1, Peihua Li2, Wangmeng Zuo3, Qinghua Hu1
发表:暂未知
代码:https://github.com/BangguWu/ECANet
摘要
通道注意力在改善深度卷积神经网络(CNNs)性能方面具有巨大的潜力。然而,大多数现有的方法致力于开发更复杂的注意力模块,以获得更好的性能,不可避免地增加了计算负担。为了克服性能与复杂度权衡的悖论,本文尝试研究一种用于提高深度CNNs性能的超轻量级注意模块。特别地,我们提出了一个有效的通道注意(ECA)模块,它只涉及k (k<=9)参数,但带来了明显的性能增益。通过回顾SENet中的通道注意模块,我们实证地证明了避免降维和适当的跨通道交互对于学习有效的通道注意是重要的。因此,我们提出了一种无降维的局部跨通道交互策略,该策略可以通过快速一维卷积有效地实现。此外,我们开发了一个通道维数的函数来自适应地确定一维卷积的核大小,它代表了局域交叉通道相互作用的覆盖范围。我们的ECA模块可以灵活地整合到现有的CNN架构中,由此产生的CNN被ECA- Net命名。我们以ResNets和MobileNetV2为背景,在图像分类、目标检测和实例分割方面对提出的ECA-Net进行了广泛的评估。实验结果表明,与同类网络相比,ECANet具有更高的效率。源代码和模型可以在https://github.com/BangguWu/ECANet上找到。
介绍
深度卷积神经网络(CNNs)在人工智能中得到了广泛的应用,并在图像分类、目标检测和语义分割等广泛领域取得了很大的进展。从开创性的AlexNet 开始,许多研究被不断研究,以进一步提高深度CNNs的性能。近年来,将注意机制引入卷积块引起了人们的广泛关注,显示出了极大的性能改进潜力。在这些方法中,有代表性的作品之一是压缩-激励网络(SENet) 它对每个卷积块进行通道注意学习,在各种深度CNN架构上获得了明显的性能增益。
跟随在SENet中压缩和激励的设定,一些研究通过捕获更复杂的通道依赖来改进SE块或者结合额外的空间注意力。这些方法虽然取得了较高的精度,但往往带来较高的模型复杂度和较大的计算量。与上述以更高的模型复杂度为代价来获得更好的性能的方法不同,本文关注的是一个问题:能否以更有效的方式学习有效的注意力渠道?
为了回答这个问题,我们首先回顾SENet中的通道注意模块。具体来说,给定输入特征,SE块首先对每个通道独立使用全局平均池,然后使用两个非线性的全连接(FC)层和一个s形函数生成每个通道的权值。这两个FC层的设计是为了捕获非线性的跨通道交互作用,其中包括降维以避免过高的模型复杂度。虽然该策略被广泛应用于后续的通道注意模块,我们的实证分析表明降维会对渠道关注度的预测产生副作用,而且对所有渠道的相关性进行捕获是低效且不必要的。

图1:各种注意力模块SENet、CBAM的比较,以ResNets为骨干模型,在准确率、网络参数、FLOPs方面。圆的大小表示模型计算(FLOPs)。显然,我们的ECA-Net在模型复杂度较低的同时,获得了较高的精度。

图2:(a) SE块和(b)我们的有效通道注意力(ECA)模块的比较。给定使用全局平均池(GAP)的聚合特性,SE块使用两个FC层计算权重。与之不同的是,ECA通过执行大小为k的快速一维卷积来生成通道权值,其中k通过通道维C的函数自适应地确定。
在此基础上,提出了避免降维和适当的跨通道交互作用对建立通道注意机制的重要性。因此,本文提出了一种针对深度CNNs的有效通道注意(ECA)模块。如图2 (b)所示,在没有降维的情况下,通过考虑每个通道及其k个邻居,我们的ECA捕获了本地跨通道交互。因此,我们的ECA可以通过大小为k的快速一维卷积来有效地实现,有多少邻居参与一个通道的注意预测。显然,这将影响ECA的效率和效力。交互覆盖率与通道维数有关是合理的,因此我们提出了一个与通道维数相关的函数自适应确定k。如图1和表2所示,与主干模型相反,使用ECA模块的深层CNNs(称为ECA- Net)引入很少的额外参数和可忽略的计算,同时带来显著的性能提升。例如,对于参数为24.37M、GFLOPs的ResNet-50, ECA-Net50的附加参数和计算分别为80和4.7e-4 GFLOPs;与此同时,ECA-Net50在排名前1的准确率上比ResNet50高出2.28%。为了评估我们的方法,我们使用不同的深度CNN架构和任务,在ImageNet-1K和MS COCO上进行了实验。本文的贡献总结如下。
