标题翻译:基于渐进式注意力指导循环网络的显著性目标检测。
梗概:这是一篇结合了注意力机制、循环神经网络、CNN来解决显著性目标检测问题的文章,文中提出的对深度卷积网咯的感知特征做另一种方式的自顶而下(top to shadow)的反馈操作是非常新颖的。
关于此文的论文原文与小编的阅读注释,与讲解PPT见:
链接:https://pan.baidu.com/s/1KGHrY7deAGdQ6dU-2d3YnA 密码:sfvs
小编阅读过的论文中有另一种利用深度感知特征直接自顶而下生成图像的做法,见另一博文论文笔记:Visual Attribute Transfer through Deep Image Analogy。
(一)解决的问题
视觉注意机制(Visual Attention Mechanism,VA),即面对一个场景时,人类自动地对感兴趣区域进行处理而选择性地忽略不感兴趣区域,这些人们感兴趣区域被称之为显著性区域。
关键字:位置(Position);区域(Region)

视觉显著性检测(Visual saliency detection)指通过智能算法模拟人的视觉特点,提取图像中的显著区域(即人类感兴趣的区域)。

(二) 动机
作者说,在目标显著性监测这个领域,存在着以下的不足——
深度学习之前——传统的方法仅仅是结合了人自定义的、低level的的特征:如颜色、强度、对比度等。
深度学习——尽管使用CNN能够自动的提取出图像的不同级别的高度抽象、高纬度的特征;但对于这些不同level的特征的继承方法则仅是把多层(top to shadow layers)特征机械地整合在一起,并很少考虑到——
1)不同level的特征的相互关系;
2)同一个level的特征不同channels之间的相互关系;
3)同一channel的在HW平面的不同位置(Spatial)的相互关系(这是由图像上的显著性区域往往只占领图像的一部分造成的)。
作者认为,
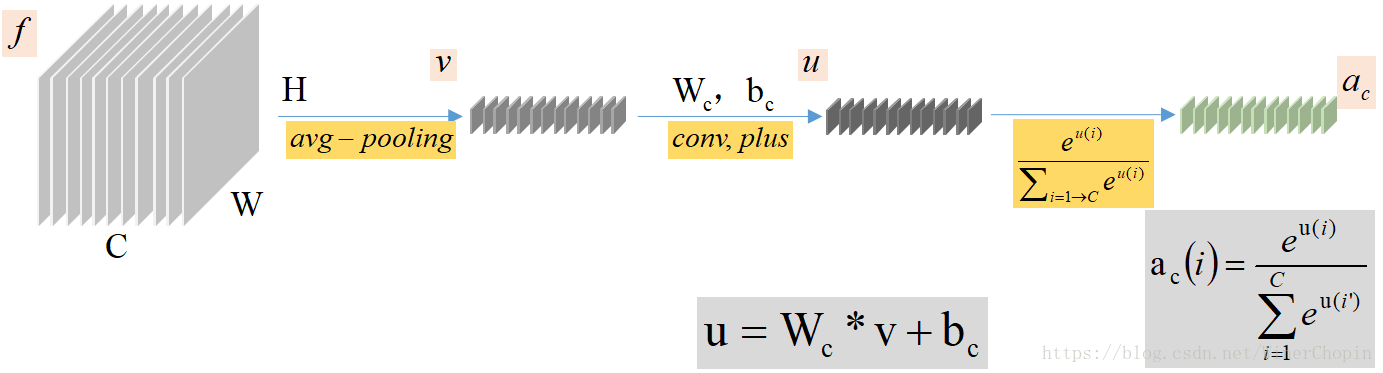
1. 给定某一个Layer的特征F的size为 CxHxW,在HW平面各个位置的重要程度可能不同。因为显著性区域在图片中只占一部分。于是提出了:Spatial Attention (SA)(空间注意力机制)。

