论文地址:https://arxiv.org/abs/1703.03872
项目地址:https://github.com/Joker316701882/Deep-Image-Matting
概述
Adobe提出一种基于深度学习的新算法,主要解决传统方法中只有low-level features和缺乏high-level context的问题。深度模型分为两个阶段。第一阶段是深度卷积编码-解码网络,该神经网络将原图和对应的trimap作为输入,并预测图像的alpha matte。第二阶段是一个小型卷积神经网络,该网络对第一个网络预测的alpha matte进行精炼,从而拥有更准确的α值和锐化边缘。此外,还创建了一个大规模抠图数据集,该数据集包含 49300张训练图像和1000张测试图像。深度模型+大规模数据集使之效果表现尤佳。
Motivation
方法的动机来源于传统方法存在的两个问题。
一是当前方法将抠图方程设计为两个颜色的线性组合,即将抠图看做一个染色问题,这种方法将颜色看做是一个可区分的特征。但是当前景和背景的颜色空间分布重叠时,这种方法的效果就不是很好了。使用深度学习不首要依赖色彩信息,它会学习图像的自然结构,并将其反映到alpha matte。
二是当前基于抠图的数据集太小,alphamatting.com数据集只有27张训练图片和8张测试图片,训练出来的模型泛化能力较差。针对该问题,作者将前景抠出来,并放入到不同的背景下,从而构建一个大规模抠图数据集。

网络结构
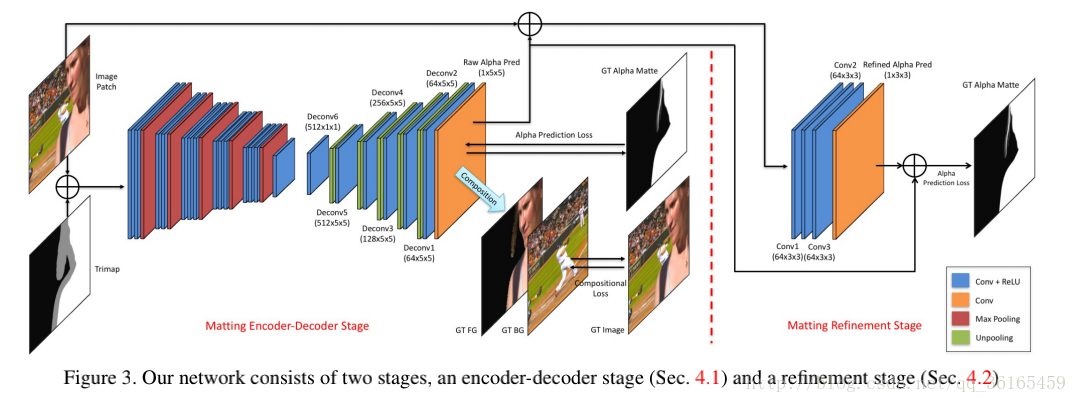
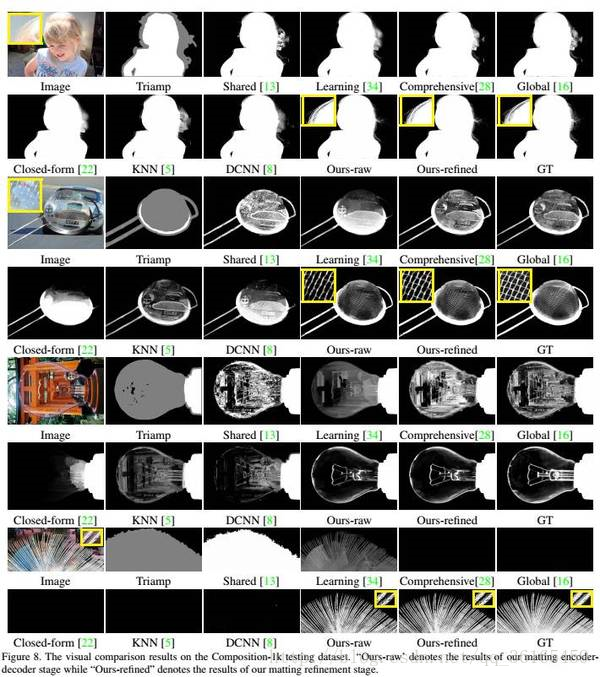
网络结构由两阶段组成,Matting encoder-decoder stage 和 Matting refinement stage.
Matting encoder-decoder stage
网络:输入图像块和对应的trimap,输出是alpha预测。编码阶段是14个卷积层和5个池化层,得到低分辨率的特征图,解码阶段是6个卷积层的小网络,5次unpooling得到原图大小的alpha prediction.
Loss: 使用了两个loss,第一个是alpha-prediction loss,是预测的alpha values 和ground truth的alpha values的绝对差。第二个loss是compositional loss,预测的RGB颜色值和对应的ground truth绝对差。两个loss以0.5加权得到最终的loss。
实现:数据处理技巧有随机裁剪(320*320),不同尺度输入(resize到320*320),图片翻转等;编码加载VGG16模型的前面,译码阶段使用Xavier随机初始化。
Matting refinement stage
网络:4个卷积层,输入是图像块和预测的alpha prediction。
实现:先训练编解码网络,待其收敛后用于更新refine网络,第二个网络只使用alpha-prediction loss。
总结
为了泛化到自然图像中,抠图算法必须超越以色彩为主要线索,并能利用更加结构性和语义性的特征。论文中的神经网络有足够的能力捕捉到高层次特征(high-order features),并利用它们计算且提升抠图效果。以下是一些论文中report的结果。