-我们的经验表明,避免降维和适当的跨通道交互对于学习有效的深度CNNs通道注意是重要的。
-我们提出了一种新型的高效通道注意(ECA),尝试为深度CNNs开发一种非常轻量级的通道注意模块,该模块增加的模型复杂度很小,但带来了明显的改进。
-在ImageNet-1K和MS COCO上的实验结果表明,我们的方法比最先进的方法具有更低的模型复杂性,同时获得了非常有竞争力的性能。
相关工作
注意机制已被证明是增强深度CNNs的潜在手段。SE-Net首次提出了一种有效的通道注意学习机制,取得了良好的效果。随后,注意模块的开发大致可以分为两个方向:(1)增强特征聚合;(2)通道与空间注意相结合。具体来说,CBAM使用平均池化和最大池化来聚合特性。GSoP引入了一个二阶池化来实现更有效的特性聚合。GE利用深度卷积来对特征进行空间扩展。scSE和CBAM利用核大小为k×k的二维卷积计算空间注意,然后将其与通道注意结合起来。双注意网络与非局部神经网络有着相似的思想,它引入了一种新的图像或视频识别关系函数,而双注意网络(DAN)和交叉网络(CCNet)同时考虑非局部通道和非局部空间注意进行语义分割。类似地,Li等人提出了一个期望最大化注意(EMA)模块用于语义分割。然而,这些非局部注意模块由于模型复杂度高,只能在一个或几个卷积块中使用。显然,以上所有方法都侧重于开发复杂的注意力模块以获得更好的性能。与他们不同的是,我们ECA的目标是学习有效的通道注意力,同时降低模型的复杂性。
我们的工作还涉及到高效卷积,它是为轻量级CNN架构设计的。最常用的两种高效卷积是群卷积和深度可分卷积。如表1所示,虽然这些有效的卷积所涉及的参数较少,但在注意模块上的有效性并不明显。ECA模块的目标是捕获局部的跨通道交互,它与通道局部卷积和通道wise卷积有一些相似之处;与之不同的是,我们的方法侧重于提出一个具有自适应核大小的一维卷积来代替通道注意模块中的FC层。与群卷积和深度可分卷积相比,该方法在模型复杂度较低的情况下取得了较好的效果。
表1:以ResNet-50为骨干的ImageNet各通道注意模块对比参数。表示每个通道注意模块所涉及的参数数。O意味着点乘。GC和C1D分别表示群卷积和1D卷积。k是C1D的核大小。
提出的方法
在本节中,我们首先回顾SENet中的通道注意模块。然后,我们进行了实证比较,分析了降维和跨通道互动的影响,这促使我们提出了有效的通道注意(ECA)模块。此外,我们介绍了一个自适应的内核大小选择为我们的ECA和最后显示如何采用它的深度CNNs。
回顾通道注意力机制
令一个卷积块的输出为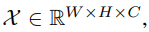 其中W、H、C分别为宽度、高度、通道尺寸。如图2(a)所示,SE块中通道注意权值计算为:
其中W、H、C分别为宽度、高度、通道尺寸。如图2(a)所示,SE块中通道注意权值计算为: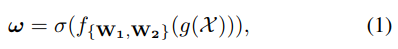
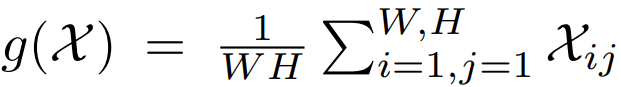
该公式是是全局平均channel-wise池化(GAP),σ是一个s形的函数。令y=g(X),f{W1,W2}采用这种形式: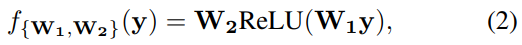
其中ReLU表示经过整流的线性单元。为了避免模型复杂度过高,将W1和W2的大小分别设置为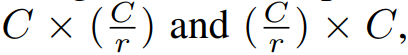
