文章"Pruning Convolutional Neural Networks for Resource Efficient Inference"的介绍。
1、Introduction
文章提出了一种针对预训练模型进行通道裁剪(channel pruning)的方法,通过逐一裁剪通道、fine-tuning的迭代操作,实现一定比例的模型压缩,同时确保较低的精度损失。文章首先定义了用于衡量通道(channel)重要性的metric,并根据metric对不同隐含层的每个通道进行排序,然后顺次裁剪不重要的通道(importance由低到高),每裁剪一个通道做一次fine-tuning,达到指定的压缩比(compression rate)后结束操作。由于通道裁剪的规整性,裁剪后的模型无需特定加速器或算法库的支持,能够直接在现有的成熟平台或框架上运行,并配合其他模型压缩算法、加速优化算法或重构优化工具(量化、低秩分解、稀疏块算法、TensorRT等)能够进一步提升加速比(speedup rate)。
2、Method
针对预训练模型,基本的迭代式裁剪流程如下:

裁剪、精调的过程可以认为是一个组合优化问题,即首先要确保裁剪后的模型尽可能保留原有模型的精度,从而寻求一种最优的裁剪方式:

2.1 Oracle Pruning
文章首先定义了Oracle Pruning,即每裁剪一个隐含层的weight或activation,表现为对损失函数C的差值或绝对差值的影响:

文章最后选择的Oracle 规则为:最小化损失函数C的绝对差值,即绝对差值越小,权重连接的重要性越低。
2.2 Criteria for Pruning
文章列举了一些衡量裁剪重要性的准则,如weight的阈值、L1、L2范数,activation的均值、方差、熵,Feature Map中零元素所占百分比(APOZ)等。之后文章通过泰勒展开,并只保留0阶项与1阶项,定义了一种新的metric。推导过程如下:

由于深度学习广泛采用ReLU激活,因此损失函数C绝对差值的剩余项R1几乎为零,忽略之后可以得到用来衡量不同隐含层的每个activation的重要性准则如下:

扩展到channel层次,不同隐含层的每个channel的重要性如下式,式中M表示每个Feature Map包含的activation数目:
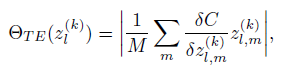
文章接下来探讨了与Optimal Brain Damage(OBD)所采用方法的比较。Optimal Brain Damage采用损失函数C关于隐含层activation的二阶导数作为重要性衡量准则,因为越不重要的权重连接,损失函数绝对差值的一阶导数越小甚至为零(极小值点),因此数值的重要性体现在了二阶导数上。而本文提出的准则采用一阶导数与激活的乘积y作为衡量准则,尽管一阶导数为零,但是乘积y的方差不为零、并且能够反映激活的统计分布,且y的绝对值与y的方差成比例,因此能够很好的衡量裁剪的重要性。
2.3 Normalization
为了共同比较不同隐含层中channel的重要性,文章对同一层不同channel的重要性做了标准化处理,使数值范围介于0到1之间:

2.4 FLOPS Regularized Pruning
计算Feature Map需要的计算量、内存占用、访存带宽等可作为附加的正则项,例如引入计算量FLOPS(floating-point operations per second)的正则项:

直观上讲,为了实现一定的加速比,计算输出Feature Map需要的计算量越大,该Feature Map的重要性越低。
3 Results
根据给定的重要性准则,都会对不同隐含层的每个channel做排序(Rank),然后按重要性排序由低到高裁剪channel。文章通过与Oracle准则之间的Spearman’s rank correlation来评判一种重要性准则的优劣:

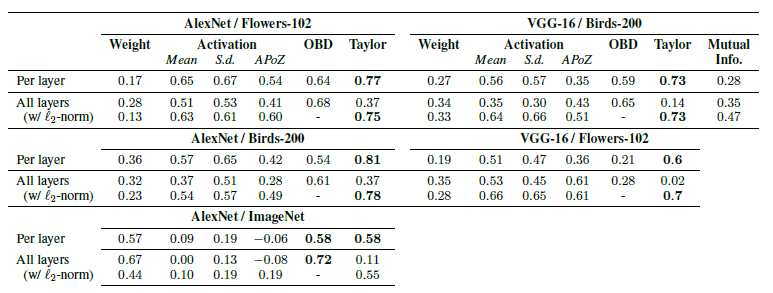
表格显示了Weight幅度,Activation均值、方差、APOZ,OBD以及本文提出的准则与Oracle准则之间的Correlation,表明本文的方法与Oracle准则之间具有最高的相关性。
应对Birds-200、Flowers-102等数据集或任务,文章比较了采用不同准则裁剪模型后的精度:

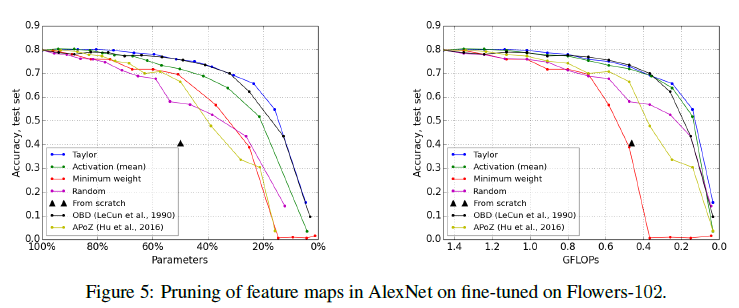
并分析了参数更新的次数(训练迭代次数)对精度恢复的影响,显然updates越多越好,必要的情况下需要经过几个epoch的fine-tuning:

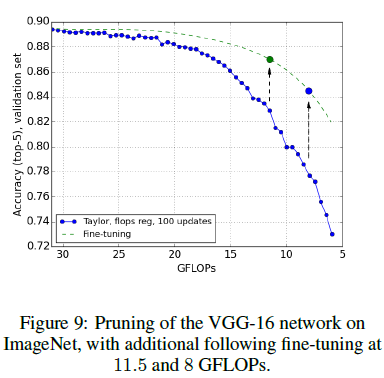
以及施加计算量正则约束的影响,结果表明fine-tuning的效果会更好:
最后给出了不同平台上的实测加速比,本文提出的方法能够获得显著的提速:

4 Conclusions
逐个通道裁剪、fine-tuning的迭代方式,显然非常耗时,尤其是复杂的深度学习模型如Resnet101、Resnet152、Densenet169、ResNext50、DPN92等,以及大型、复杂的应用场景所涉及海量训练数据也会影响通道裁剪的迭代效率。本文作者为NVIDIA工程师,拥有相对丰富的GPU资源,因此可以实施比较精细的实验操作。但当计算资源有限时,可以选择一种相对折中的操作方法,即按照裁剪一定比例的通道、然后fine-tuning的方式予以操作。
Paper地址:
GitHub地址(Pytorch demo):