利用姿态线索来放大人体的有关局部区域来获得细粒度的信息,然后结合整体特征获得最终结果。
被ICCV2019接收
论文地址:https://arxiv.org/pdf/1909.08453
1.摘要
推理人机交互是以人为中心的场景理解中的一个核心问题,由于人类物体配置的巨大变化、多个共生关系实例以及关系类别之间细微的视觉差异,检测这种关系对视觉系统提出了独特的挑战。
为了解决这些问题,本文提出了一种多层次的关系检测策略,该策略利用人的姿势线索来捕捉关系的全局空间结构,并作为一种注意机制来动态地放大人的局部相关区域。
具体地说,开发了一个多分支深层神经网络来实例化多级关系推理,它由四个主要模块组成:主干模块、整体模块、放大模块和融合模块。
- 给定一幅图像,主干模块计算其卷积特征图,生成人体物体建议和空间配置。
- 对于每个proposal,整体模块集成了人、物体及其联合特征,以及人类姿势和物体位置的编码。
- 放大模块提取人体部分和物体特征,并从姿势布局中产生部分级别的注意,以增强相关的部分提示。
- 融合模块将整体和部分级别的表示结合起来,生成HOI类别的最终分数。
2. 相关工作
由于人的物体外观和空间形态的巨大变化,多种共存关系,相似关系之间的细微差别等原因,目前人物交互领域仍然存在着巨大的挑战。
大多数现有的HOI检测工作都是通过在视觉目标层次上进行推理交互来解决这个问题的。主要的方法通常从一组人-物体建议开始,提取人和物体实例的视觉特征,并结合它们的空间线索来预测这些人-物体对的关系类。尽管结果令人鼓舞,但在处理相对复杂的关系时,这种粗略的推理仍有一些缺点。首先,由于缺少上下文提示,很难确定人-物体对实例与目标级表示的关系,这可能导致错误的关联。此外,许多关系类型都是根据细粒度操作定义的,而细粒度操作不太可能基于类似的目标级特性进行区分。例如,它可能需要一组详细的局部特征来区分运动场景中的“保持”和“捕捉”。此外,由于这些方法在很大程度上依赖于整体特征,关系的推理过程是一个黑箱,很难解释。
人-物交互(HOI)检测对于理解复杂场景中的人的行为至关重要。近年来,研究者们开发了一些人-物交互数据集,如V-COCO和HICO-DET。早期的研究主要集中在利用多流信息处理HOIs识别,包括人、物体外观、空间信息和人体姿态信息。在HORCNN中,Chao等人提出多流融合人、物和空间配置信息来解决HOIs检测任务。齐等人提出了一种图形解析神经网络(GPNN),将结构化场景建模为一个图形,在每个人和物体节点之间传播信息,并对所有节点和边缘进行分类,以确定其可能的物体类别和行为。
有几次尝试使用人体姿势来识别细粒度的人体相关动作。方等人利用成对的人体部位相关性来帮助解决HOIs检测问题。Li等人探索多个数据集中先前存在的交互性,将人体姿态和空间构型结合起来形成姿态构型图。然而,这些工作只将人体姿态作为人体各部分与物体之间的空间约束,而没有利用人体姿态来提取各部分的放大特征,从而没有为HOI任务提供了更多的细节信息。
3.本文方法
3.1 总体结构

网络总共包括4部分,分别为backbone、整体模块、放大模块、融合模块。
对于一对人-物目标提议和相关的人体姿势,主干模块旨在获取卷积特征图和空间配置图(SCM)。整体模块(Holistic Module)生成目标级(整体)特征,放大模块(Zoom-in Module)捕获部件级(部分)特征。最后,融合模块结合整体层和部分层的线索来预测HOI类别的最终得分。