可以看出,f{W1,W2}包含了通道注意块的所有参数。虽然等式2的降维可以降低模型的复杂度,但是它破坏了通道与其权值之间的直接对应关系。
有效的通道注意模块
在本节中,我们将通过实证比较,深入分析通道降维和跨通道交互对学习通道注意的影响。根据这些分析,我们提出了有效的通道注意(ECA)模块。
避免降维 如前所述,等式2的降维使得通道与其权重之间的对应是间接的。为了验证它的效果,我们将原始的SE块与它的三个变体进行了比较,这三个变体都没有进行降维。从表1可以看出,没有参数的SE-Var1仍然优于原网络,说明通道注意有能力提高深度CNNs的性能。同时SE- var2独立学习每个通道的权值,在参数较少的情况下略优于SE块。这可能表明,通道及其权值需要直接对应,而避免降维比考虑非线性通道相关性更重要。此外,使用单个FC层的SE- var3在降维的SE块中比两个FC层的性能更好。以上结果清楚地说明了在注意模块中避免降维的重要性。因此,我们开发的ECA模块没有降低通道维数。
局部跨通道交互 虽然SEVar2和SE-Var3都保持通道维数不变,但后者的性能更好。主要的区别是SE-Var3捕获跨通道交互,而SEVar2不捕获。这说明跨通道互动有助于学习有效注意。但是SE-Var3涉及大量的参数,导致模型复杂度过高。从有效卷积的角度来看,SE-Var2可视为深度可分离卷积(Chollet 2017)。自然,组卷积作为另一种有效的卷积,也可以用来捕获跨通道交互。给定一个FC层,组卷积将它分成多个组,并在每个组中独立地执行线性变换。组卷积的SE块(SE- gc)写为: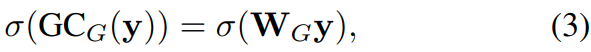
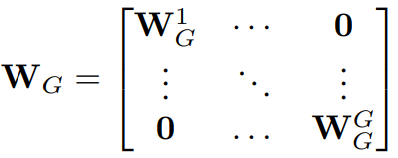 为块对角矩阵,其参数个数为
为块对角矩阵,其参数个数为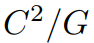 G是组的数目。但是,如表1所示,不同分组的SE-GC并没有带来超过SE-Var2的增益,这说明分组卷积并不是一种有效的跨通道交互利用方案。同时,过多的组卷积会增加内存访问成本。
G是组的数目。但是,如表1所示,不同分组的SE-GC并没有带来超过SE-Var2的增益,这说明分组卷积并不是一种有效的跨通道交互利用方案。同时,过多的组卷积会增加内存访问成本。
通过可视化通道特征y,我们发现它们通常表现出一定的局部周期性(详见附录A1)。因此,与上述方法不同,我们的目标是捕获局部的跨通道交互,即只考虑每个通道与其k近邻之间的相互作用。因此,yi的权重可以计算为: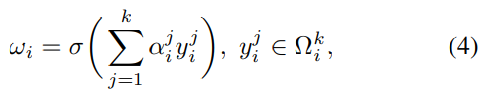
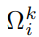 表示yi的k个相邻通道的集合。显然,等式4捕获了局部跨通道交互,而这种局部性约束避免了跨所有通道的交互,从而允许较高的模型效率。这样,每个通道的注意力模块就会涉及k∗C参数。为了进一步降低模型复杂度和提高效率,我们让所有的通道共享相同的倾斜参数,如下公式:
表示yi的k个相邻通道的集合。显然,等式4捕获了局部跨通道交互,而这种局部性约束避免了跨所有通道的交互,从而允许较高的模型效率。这样,每个通道的注意力模块就会涉及k∗C参数。为了进一步降低模型复杂度和提高效率,我们让所有的通道共享相同的倾斜参数,如下公式: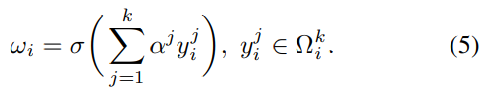
因此,我们的高效通道注意(ECA)模块可以很容易地通过与k的核大小的快速1D卷积来实现,如下: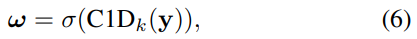
其中C1D表示一维卷积。如表1所示,通过引入本地跨通道交互,我们的ECA在Eq4中的SE-var3和ECA- ns得到了类似的结果,但模型复杂度要低得多(只涉及k个参数)。在表1中,k被设置为3。