2. 在C维度,不同的channels对前景FG和背景BG的响应程度可能不同。于是提出了:Channel-wise Attention (CA)(通道上的注意力机制)。
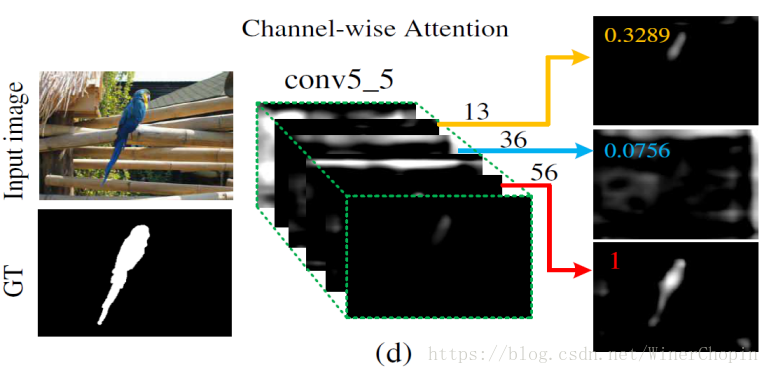
(三)相关工作
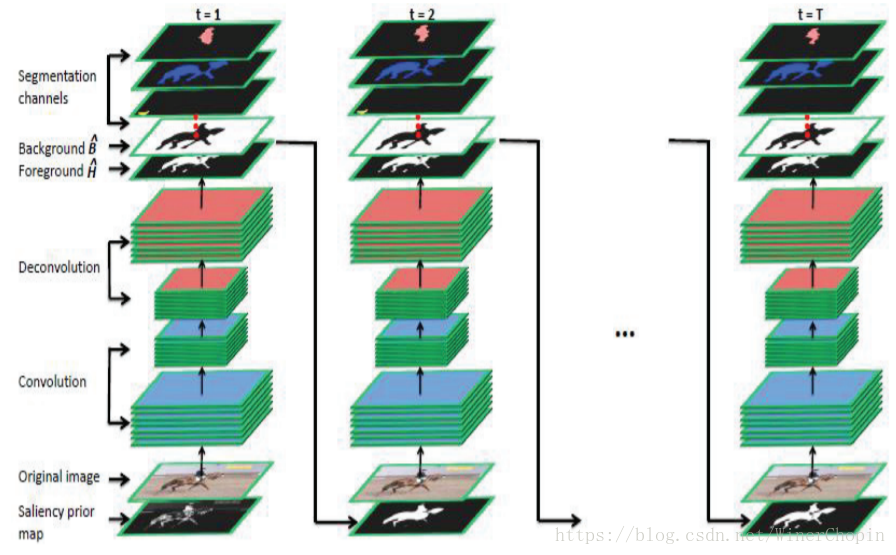
小编这里只列举了非常相似的一个工作:RFCN。
如下图所示:其工作原理为,上一个step的输出(Saliency mask)(作为注意力Attention)用于下一个step与原图一同输入。但是,由于把mask直接与Raw img的原图concatenate在一起,极大地削弱了mask的指导效果。
(四)贡献
提出了多路循环反馈(feedback)模块,能够把顶层的抽象语义信息反馈到浅层,来达到调整整个网络框架的目的。
MultiPath Recurrent Guidance Module 多路循环引导模块
提出了新的注意力机制,能够生成更有效的强大的注意力特征。
SA: Spatial Attention Mechanism 基于空间(HW平面)的注意力机制
CA: Channel-wise Attention Mechanism 在C维度上的注意力机制
提出了渐进式注意力模块,能够选择性地集成多层特征的多重上下文信息。
a progressive attention driven framework 渐进式注意力驱动框架
(五)原理
0. Overview

1. MultiPath Recurrent Guidance Module
为了将top的global信息反馈回low layers以引导底层提取更有用的显著性信息。

我们知道,在深度卷积网络中,图像经过主干特征提取网络得到一系列不同levels的感知特征,普遍认为,越高的层具备更多语义信息(即“是什么”),越少的细节信息;越低的层具备更多的细节信息与更少的语义信息。
同时,越高层,其感受野越大,具备的信息也就越Global!
因此,我们可以利用top layer的特征对图像object的语义的理解与对object在全局的位置的把握,反馈回到shadow layers,从而引导我们的网络更准确地注意到目标所在的显著性区域!
好,基于上面的理解,我们可以接受为什么作者要这么做的,下面我们着重关注具体的原理——Recurrent Network!
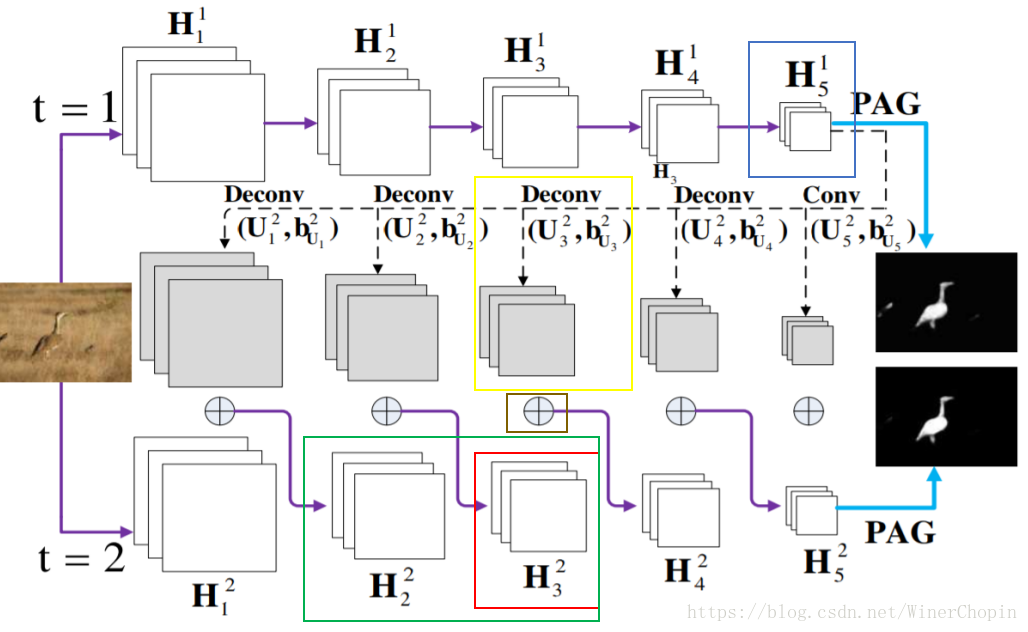
如上图所示(每一个时间step要横着看),我们用上一个time step的最后的输出()通过反卷积(Deconv)转为与前面各个层相同size,与当前time step的对应层的特征相加。计算公式如下:

