这篇论文主要解决了标记mask问题,并使用多任务模式提高了语义分割的精度。
网络简称:C2S-Net
亮点
1、解决了手动注释问题,训练网络过程中自动标记mask;
2、采用multi-task模式,两个任务之间通过交互方式提高精度;
这篇论文主要做了两个task:
(1)轮廓检测;
(2)语义分割;
检测效果
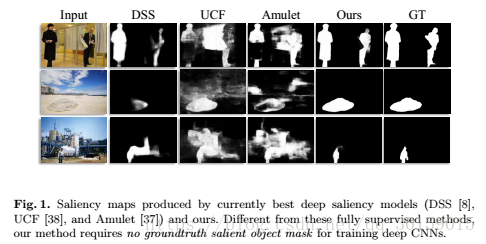
主要贡献
(1)通过将训练有素的轮廓检测模型自动转换为显着性分割模型;
(2)提出了一种基于训练好的轮廓检测网络的新型轮廓到显着性网络(C2S-Net);
(3)介绍了一种简单而有效的contour-to-saliency transferring 方法,以减小轮廓和显着对象区域之间的误差(即mask标记方法)
模型过程:
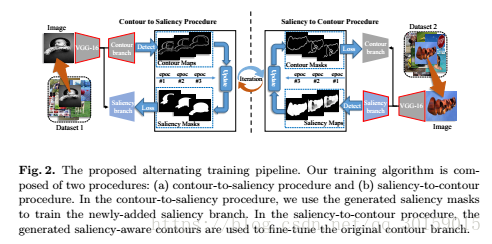
通过在现有CEDN模型上添加新分支来提出 Contour-to-Saliency Network 。
在该架构中,原始Contour分支和新添加的Saliency分支共享相同的特征提取器(或编码器)。 使用CEDN初始化特征提取器和Contour分支,并且随机初始化Saliency分支。 因此,我们的C2S-Net能够在参数初始化后自然地检测输入图像的轮廓。
训练算法由两个程序组成:1)Contour-to-Saliency过程,2)Saliency-to-Contour过程。
在Contour-to-Saliency过程中,Contour分支首先用于检测每个图像中的轮廓。接下来,利用contour-to-saliency transferring方法,基于检测到的轮廓生成Saliency对象mask;
Contour-to-Saliency Network结构
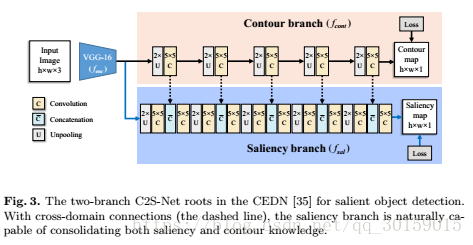
C2S-Net由三个主要部分组成:编码器,轮廓解码器和显着性解码器。编码器从输入图像中提取高级特征,轮廓解码器识别显着区域的轮廓,并且显着性解码器估计每个像素的置信度。
编码器
编码器通过输入图像输出特征图。在论文网络在CEDN之后,将VGG-16 用于特征提取器(编码器),最后两层被移除。
轮廓解码器
轮廓解码器建立在特征提取器上,通过特征图,产生轮廓图。可以将轮廓解码器的训练视为对真实标注轮廓标签的逐像素回归问题。
显着性解码器
将特征图作为输入,并产生单通道语义分割图,因为语义分割比轮廓检测更加困难,所以我们在每个显着性解码器组中添加另一个卷积层。
Contour-to-Saliency Transfer
首先,在每个图像中检测到的轮廓中,采用MCG方法生成一些推荐掩模C。然后从C中仅选出极少数掩模B(500个),这些掩模最有可能覆盖整个对象区域。
训练过程
为了避免较差的局部最优问题,我们使用两组不同的未标记图像(M和N)来交互式训练-Saliency 分支和轮廓分支。
迭代地执行Contour-to-Saliency过程和Saliency-to-Contour过程。固定一组网络参数,同时求解另一组。
在Contour-to-Saliency过程中,通过固定编码器参数和轮廓解码器参数,通过在第一阶段步骤中使用初始化的C2S-Net在未标记的组M上生成每个图像的轮廓图(以及每个后续阶段步骤中更新的C2S-Net)。之后,使用Contour-to-Saliency Transfer方法来产生对象掩模,作为用于更新显着性解码器参数的训练样本。在此过程中,我们还测量每个生成的轮廓图的置信度,过滤不可靠的轮廓图。
在Saliency-to-Contour过程中,我们固定编码器参数和显着性参数,C2S-Net生成轮廓图和分割图。然后利用这些生成的结果在未标记的组N上产生对象掩模。