公式化:
给定一幅图像I,人物交互检测的任务是为图像中的所有HOI实例生成元组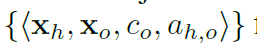 。这里xh表示人实例位置(即边界框参数),xo 表示物体实例位置,co是物体类别,a(h,o)表示与xh和xo关联的交互类。
。这里xh表示人实例位置(即边界框参数),xo 表示物体实例位置,co是物体类别,a(h,o)表示与xh和xo关联的交互类。
对于一对{xh;xo},本文使用 来表示是否存在交互类a。物体和关系集C和A被作为检测任务的输入。
来表示是否存在交互类a。物体和关系集C和A被作为检测任务的输入。

作者采用假设和分类策略,首先生成一组人-物体proposal,然后预测它们的关系类。
在proposal生成阶段,对输入图像应用一个目标检测器(例如,Faster R-CNN),并获得一组检测分数为{xh;sh}的人体proposal,以及具有类别和检测分数{xo;co;so}的物体proposal。HOI proposal是通过将所有人和物体proposal配对生成的。
在关系分类阶段,首先估计每个交互作用a和给定{xh;xo}对的关系得分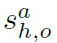 。然后,将关系分数与关系实体(人和物体)的检测分数相结合,生成元组
。然后,将关系分数与关系实体(人和物体)的检测分数相结合,生成元组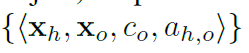 的最终HOI分数
的最终HOI分数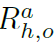 ,如下所示,
,如下所示,

其中采用了一种软评分融合方法,将人体评分sh与目标评分so同时融合,体现了每一个proposal的检测质量。
为了获得关系得分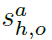 。为此,首先将现成的姿势估计网络应用于proposal xh的裁剪区域,该proposal xh生成姿势向量
。为此,首先将现成的姿势估计网络应用于proposal xh的裁剪区域,该proposal xh生成姿势向量 ,其中pkh是第k个关节位置,k是所有关节的数目。
,其中pkh是第k个关节位置,k是所有关节的数目。
3.2 Backbone
本文采用ResNet-50-FPN作为backbone用来提取图像特征。利用Faster R-CNN生成关系proposal对{xh,xo}。
除了conv特征外,还提取了一组几何特征来编码每个人类物体实例的空间配置。从人类和物体的联合空间的二元掩模开始,捕捉目标级的空间配置。此外,为了获取人体各部分和物体的精细空间信息,本文添加了一个附加的人体姿势图,其中包含预测的姿势。具体地说,将估计的人体姿态表示为一个线图,其中所有关节都根据COCO数据集的骨架结构连接起来。作者使用宽度为w=3像素和一组强度值(范围从0.05至0.95),以均匀间隔表示不同的人体部位。最后,将联合空间中的二值掩模和位姿映射重新缩放到M × M,并以channel-wise方式拼接以生成空间配置映射。
