在摘要中,作者就阐明了写作本文的动机,人工智能在近几年由于廉价的数据和计算资源而得到复兴,但是人类智能的很多关键特征,AI还无法实现。具体来讲,作者指的是人类将已有的经验推广的能力还没能在AI中实现,这个能力在后文也被称作combinatorial generalization,也即通过组合已有的东西来获得新的东西。
本文的很大一部分是对之前工作的回顾和整合,还有一部分是提出了新的模型。作者在本文中强调的一个观点是:AI若是想要得到像人类一样的能力,那必须把combinatorial generalization作为一个优先实现的目标。而实现这个目标的关键是结构化的表示数据和计算(structured representation),在本文中,这个结构化的表示也就是用graph来表示数据。当前的深度学习方法都强调end-to-end,端到端的学习方式,而当数据量和计算资源没有现在这么丰富的时候,人们都是采取的hand-engineering的方式,手动设计各种模型。作者认为在这两种模型之间的选择不应该走极端,只要一个而不要另一个,应该是end-to-end和hand-engineering相结合来设计模型。本文探索了不同的深度学习模型是如何利用relational inductive biases来学习entities、relation和rule的(这几个概念后文都有具体解释)。本文提出的模型是graph network,这个模型整合了之前各种处理graph的模型,并做了延伸,这个模型还提供了一个直接的通路,使得结构化的知识(structured knowledge,指的就是graph一类非欧空间上的数据)可以直接产生结构化的行为(structured behavior这个概念到后文再看看具体指什么)。作者还讨论了graph network是如何支持relational reasoning和combinatorial generalization的,为更复杂更灵活的推理模型奠定了基础。
在introduction部分,作者首先就强调:人类智能的一个关键特征,就是能够将已有经验中的有限个元素(比如学到的单词)通过组合得到无限种结果,也就是摘要中提到过的combinatorial generalization。而本文的目的,正是探索如何通过基于graph数据以及在graph数据上的计算来提高AI的combinatorial generalization的能力。
作者认为,人类的这种组合推广(combinatorial generalization)的能力取决于我们的认知系统能够表示事物的结构,并且能够推断他们之间的关系,我们的大脑会将复杂的系统表示成实体及其相互作用的组合,比如判断一摞叠在一起的石头是否稳定。人类的认知可以通过层蹭抽象来去掉事物间细节上的差异,保留下最一般的共同点;人类可以通过组合已有的技能和经验来解决新的问题(例如去一个新地方可以将“坐飞机”、"去圣迭戈"、“吃饭”、“在一家印度餐馆”这几个已有的概念组合起来得以实现。);人类可以将两个关系结构(指的就是graph这种表示物体和物体间关系的数据)放在一起进行比较,然后根据对其中一个的知识,来对另一个进行推断。Kenneth Craik在1943年的书中提出,人类在认知外界的这些relation-structure(就是之前提到的通过关系结构表示事物,也就是graph来表示事物)的时候,其实大脑中是有相似的relation-structure来模拟这些外界的relation-structure的,这些大脑中的“working physical model”是和他们所代表的外界过程有着相同的工作方式。我们可以说,人类是通过一种组合的方式来认知世界的,当有新知识需要学习时,我们要么把新知识加入到已有的结构表示(structured representation)中,要么就调整已有的structure,使之同时适应新的和旧的知识。
在introduction的接下来的部分,作者先是介绍了,在数据不丰富的年代,人工设计structure,用设计好的结构来实现AI的各种功能,实现combinatorial generalization是人们实现人工智能的首选;而大数据时代到来之后,end-to-end的设计理念逐渐占据主导地位,人们希望模型能够足够灵活,能够自己去适应数据,因此structured approaches(其实这里的structured approaches概念很笼统,也不知道指的是什么,应该就是那些类似于知识库系统,早期的翻译系统那种人工设计好结构的模型,与之对立的就是深度学习系统这种端到端的设计方式)受到了冷落,因为事先设计好结构就意味着灵活性欠佳,不能像深度学习模型那样灵活的适应数据。但是作者强调,我们不能走极端,structured approaches和deep learning的手段要相互结合,才能取得更好的效果,他们不应该是对立的,而应该是相辅相成的。作者还提到最近出现的一些深度学习和structured approaches相结合的学习模型,具体来讲,其实就是处理graph数据的模型。这些模型可以处理离散的entities(graph的节点)和他们之间的relation(graph的边)。这些模型有着很强的relational inductive biases(在学习的时候对于某些结果有着偏向性,比如二次函数拟合,那就是完全偏向于学习出一个二次函数,而不是学习出其他函数)。在本文的接下来的部分,作者将首先探讨一下各种深度学习模型所带有的relational inductive biases,然后提出一般性的模型——graph networks,这个模型整合了现存的处理graph数据的模型,之后作者描述了用graph networks作为building block来实现强大的学习框架的关键设计原则。
Relational inductive biases
