U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
Abstract
ReSidual U-blocks(RSU)中混合了不同大小的感受野,因此能够从不同的尺度捕获更多的上下文信息。由于在RSU blocks中使用了池化操作,因此可以在不显著增加计算成本的情况下增加了整个结构的深度。
优点:不需要使用分类网络的骨干网络就可以从头开始训练深层网络。
两个模型:U2-Net U2-Net+
1.Introduction
大多数显著性检测网络的设计都有一个共同的模式,它们利用现有的主干网络提取深层的特征。但是,这些主干网络最初都是为图像分类而设计的。 他们提取的特征是语义表示(representative of semantic meaning),而不是局部细节和全局的对比信息(local details and global contrast information),而局部细节和全局对比信息对于显著性检测来说至关重要。如果目标数据与ImageNet上的数据分布不一致,使用预训练的ImageNet数据会存在数据效率低下(data-inefficient)的问题。
我们是否可以为SOD设计一个新的网络,该网络可以从头开始进行训练,并且与基于现有预训练骨干网络的显著性网络相比,可以实现相同或更好的性能?
目前SOD的网络体系结构存在的问题:
(1)网络过于复杂
(2)网络会牺牲高分辨率的特征图而实现更深的结构
在保持高分辨率特征图的同时,来使用较低的内存和计算成本,我们可以把网络结构做得更深吗?
U2-Net解决了上述两个问题。 ReSidual U-block(RSU),它能够提取级内(intra-stage)多尺度特征而不会降低特征图的分辨率。
2.Proposed Method
先描述residual U-block的设计,然后描述以此模块构建的嵌套U型结构(nested U-architecture),最后介绍网络监督策略(network supervision strategy)以及训练损失。
3.1. Residual U-blocks

局部和全局上下文信息对于SOD和其他分割任务都非常重要。 在现代CNN设计中,例如VGG,ResNet,DenseNet等,尺寸为1×1或3×3的小卷积filters是特征提取中最常用的组件。 它们之所以受欢迎,是因为它们需要较少的存储空间并且计算效率高。 图2(a)-(c)显示出了常用的具有小感受野的卷积块。 浅层的输出特征图仅包含局部特征,因为1×1或3×3filters的感受野太小,无法捕获全局信息。 为了在浅层高分辨率特征图中获得更多的全局信息,最直接的想法是扩大感受野。 图2(d)显示了一个类似inception的模块,它试图通过使用空洞卷积来扩大感受野来提取局部和非局部特征。 但是,以原始分辨率在输入特征图上(尤其是在早期阶段)进行多次空洞卷积需要太多的计算和内存资源。为了减小计算代价,PoolNet采用从金字塔池化模块(PPM)parallel configuration。PoolNet在降采样后的特征图上使用小的kernel filters,而不是在原始大小特征图上使用空洞卷积。 但是通过直接上采样和concatenation(或addition)来融合不同尺度的特征可能会导致高分辨率特征的退化(degradation)。
受U-Net的启发,我们提出了一种新的ReSidual U-block(RSU),以捕获阶段内(intra-stage)多尺度特征。RSU-L(Cin,M,Cout)的结构如图2(e)所示,其中L是编码器中的层数,Cin,Cout表示输入和输出通道,M表示数字 RSU内部层中的通道数。 因此,我们的RSU主要由三个部分组成:
(1) 输入卷积层,将输入特征图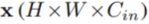 转换为通道为
转换为通道为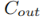 的中间特征图
的中间特征图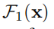 。 这是用于局部特征提取的普通卷积层。
。 这是用于局部特征提取的普通卷积层。
(2) 一个高度为L的类似U-Net的对称编码器/解码器结构,它以中间特征图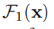 作为输入,并学会提取和编码多尺度上下文信息
作为输入,并学会提取和编码多尺度上下文信息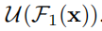 。 U代表如图2(e)所示的类似U-Net的结构。 L越大,RSU越深,池化操作越多,感受野的范围越大,局部和全局特征越丰富。
。 U代表如图2(e)所示的类似U-Net的结构。 L越大,RSU越深,池化操作越多,感受野的范围越大,局部和全局特征越丰富。
配置此参数可以从任意空间分辨率的输入特征图中提取多尺度特征。 从渐进(gradually)下采样的特征图中提取多尺度特征,并通过渐进(progressive)上采样,concatenation和卷积将其编码为高分辨率特征图。 此过程减轻了因大尺度(large scales)直接上采样而导致的细节损失。
(3)残差连接,通过求和: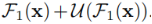 融合局部特征和多尺度特征。
融合局部特征和多尺度特征。

RSU与original residual block的区别:
Residual block: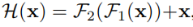 ,其中H(x)表示输入特征x的所需映射(mapping); F2,F1代表权重层,它们是卷积操作。
,其中H(x)表示输入特征x的所需映射(mapping); F2,F1代表权重层,它们是卷积操作。
RSU: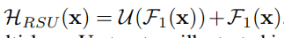 ,使用类似于U-Net的结构代替了普通的单流卷积(plain,single-stream convolution),使用权重转换之后形成的局部特征替换了原始特征。U表示多尺度U型结构。由于大多数的操作是在降采样之后特征图上进行的,因此减小了计算开销(模仿PoolNet?)。
,使用类似于U-Net的结构代替了普通的单流卷积(plain,single-stream convolution),使用权重转换之后形成的局部特征替换了原始特征。U表示多尺度U型结构。由于大多数的操作是在降采样之后特征图上进行的,因此减小了计算开销(模仿PoolNet?)。
3.2. Architecture of U2 -Net