3.3 Holistic Module
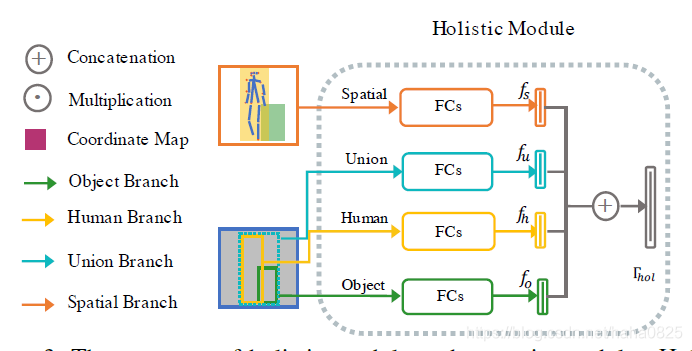
整体模块由四个基本分支组成:人分支、物体分支、联合分支和空间分支。
根据人提议xh、物体提议xo及其联合提议xu,应用RoI-Align从卷积特征映射中裁剪出人、物体和联合分支的输入特征。xu定义为空间区域中同时包含xh和xo的最小box。然后将人体特征、物体特征和联合特征重新缩放到Rh × Rh分辨率。空间分支的输入直接来源于backbone生成的空间配置图。对于每个分支,采用两个全连接层将特征嵌入到输出特征表示中。
将人、物、联合以及空间特征的输出特征表示为fh、fo、fu、fs,并将所有特征拼接起来,得到最终的整体特征:
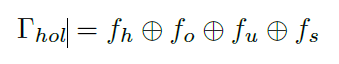
3.4 Zoom-in Module
虽然整体特征为交互提供了粗略的层次信息,但许多交互类型是在精细的层次上定义的,这需要详细的人的部分或物体的局部信息。因此,作者设计了一个放大(ZI)模块来放大人体部分以提取零件级特征。整体放大模块可视为一个网络,以人体姿态、物体提议和卷积特征图为输入,为HOI关系提取一组局部交互特征:
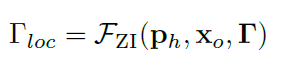
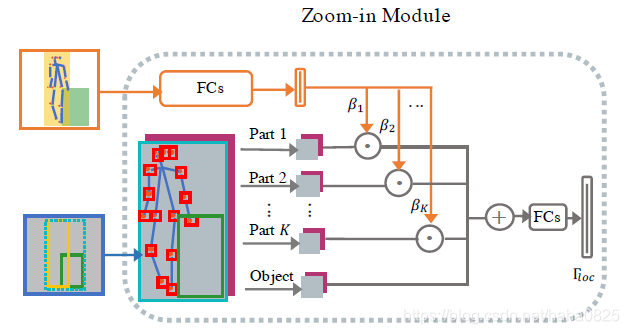
放大模块由三个组件组成:
i)旨在提取细粒度人体部件特征的部分裁剪组件;
ii)将空间信息分配给人体部件特征的空间对齐组件;
iii)语义注意力部分,增强与交互相关的人类部分特征,抑制不相关的特征。
(1)部分裁剪组件
给定人体姿势向量ph={ p1 h;:::;pKh },我们为每个关节pk h定义一个局部区域xpk,该区域是以pk h为中心的框,其大小与人体提议xh的大小成比例。采用RoI Align与物体建议xo一起生成(K+1)个区域并重新缩放到Rp × Rp的分辨率。
将集合的零件特征和物体特征表示为fp={ fp1;:::;fpK}和fpo,其中每个特征的大小为Rp × Rp × D。
(2)空间对齐组件
许多交互行为都与人体各部分和物体的空间结构有很强的相关性,可以通过人体各部分和物体之间的相对位置进行编码。例如,如果目标物体靠近“hand”,则交互更可能是“hold”或“carry”,而不太可能是“kick”或“jump”。在此基础上,作者引入(x,y)坐标作为相对于物体中心的空间偏移作为每个部分的附加空间特征。
作者生成了与卷积特征映射 具有相同空间大小的坐标映射α 。α 特征图由两个通道组成,指示
具有相同空间大小的坐标映射α 。α 特征图由两个通道组成,指示 中每个像素的x和y坐标,并由物体中心进行标准化。然后,对每个人类部分xpk以及对α上的物体建议xo应用RoI Align,得到k部分的空间映射 αk和物体的空间映射 αo。作者将空间映射与部分裁剪特征连接起来,以便对于Rp × Rp裁剪的部分区域,将相对空间偏移与每个像素对齐,从而使用细粒度的空间线索来增强部分特征。最后的第k个人体部件特征和物体特征是:
中每个像素的x和y坐标,并由物体中心进行标准化。然后,对每个人类部分xpk以及对α上的物体建议xo应用RoI Align,得到k部分的空间映射 αk和物体的空间映射 αo。作者将空间映射与部分裁剪特征连接起来,以便对于Rp × Rp裁剪的部分区域,将相对空间偏移与每个像素对齐,从而使用细粒度的空间线索来增强部分特征。最后的第k个人体部件特征和物体特征是:
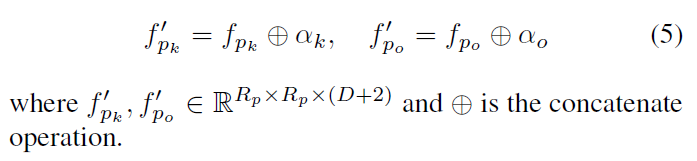
(3)语义注意力组件
作为姿势表示的语义注意力组件也编码了人类部分的语义类,它们通常与交互类型有很强的相关性(例如,“眼睛”对于“阅读”一本书很重要)。因此,本文使用来自backbone的相同空间结构图来预测语义注意力。
语义注意力网络由两个全连接层组成。在第一层之后采用ReLU层,在第二层之后使用Sigmoid层将最终预测规范化为[0,1]。作者把推断的语义注意力表示为 β。需要注意的是,并不预测物体的语义注意力,并且假设物体的注意值始终为1,这意味着它在不同的实例中具有一致的重要性。语义注意力用于按如下方式对零件特征进行加权(按元素相乘):
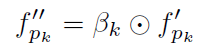
最后,将人类零件特征和物体特征连接起来,以获得零件级特征fatt,并将其传到多个全连接层(FC)以提取最终的局部特征 Floc:

3.5 Fusion Module
为了计算每个交互a的人-物对{xh,xo}的得分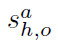 ,使用了一个融合模块来融合不同层次的关系推理。
,使用了一个融合模块来融合不同层次的关系推理。
融合模块旨在实现以下两个不同的目标。
-
首先,它使用粗级别的特征作为上下文提示来确定是否存在针对人-物体建议的任何关系。这可以抑制许多背景对,提高检测精度。
具体地说,将整体特征引入一个网络分支,该分支由一个两层全连接的网络和一个sigmod状函数构成,该网络分支产生一个相互作用的亲和度得分SG:
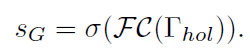
-
其次,融合模块利用目标级和部分级的特征来确定基于细粒度表示的关系评分。使用类似的网络分支,从所有关系特征计算局部关系分数sL:
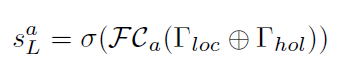
其中a表示关系类型。 -
最后,将上面定义的这两个分数进行融合,以获得针对人-物提议的关系分数{xh;xo}
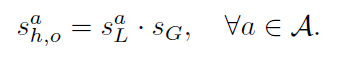
3.6 模型训练
冻结ResNet-50,训练FPN部分和其他组件。目标检测器(Faster R-CNN)和姿态估计器(CPN)是外部模块,不参与学习过程。
分类任务实际上是一个多标签分类的问题,对每个关系类和交互亲和力采用二元交叉熵损失,总体的损失函数如下:
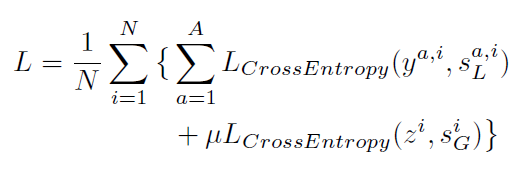
SL为局部关系得分;SG为亲和力(affinity)得分;N为训练集;A为交互集;yi为第i个例子的真实值;zi(0,1)指示第i个例子的相关性;
4. 实验
(1)在V-COCO 测试集上的表现对比如下:

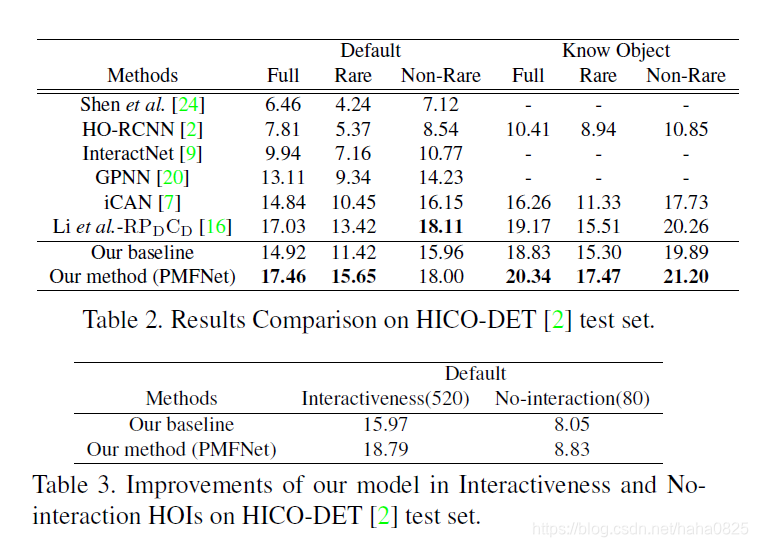
(2)在HICO-DET测试集上的表现如下:
(3)在V-COCO验证集上的消融实验情况:
