一、论文简述
1. 第一作者:Rui Li
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:光流、深度学习、PatchMatch、局部搜索
5. 探索动机:对于深度学习来说,除了准确性之外,性能和内存也是一个挑战,特别是在高分辨率下预测光流时。为了降低计算的复杂性和内存的使用,以前的方法使用从粗到细的策略,但可能会出现低分辨率误差恢复问题。为了在大位移,特别是快速运动的小目标上保持较高的精度,RAFT构建了一个全对四维相关体,并用卷积GRU块进行查找。然而,在预测高分辨率光流时同样有内存问题。
6. 工作目标:为了在减少内存的同时保持较高的精度,引入PatchMatch就是为了对抗RAFT的4D All Paired Correlation Volume的高冗余计算。
7. 核心思想:将Patchmatch的思想引入到相关性的计算中,而不是使用这样的稀疏全局相关策略造成精度损失。
- We design an efficient framework which introduces Patchmatch to the end-to-end optical flow prediction for the first time. It can improve the accuracy of optical flow while reducing the memory of correlation volume.PatchMatch求解高精度光流。
- We propose a novel inverse propagation module. Compared with propagation, it can effectively reduce calculations while maintaining considerable performance.提出优化的Inverse Propagation。
8. 实验结果:
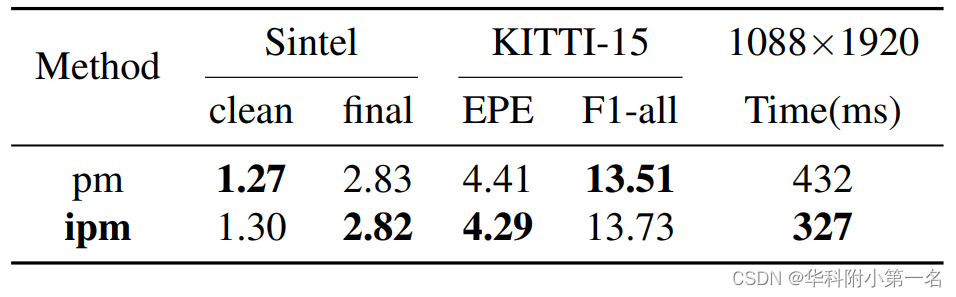
At the time of submission, our method ranks 1st on all the metrics on the popular KITTI2015 benchmark, and ranks 2nd on EPE on the Sintel clean benchmark among published optical flow methods. Experiment shows our method has a strong cross-dataset generalization ability that the F1-all achieves 13.73%, reducing 21% from the best published result 17.4% on KITTI2015. What’s more, our method shows a good details preserving result on the high-resolution dataset DAVIS and consumes 2× less memory than RAFT.
9.论文下载:
https://github.com/zihuazheng/DIP
二、实现过程
1. 相关体对比
局部相关体(Local Correlation Volume)。在现代基于局部相关体的光流方法,其计算公式如下:

式中F1为源特征图,F2为目标特征图,d为x或y方向的位移。X = [0,H)x[0,w),D=[−dmax,Dmax]2, h为特征图的高度,w为特征图的宽度。因此,相关体的内存和计算与hw(2dmax + 1)2呈线性关系,与搜索空间的半径呈二次关系。受限于搜索半径的大小,在高分辨率挑战性场景下难以获得高精度的光流。
全相关体(Global Correlation Volume)。最近,RAFT[36]提出了一种全对相关体积,达到了最先进的性能。F1中位置(i, j)和F2中位置(k, l)的全局相关计算定义如下:

其中m为金字塔层数。2m是池化的核大小。与局部相关体相比,全局相关体包含N2个元素,其中N = hw。当F的h或w增加时,内存和计算量将成倍增加。因此,全局方法在进行高分辨率推理时存在内存不足的问题。
块匹配(Patchmatch Method)。Patchmatch用于寻找图像间的稠密对应关系,进行结构化编辑。它背后的关键思想是,可以通过大量随机采样得到一些好的猜测。并且基于图像的局部性,一旦找到一个好的匹配点,信息就可以有效地传播到相邻的图像中。因此,提出采用传播策略来减小搜索半径,采用局部搜索来进一步提高准确率。Patchmatch方法的复杂度为hw(n + r2),其中n为传播次数,r为局部搜索半径,两个值都很小,不随位移和分辨率的增加而变化。
2. 光流的Patchmatch
传统的Patchmatch方法主要有三个组成部分。1)随机初始化。通过大量随机采样得到一些很好的猜测。2)传播。基于图像的局部性,一旦找到一个好的匹配点,信息就可以有效地从它的邻居传播出去。3)随机搜索。在后续传播中使用它来防止局部优化,使其在其邻域不存在良好匹配时能够获得良好匹配。
迭代传播和搜索是解决光流问题的关键。在传播阶段,将特征图中的一个点作为一个patch,并选择4个相邻的种子点。因此,每个点都可以通过将光流图移向4个邻居来从其邻居处获得候选光流。然后根据邻近候选光流及其光流计算出一个5维相关体。给定所有光流的位移∆p,则传播的相关计算可定义为:
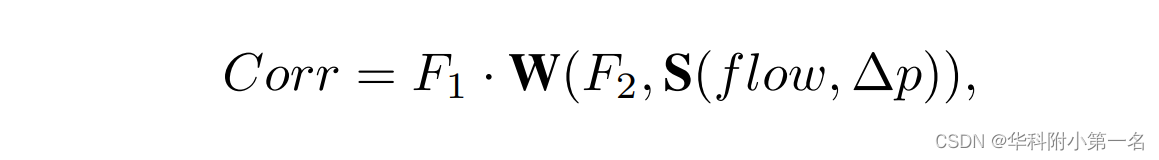
S(flow,∆p)为根据∆p的位移光流。W为用移动光流变化的F2。毫无疑问,选择的种子点越多,需要的操作就越多。当传播迭代m次选择n个种子点时,传播需要光流移动n×m次,源特征变化n×m次。这增加了内存操作和插值计算,特别是在预测高分辨率光流时。为了减少选项的数量,第一次用逆传播代替传播。在搜索阶段,将随机搜索改为更适合端到端网络的局部搜索方法,达到了更高的准确率。
3. 深度反向块匹配
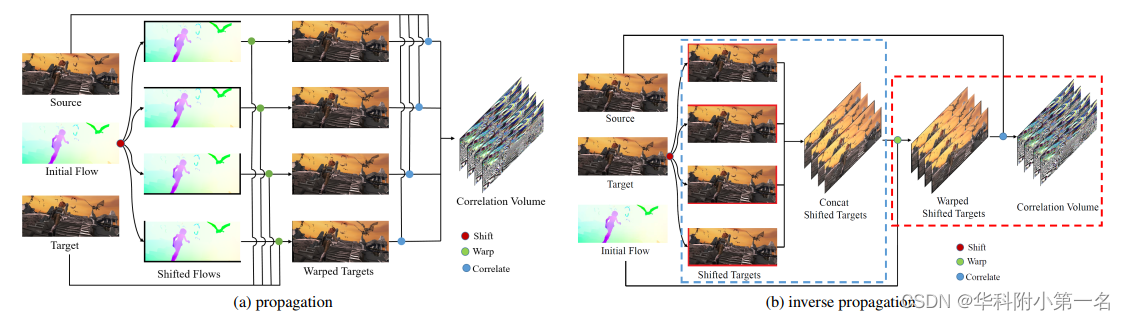
逆传播。在传播中,光流位移和特征warp是串行耦合的,因为warp过程取决于光流的位移。此外,每次迭代都需要进行多次光流位移,因此计算量增加。理论上,将流移到右下的空间相对位置与将目标移到左上的空间相对位置相同。两种方法的相关图在绝对空间坐标上有一个像素偏移。我们将目标移位的方式称为逆传播,逆传播可以表示为:

由于∆p很小,在实现中忽略了反向传播的过程。即得到:

在反向传播中,目标特征点被分散到它的种子点上,并被种子点的光流warp。因此,可以提前对目标特征进行移位和叠加,然后在每次迭代中只进行一次warp,以获得warp后的目标特征。
在这项工作中,种子点是静态的,不会随着迭代的增加而改变。因此,目标特征只需要移动到种子点一次,并且移动的目标特征可以在每次迭代中重用。这样,如果有n个种子点进行m次传播迭代,只需要移动目标特征n次,并将移动的目标特征变化m次。逆传播阶段可分为两个子阶段:
初始化阶段:输入源特征、目标特征。根据种子点对目标特征进行移位,然后沿深度维度将移位的目标特征作为共享目标特征进行叠加。
运行阶段:输入一个流,根据流warp共享目标特征,计算源特征与warp目标特征的相关性。
局部搜索。由于随机初始化的光流值范围非常稀疏,仅通过块传播难以获得非常精确的光流。因此,在本工作中,每个块传播后都会进行局部邻域搜索。不像Patchmatch,它在每次传播后进行随机搜索,并随着迭代的增加而减小搜索半径。本文在每次传播后只执行一个固定的小半径搜索,称之为局部搜索。给定一个光流增量∆f,局部搜索可以用公式表示:

在本工作中,根据实验结果将最终搜索半径设置为2。为此,逆Patchmatch模块主要由逆传播块和局部搜索块组成。在每次迭代中,逆传播之后是局部搜索。值得注意的是,两个块都使用GRU代价聚合。
4. 网络结构
为了在高分辨率图像上获得高精度的光流,设计了一种新的光流预测框架DIP。概述如下图所示。主要分为两个阶段:(1)特征提取;(2)多尺度迭代更新。

特征提取。首先,对输入图像使用特征编码器网络,提取1/4分辨率的特征图。与之前的工作不同,它们使用上下文网络分支来提取上下文。DIP直接激活源特征图作为上下文图。然后使用平均池化模块将特征图降到1/16的分辨率。对于1/4分辨率和1/16分辨率,使用相同的主干和参数。因此,DIP可以分两个阶段进行训练,在处理大型图像时,使用更多的阶段进行推理。
多尺度迭代更新。该方法基于邻域传播,必须对光流进行迭代更新。网络由两个模块组成,一个反向传播模块和一个局部搜索模块。在训练阶段,以1/16大小的随机光流开始网络,然后使用金字塔方法迭代优化大小为1/16和1/4的光流。在推理阶段,可以执行与训练阶段相同的过程。为了获得更精确的光流,还可以在1/8尺度下对光流进行改进,然后在1/4尺度下对结果进行优化。
网络也接受初始化的光流作为推理阶段的输入。在这种情况下,根据初始化光流的最大值来调整金字塔的推断层数。例如,在对视频图像的光流进行处理时,将前一图像的光流前向插值作为当前图像的输入。利用之前光流的信息,可以对大位移使用两个或多个金字塔来保证精度,对小位移使用一个金字塔来减少推理时间。
5. 损失
损失函数类似于RAFT。DIP每次迭代输出两个光流。当在1/16和1/4分辨率下使用N次迭代时,在整个训练过程中输出数的预测N = 迭代× 2 × 2。由于监督有多个输出,使用与RAFT类似的策略,计算一个加权序列并将预测序列的损失求和。总损失可表示为:

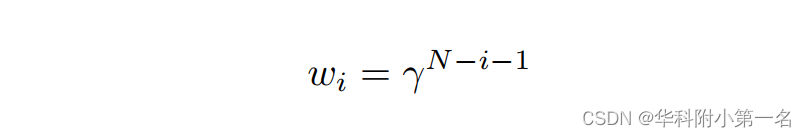
其中N为预测序列的长度,M(x)表示矩阵x的均值,wi可以通过计算,在训练中使用γ=0.8。
6. 实验
6.1. 实现细节
使用16 RTX 2080 Ti gpu、AdamW和OneCycle。
6.2. 与先进技术的比较

6.3. 消融实验