核大小k的自适应选择 在我们的ECA模块(等式6)中,内核大小k是一个关键参数。由于使用1D卷积来捕获局部的跨通道交互,k决定了交互的覆盖范围,不同的通道数和不同的CNN架构的卷积块可能会有所不同。尽管k可以手动调优,但它将消耗大量计算资源。k与通道维数c有关,这是合理的。一般认为,通道尺寸越大,长期交互作用越强,而通道尺寸越小,短期交互作用越强。换句话说,之间可能存在某种映射φk和C:
在这里,最优配方的映射φ通常是未知的。然而,基于上述分析,k与C成非线性比例,因此参数化指数函数是一个可行的选择。同时,在经典的核技巧中,作为核函数的指数族函数(如高斯)被广泛用于处理未知映射问题。因此,我们使用一个指数函数近似映射φ,如下: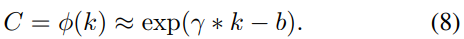
此外,由于通道维C通常设置为2的整数次幂,所以我们用 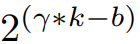 代替
代替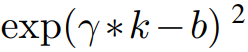
然后,给定通道维C,自适应确定内核大小k: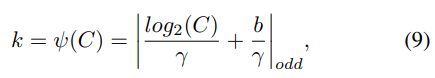
这里 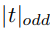 表示最近的奇数t。在这篇文章中,我们将γ和b 2和1,分别。显然,映射函数ψ使大渠道的长期相互作用,反之亦然。
表示最近的奇数t。在这篇文章中,我们将γ和b 2和1,分别。显然,映射函数ψ使大渠道的长期相互作用,反之亦然。
深度卷积神经网络的ECA
图2比较了ECA模块和SE模块。为了采用我们的ECA来深度CNNs,我们使用了与SENet完全相同的配置,只是用ECA模块替换了SE块。得到的网络由ECA-Net命名。图3给出了我们ECA的PyTorch代码,很容易复制。
实验
在本节中,我们分别使用ImageNet (Deng et al. 2009)和MS COCO (Lin et al. 2014)对提出的大规模图像分类和目标检测方法进行了评估。具体来说,我们首先评估内核大小对ECA模块的影响,并与ImageNet上的最新版本进行比较。然后,我们使用Faster R-CNN (Ren et al. 2017)和Mask R-CNN (He et al. 2017)验证了ECA模块对目标检测的有效性。
实现细节
为了在ImageNet分类上评估我们的ECA-Net,我们使用了三种广泛使用的CNNs作为骨干模型,包括ResNet-50 (He et al. 2016a)、ResNet-101 (He et al. 2016a)、ResNet-152 (He et al. 2016a)和MobileNetV2 (Sandler et al. 2018)。为了与我们的ECA训练ResNet-50、ResNet-101和ResNet-152,我们采用完全相同的数据扩充和超参数设置(He et al. 2016a;胡,沈,孙2018)。其中,输入图像随机裁剪为224×224,随机水平翻转。采用随机梯度下降法(SGD)优化网络参数,权值衰减为1e-4,动量为0.9,小批量尺寸为256。通过将初始学习率设置为0.1,所有模型在100 epoch内进行训练,每30 epoch减少10倍。为了与我们的ECA一起培训MobileNetV2,我们遵循(Sandler et al. 2018)中的设置,其中网络使用SGD在400个epoch内进行训练,权重衰减为4e-5,动量为0.9,小批尺寸为96。初始学习率设置为0.045,线性衰减率为0.98。在验证集上进行测试时,首先将输入图像的短边调整为256,并使用中心裁剪224×224进行评估。所有模型都由PyTorch toolkit实现。