为不同的任务堆叠(stacking)多个类似U-Net的结构前人已经研究一段时间。如stacked hourglass network、DocUNet、用于姿态估计的CU-Ne等,这些方法通常是按顺序堆叠U-Net结构来建立级联模型,可以概括为“(U×n-Net)”,其中n是重复的U-Net模块数。这种方法带来的问题是计算和内存开销被n放大了。
在本文中,我们提出了一个不同的公式,Un-Net用于显著目标检测。我们的指数表示法是指嵌套的U型结构(nested U-structure),而不是级联叠加(cascaded stacking)。从理论上讲,指数n可以任意取正整数来实现单层或多层嵌套U型结构(nested U-structure)。但是,嵌套层太多的网络过于复杂,无法在实际应用中实现和应用。
在这里,我们将n设为2来构建U2-Net。我们的U2-Net是一个两层(two-level)嵌套的U型结构,如图5所示。它的顶层(top-level)是一个由11 stages(图5中的立方体)组成的大U型结构。每个stage都是由配置好的RSU填充(底层U型结构)。因此,嵌套的U型结构可以更高效的实现级内(intra-stage)多尺度特征的提取和级间(inter-stage)多级特征的聚集。


如图5所示,U2-Net主要由三个部分组成:(1)六级(stages)编码器;(2)五级(stage)解码器;(3)显著图融合模块:
(i)在编码阶段(stages)En_1、En_2、En_3和En_4,我们分别使用residual U-blocks RSU-7、RSU-6、RSU-5和RSU-4。7 6 5 4表示RSU blocks的高度(L)。L通常是根据输入特征图的空间分辨率设置的。对于大高度和大宽度的特征图,我们使用更大的L来捕捉更多大尺度信息。在En_5和En_6中的特征图分辨率相对较低,对这些特征图进行下采样会导致有用的背景信息的丢失。因此,在En_5和En_6 stages使用RSU-4F。其中“F”是指RSU的空洞版本,在空洞版本中,我们用空洞卷积代替池化和上采样操作(见图5)。这意味着RSU-4F的所有中间特征图都与其输入的特征图具有相同的分辨率。
(ii)解码器stages具有与对称编码器相似的结构。在De_5中,我们还使用了与En_5和En_6相似的结构RSU-4F。每个decoder stage将前一级(stage)的上采样特征图和对称编码stage特征图的concatenation作为输入,见图5。
(iii)最后一部分是用于生成显著概率图的显著图融合模块。类似于HED[Saining Xie and Zhuowen Tu. Holistically-nested edge detection. InProceedingsoftheIEEEinternationalconference on computer vision, pages 1395–1403, 2015.],我们的U2-Net首先通过3×3卷积层和一个sigmoid函数,从stages En_6、De_5、De_4、De_3、De_2和De_1(+3x3 conv+sigmoid)生成6侧输出显著概率图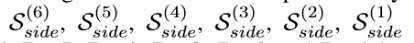
然后,然后将侧输出显著性图的大小上采样到输入图像的大小,使用concatenation操作+1x1conv+sigmoid进行融合产生最终显著性概率图Sfuse
总之,我们的U2-Net的设计允许具有丰富的多尺度特征和相对较低的计算和内存成本的深层架构。此外,由于我们的U2-Net架构只建立在RSU块上,而不使用任何基于图像分类改编的预训练骨干网络,因此它灵活且易于适应不同的工作环境,性能损失很小。
本文实现:普通版本的U2-Net(176.3 MB)和相对较小版本的U2-Net+(4.7 MB)。详细配置见表1的最后两行。
3.3. Supervision
在训练过程中,我们使用类似于HED的深度监督[45]。其有效性已在HED和DSS中得到了验证。训练损失定义为:
其中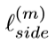 (M=6,图5中的 Sup1-Sup6)是侧输出显著图
(M=6,图5中的 Sup1-Sup6)是侧输出显著图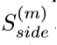 的损失
的损失
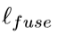 (图5中Sup7)是最终融合输出显著图
(图5中Sup7)是最终融合输出显著图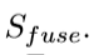 的损失
的损失
 是每个损失项的权重。
是每个损失项的权重。
对于每个项,我们使用标准二值交叉熵来计算损失:
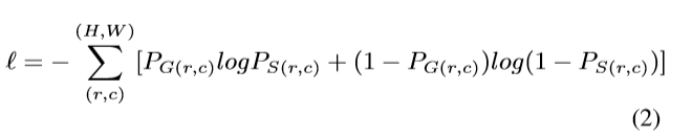
其中(r,c)是像素坐标,(H,W)是图像大小:高度和宽度。
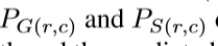 分别表示GT和预测的显著概率图的像素值。训练过程尽量减少总体损失L(公式1)。在测试过程中,我们选择了融合输出
分别表示GT和预测的显著概率图的像素值。训练过程尽量减少总体损失L(公式1)。在测试过程中,我们选择了融合输出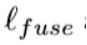 作为最终的显著性图。
作为最终的显著性图。
3.Experimental Results
(1)所有的卷积层使用Xavier进行初始化
(2)损失权重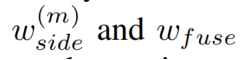 都设置为1
都设置为1
Ablation Study
(basic blocks、architectures、backbones)
Ablation on Blocks

在验证RSU的有效性:
具体来说,我们修复了U2-Net的外部Encoder-Decoder结构,并将其stages替换为其他流行的块,包括普通卷积块(PLN:plain convolution blocks),残差类块(RSE:residual-like blocks),密集类块(DSE:dense-like block),(INC:inception-like blocks)和金字塔池模块(PPM: pyramid pooling module)。 具体见比表1 图2。