注意颜色框对应的图的区域。
其中,
是普通的基于这个time step的上一层卷积的输出作为输入进行一次卷积操作,获得当前time step的下一层的输出。注意这里的卷积参数
是所有time step共享的,这是RNN的特点之一!
则是利用上一个time step的最顶层输出作为输入进行卷积操作,获得输出。注意这里的卷积参数
则是在不同的time step和不同层之间是不一样的,这是因为我们希望这个学习过程是可以动态优化着。
是一些激活函数、pooling操作的集合。
则是表示正则化(文章使用的是 l2 normlization)。
2. Two Attention Mechanism
先分别求出在HW平面上的Spatial的注意力mask:,和在C维度上的衡量各个channels的重要性的长向量
。
1)SA:Spatial Attention Mechanism
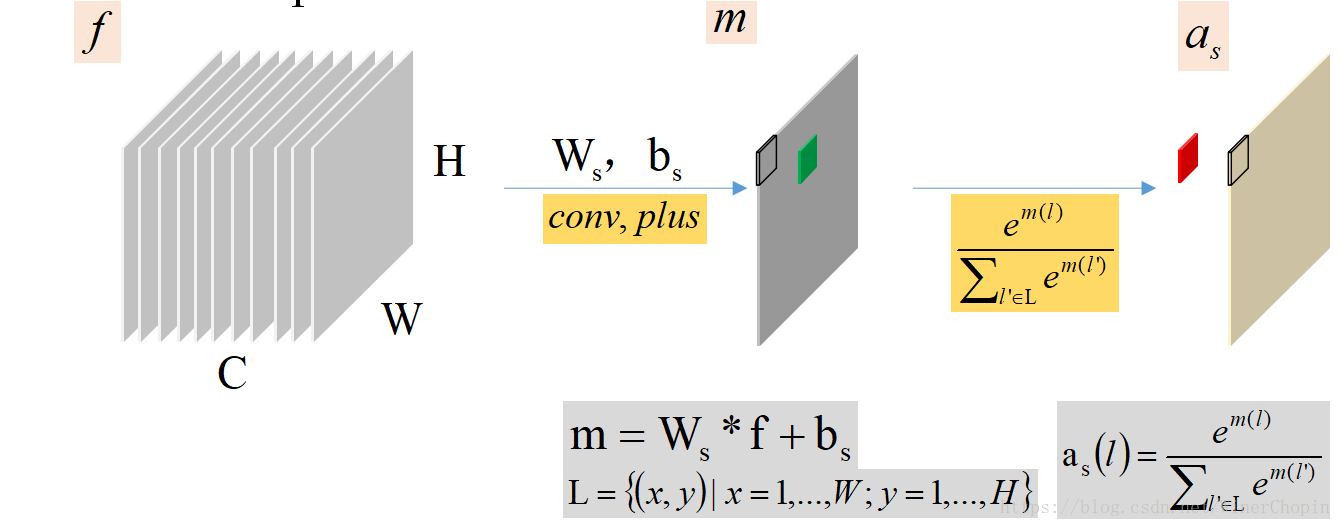
那么,这两个要怎么使用呢?如下图:
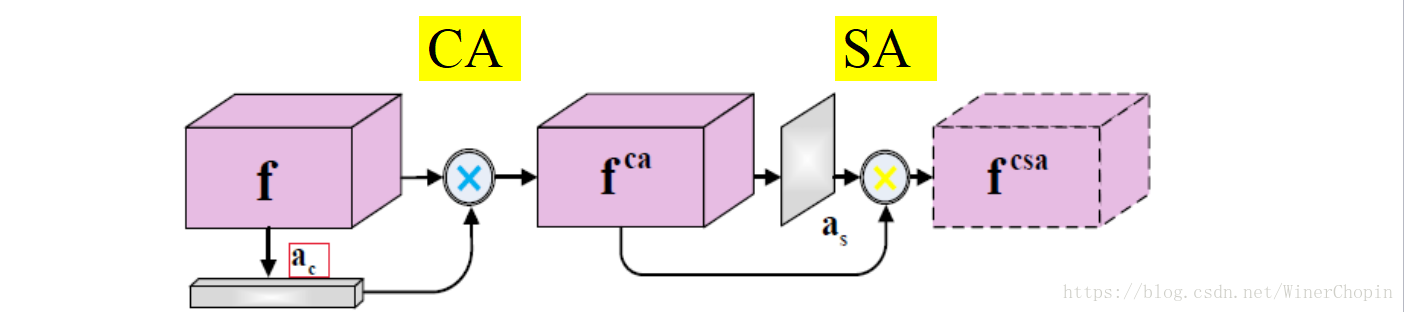
第一个蓝色的运算是指对应channel的那一“片”的所有元素乘以的对应位置的元素值;第二个黄色运算是指HW平面的每一个位置横跨所有的channels的那个长向量来乘以
对应位置的元素值。
3. Progressive Attention Guidance Mechanism

这一部分,我们参照Overview的那个图的紫色部分, 经过CA+SA处理后得到注意力专注后的
,其与来自VGG19的layer4的特征结合后,再经过CA+SA处理得到专注后的
;同理往后逐渐推回,最终得到
就作为我们的最终输出,即input的显著性区域的mask!
(六)实验结果
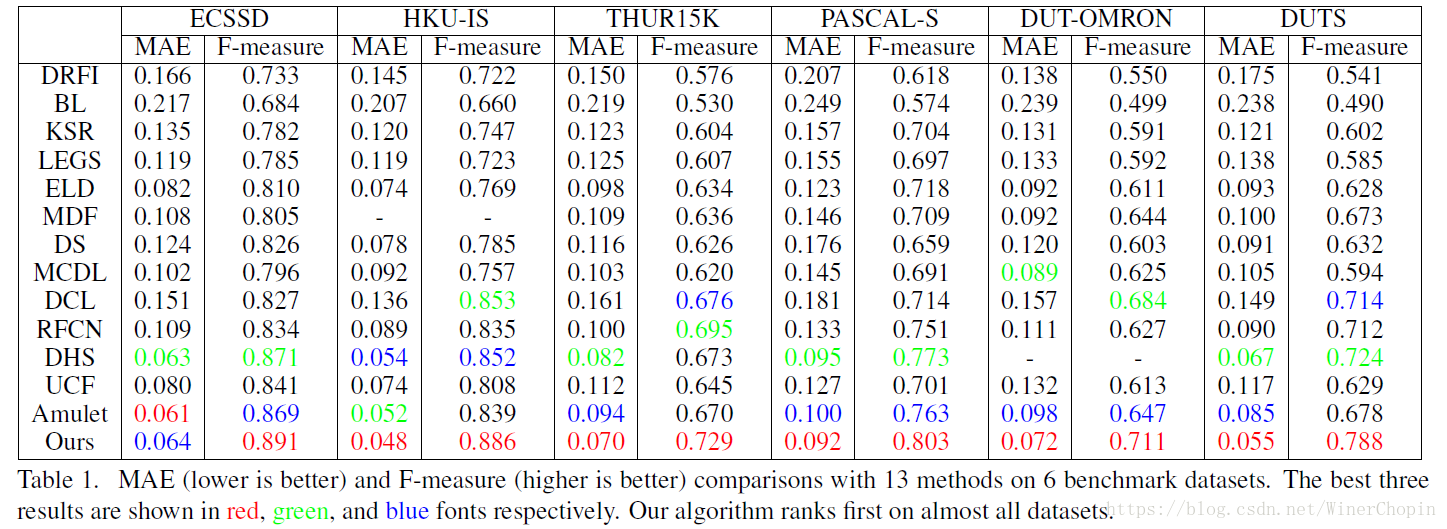
1. 与其他工作的比较
1)视觉比较

2. 溶蚀实验
作者做了如下实验:
- 对比使用 MultiPath Recurrent Guidance Module提取特征与仅适用FCN提取特征的效果
- 中间监督的使用(即在(四)3中的
,
,
,对其利用GT的不同scales求解loss)
- multi-path recurrent guidance module中对哪些层做反馈使得效果最优
- multi-path recurrent guidance module的迭代次数,即time steps的次数
- 是否要将不同的time step的结果合并整合在一起
注意,我们要理解,对于每一个time step,网络都会顺着整个架构跑一次;只不过我们会记住上一个time step的最后一层的输出,用来引导当前time step的特征提取((四)1) .