我们进一步使用Faster R-CNN (Ren et al. 2017)和Mask R-CNN (He et al. 2017)对MS COCO的方法进行评价,其中以ResNet-50和ResNet-101以及FPN (Lin et al. 2017)为骨架模型。我们使用MMDetection toolkit (Chen et al. 2019)实现所有的检测器,并使用默认设置。具体来说,将输入图像的短边调整到800,然后使用SGD对所有模型进行优化,权值衰减为1e-4,动量为0.9,小批量大小为8(每个GPU有4个GPU,每个GPU有2个图像)。初始化学习率为0.01,经过8个epoch和11个epoch后,学习率分别降低了10倍。我们在COCO的train2017上对所有的检测器进行了12个epoch的训练,并在val2017上报告结果进行对比。所有程序运行在一台配备了4个RTX 2080Ti gpu和一个Intel® Xeon Silver 4112 [email protected]的PC上。
基于ImageNet-1K的大规模图像分类
在这里,我们首先访问了内核大小对ECA模块的影响以及自适应内核大小选择的有效性,然后使用ResNet-50、ResNet-101、ResNet-152和MobileNetV2与最先进的同类模型和CNN模型进行比较。
核大小的影响和自适应核大小的选择
如等式6所示,我们的ECA模块涉及一个参数k,即一维卷积的核大小。在这一部分,我们评估了它对ECA模块的影响,并验证了所提出的内核大小自适应选择的有效性。为此,我们采用ResNet-50和ResNet-101作为骨干模型,并通过我们的ECA模块对它们进行训练,设置k为3到9。结果如图4所示,从中我们得到了以下观察结果。
首先,当k在所有卷积块中固定时,ECA模块分别在ResNet-50和ResNet-101的k = 9和k = 5处得到最佳结果。由于ResNet-101有更多的中间层,这些中间层控制着ResNet-101的性能,所以它可能更喜欢小内核大小。此外,这些结果表明,不同深度的CNNs具有不同的最佳k值,k对ECA-Net的性能有明显的影响。其次,我们的自适应核大小选择试图为每个卷积块找到最优的k个数,这样可以缓解深度CNNs的深度影响,避免参数k的手动调整,而且通常会带来进一步的改善,证明了自适应核大小选择的有效性。最后,不同k值的ECA模块的学习效果始终优于SE块,说明避免降维和局部跨通道交互确实对学习通道注意产生了积极的影响。
比较使用ResNet-50 接下来,我们将ECA模块与几种使用ResNet-50在ImageNet上的最先进的注意力方法进行比较,包括SENet (Hu, Shen,和Sun, 2018)、CBAM (Woo等,2018)、A2-Nets (Chen等,2018)、AA-Net (Bello等,2019)和gsopi - net1 (Gao等,2019)。评估指标同时涉及效率(即、网络参数、每秒浮点运算次数(FLOPs)、训练/推理速度和效率(即(/前5的准确性)。为了公平的比较,我们复制了所有比较方法的结果,除了训练/推理速度。为了测试各种模型的训练/推理速度,我们使用公共可用的模型来比较CNNs,并在相同的计算平台上运行它们。结果如表2所示,我们可以看到我们的ECA-Net具有几乎相同的模型复杂度(即与原ResNet-50相比,提高了2.28%,在精度上达到了Top-1。与最先进的同类产品(即、SENet、CBAM、A2 - net、AA-Net和gsopi - net1), ECA-Net获得更好的或有竞争力的性能,同时受益于更低的模型复杂性。
比较使用ResNet-101 使用ResNet-101作为骨干模型,我们将我们的ECA-Net与SENet (Hu, Shen, and Sun 2018)、CBAM (Woo等人2018)和AA-Net (Bello等人2019)进行比较。从表2中我们可以看出,ECA-Net的准确率在前1名的基础上比原来的ResNet-101高1.8%,模型复杂度几乎相同。在ResNet-50上有相同的趋势,ECA-Net优于SENet和CBAM,而与模型复杂度较低的AA-Net具有很强的竞争力。
比较使用ResNet-152 使用ResNet-101作为骨干模型,我们将我们的ECA-Net与SENet (Hu, Shen,和Sun 2018)进行比较。从表2可以看出,ECA-Net在模型复杂度几乎相同的情况下,将原来的ResNet-152的Top-1准确率提高了约1.3%,而在模型复杂度较低的情况下,将SENet的Top-1准确率提高了0.5%。关于ResNet 50、ResNet-101和ResNet-152的结果证明了ECA模块在广泛使用的ResNet体系结构上的有效性。
比较实用MobileNetV2 除了ResNet架构,我们还验证了ECA模块在轻量级CNN架构上的有效性。为此,我们采用MobileNetV2 (Sandler et al. 2018)作为骨干模型,并将ECA模块与SE block进行比较。具体来说,我们在MobileNetV2的每个“瓶颈”中都有剩余连接之前,将SE块和ECA模块集成在卷积层中,并将SE块的参数r设为8。所有的模型都使用完全相同的设置进行训练。表2中的结果显示,我们的ECA-Net分别将原来的MobileNetV2和SENet的准确度提高了0.9%和0.14%,分别排在前1位。此外,与SENet相比,我们的ECA-Net具有更小的模型尺寸和更快的训练/推理速度。以上结果再次证明了ECA模块在深度CNNs中的有效性和高效性。
比较其他的CNN模型 在这一部分的最后,我们将我们的ECA-Net与其他最先进的CNN模型进行比较,包括ResNet-152 (He et al. 2016a)、SENet-152 (Hu, Shen, and Sun 2018)、ResNet-200 (He et al. 2016b)、ResNeXt (Xie et al. 2017)和DenseNet264 (Huang et al. 2017)。这些CNN模型具有更深入、更广泛的架构,其结果均来自于原始论文。如表3所示,我们的ECA-Net50与ResNet-152相当,而ECA-Net101的性能优于SENet-152和ResNet-200,说明我们的ECA-Net可以大大降低计算成本,提高深度CNNs的性能。同时,我们的ECA-Net101与ResNeXt-101相比有很强的竞争力,而ResNeXt-101使用了更多的卷积滤波器和昂贵的组卷积。另外,ECA-Net50可以与DenseNet-264相媲美,但是它的模型复杂度较低。以上结果显示,我们的ECA-Net较先进的CNNs表现良好,同时大大降低了模型的复杂性。值得注意的是,我们的ECA也有很大的潜力来进一步提高CNN模型的性能。
MS COCO目标检测
在本小节中,我们使用Faster R-CNN (Ren等,2017)和Mask R-CNN (He等,2017)对我们的ECA-Net进行目标检测任务评估。在这里,我们比较我们的ECA-Net与原来的ResNet和SENet。所有的CNN模型首先在ImageNet上进行预训练,然后通过微调转移到MS COCO。
比较使用Faster R-CNN 使用Faster R-CNN作为基本的检测器,我们使用50层和101层的ResNets和FPN (Lin et al. 2017)作为骨干模型。如表4所示,无论是集成SE块还是我们的ECA模块,都可以显著提高对象检测的性能。同时,在使用ResNet-50和ResNet-101时,ECA的AP分别比SE block高0.3%和0.7%。此外,我们的ECA模块比SE模块具有更低的模型复杂度。值得一提的是,我们的ECA模块为小对象实现了更多的增益,这些小对象通常很难被检测到。
比较使用 Mask R-CNN 我们进一步利用Mask R-CNN来验证我们的eca网络在目标检测任务上的有效性。如表4所示,在50层和101层设置下,ECA模块的AP分别比原始ResNet高1.8%和1.9%。同时,ECA模块使用ResNet-50和ResNet-101分别比SE模块提高了0.3%和0.6%。表4的结果表明,我们的ECA模块可以很好地推广到对象检测,更适合小对象的检测。
MS COCO的实例分割
最后,我们给出了实例分割的结果,我们的ECA模块使用Mask R-CNN在MS COCO上。与表5相比,ECA模块在模型复杂度较低的情况下,在性能优于SE块的同时,比原来的ResNet有了显著的提高。这些结果验证了ECA模块对各种任务具有良好的泛化能力。
结论
本文针对模型复杂度较低的深度CNNs,重点研究其学习通道注意问题。为此,我们提出了一种新的有效通道注意(ECA)模块,该模块通过快速一维卷积产生通道注意,其核大小可由通道维数的函数自适应确定。实验结果表明,我们的ECA是一个非常轻量级的即插即用模块,可以提高各种深度CNN架构的性能,包括广泛使用的ResNets和轻量级的MobileNetV2。此外,我们的ECA-Net在目标检测和实例分割任务中具有良好的泛化能力。未来,我们将在更多的CNN架构中采用ECA模块(如ResNeXt和Inception (Szegedy et al. 2016)),并进一步研究ECA与空间注意模块之间的交互作用。
附录A1。卷积激活的全局平均池的可视化
在这里,我们可视化了卷积激活的全局平均池化的结果,这些卷积激活被输入到用于学习通道权重的注意模块。具体来说,我们首先在ImageNet的训练集上训练ECA-Net50。然后,我们从ImageNet验证集中随机选择一些图像。给定一个选中的图像,我们首先通过ECANet50获得它,然后计算来自不同卷积层的激活的全局平均池化。选中的图像见图6的左侧和我们想象的全局平均池化激活值计算从conv 2 3, conv 3 2, conv 3 4, conv 4 3 conv 4 6和conv 5 3 2 3表示的差距,差距3 2 3 4的差距,差距4 3,分别差距4 5 6和差距3。这里,conv23表示第2阶段的第3个卷积层。如图6所示,我们可以观察到不同的图像在同一个卷积层中有相似的趋势,而这些趋势通常表现出一定的局部周期性。其中一些是用红色矩形框表示的。这一现象可能意味着我们可以以一种局部的方式来捕获通道的相互作用。
附录A2。通过ECA模块和SE模块学习权重的可视化
为了进一步分析ECA模块对学习通道注意力的影响,我们将ECA模块学习到的权重可视化,并与SE模块进行比较。这里,我们使用ResNet-50作为骨干模型,并举例说明不同卷积块的权值。具体来说,我们从ImageNet中随机抽取了四类,分别是锤头鲨、救护车、药箱和冬南瓜。图5显示了一些示例图像。对网络进行训练后,对从ImageNet验证中收集到的每个类的所有图像,平均计算卷积块的通道权值。图7显示了conv i j的通道权值,其中i表示第i个阶段,j表示第i个阶段的第j个卷积块。除了4个随机采样类的可视化结果外,我们还给出了1K类的平均权值分布作为参考。ECA模块和SE块学习的通道权值分别显示在每行的底部和顶部。
从图7中可以看到以下结果。首先,对于ECA模块和SE块,不同类的通道权值在较早的层(即,从conv 21到conv 3 4),这可能是由于较早的层目标是捕捉基本元素(如边界和角落)(Zeiler和Fergus 2014)。对于不同的类,这些特性几乎是相似的。这种现象在(Hu, Shen, and Sun 2018)4的扩展版本中也有描述。其次,对于SE块学习到的不同类的通道权值,它们大多趋于相同(即在conv 4 2∼conv 4 5中,不同的类之间的差异不是很明显。相反,ECA模块学习到的权重在不同的通道和课程中明显不同。由于第4阶段的卷积块更倾向于学习语义信息,所以ECA模块学习的权值可以更好的区分不同的类。最后,卷积在最后一个阶段(即。3)捕获高级语义特征,它们更具有类特异性。显然,ECA模块学习的权重比SE模块学习的权重更具有类特异性。以上结果清楚地表明,我们ECA模块学习到的权值具有更好的识别能力。