在这个部分,有一些概念需要澄清一下。第一个是relational reasoning:首先,structure指的是将一系列已知的building block组合在一起得到的产物。structured representation的含义是同时包含这种组合(元素的排列)以及structured computation,其中structured computation既在元素上进行,也在这些元素组成的整体上进行。而relational reasoning包括了通过使用rules对实体(entities)和关系(relation)的structured representation进行操纵。这句话说的很不明白,里面的几个概念解释如下:entity是一个有特征(attribute)的元素,比如一个有质量和尺寸的物理实物。relation是entity之间的性质,举例来讲两个entity之间的relation可以是same size as、heavier than等等。rule是一个函数,将输入的entity和relation映射到输出的entity和relation,这个概念说的很明确,但是作者接着给了几个例子就让人不太理解,作者的例子是:“IS ENTITY X LARGE?”和“IS ENTITY X HEAVIER THAN ENTITY Y?”。但是这两个例子我没有看懂是把哪个entity和relation映射到哪个entity和relation上。这句话之后,作者又加了一句话“Here we consider rules which take one or two arguments (unary and binary), and return a unary property value”,这句话说我们考虑的的rule的输入是一个或者两个,输出是一个值,按照这句话猜测,"IS ENTITY X LARGE?",X是unary的输入,而这句话的正确与否就是输出,yes或no,是unary的;“IS ENTITY X HEAVIER THAN ENTITY Y?”的输入就是binary的,一个是X一个是Y,输出也是yes或no,是unary的。这样来讲,rule其实是询问relation的一个问句,而不是像一开始说的那样,输出的也是entity和relation。还有一个要澄清的概念是inductive bias,这个概念顾名思义,就是在归纳推理(induct)的时候的偏向(bias),也就是在模型学习的时候,参数有倾向性的调节成某种种状态,模型有倾向性的学习成某一类样子。举例来讲,函数拟合的时候,把待拟合函数设置成二次函数,那么我们就有了一个偏向性,我们偏向了二次函数,偏向于把模型训练成二次函数,再比如CNN,每一个filter都是3×3且处处共享的,是抓取局部信息的,也就是说我们偏向于将模型学习成一个从局部逐渐抽象出高层信息,且参数共享的模型;再比如我们在函数拟合中加入一些二次的regularization term来使得参数不会过大,也是我们偏向于选择小的参数。这些偏向性表明了我们对模型的实现预判,可能是我们认为模型应该是什么样的,也可能是我们希望模型具有什么样的性质。
作者接下来探索了不同的深度学习模型的relational inductive biases(有别于inductive biases,后文中会看出),分析的时候考虑到了entity是什么,relation是什么,以及rule是怎么样的,这会有助于我们继续理解之前没明白的rule。
fully connected layer:输入vector,输出是vector与权重矩阵想乘并加上一个偏置向量的结果。entity就是网络的unit,relation是每一层的每一个unit都和相邻层的每一个unit相连,rule是通过权重矩阵和偏置向量来确定的,rule的输入是整个输入信号。整个模型中没有复用,信息之间也没有隔离,每一个unit都可以参与决定任何一个输出unit,和输出是没有关系的。因此,全连接层的relational inductive biases是很弱的,也就是模型并没有在归纳推断的时候偏向于哪个relation,而是一视同仁,每个unit都连接到所有下一层unit,自由度非常大。
convolutional layer:CNN中的entity还是unit,或者说是grid elements(例如image中的pixel),relation更加稀疏。相比于全连接网络,这里加入的relational inductive biases是locality和translation invariance,即局域性和平移不变性,局域性指的就是卷积核是大小固定的,就那么大,只抓取那么大的区域的信息,远处的信息不考虑;平移不变性指的是rule的复用,即卷积核到哪里都是一样的,同一个卷积核在各个地方进行卷积。到这我们可以看到,rule在深度学习的模型中的含义是如何将某一层的网络信息传递到下一层,而且是具体到权重的值是多少,后文还提到一句话“learning algorithm which find rules for computing their interactions”,也就是说,算法指的是计算框架,例如卷积操作之类的,而rule是学习到的具体的以什么权重进行卷积操作。
recurrent layer:这里的entity是每一步的输入和hidden state;relation是每一步的hidden state对前一步hidden state和当前输入的依赖。这里的rule是用hidden state和输入更新hidden state的方式。rule是在每一步都复用的,也就是说这里存在一个relational inductive biases是temporal invariance,时间不变性。
接下来作者开始介绍graph相关的模型。首先,作者提出set(集合)的概念,集合中的元素是没有顺序的,但是集合中元素的一些特征可以用来指定顺序,比如质量体积等等。因此,用来处理set或graph的深度学习模型应该是在不同的排序方式下都能有同样的结果,也就是对排序不变(invariance to ordering)。同时,作者强调处理set模型的relational inductive biases并不是因为有什么relation的存在,而恰恰是由于缺乏顺序,比如求一个solar system的中心位置,就是把各个planet的位置进行求平均,每一个planet都是对称的。如果使用多层感知机(MLP)来处理这个问题,那么就可能需要大量的训练才能训练出一个求平均的函数,因为MLP对每一个输入都是按照单独的方式处理,而不是一视同仁的处理所有输入。但是有的时候不仅要考虑这种排序不变性,例如计算solar system里每一个planet的运动,要考虑planet两两之间的相互作用。以上这两个例子其实是两个极端,一个是planet之间两两没关系,另一个是两两都有关系,而现实世界的很多模型是处在这两个极端之间的,即并不是每两个之间都没有联系,但也并不是两两之间都有联系,这也其实就是graph模型,每一个物体只与一部分其它物体进行相互作用。看到这我想到了一个问题,即graph其实是很抽象的东西,抓取的只是两两之间的相互作用关系,并不能表示空间位置关系,画出来的graph的示意图,相近的节点其实也并不一定代表这两个东西实际的空间位置相近,有连接的两个节点对应的物体实际可能空间位置相距甚远,反过来说,其实决定一个系统性质的也并不是系统内各个物体空间位置,而是物体间的相互作用,空间位置的相近可能会引发相互作用,把这种被空间位置引发的相互作用用graph表示了以后,其实空间位置就没什么用了,也就是说空间位置可能会间接起作用,直接起作用的还是相互作用。
Graph Networks:接下来作者简介了graph neural network的背景,应用等等,接着提出了自己的graph networks模型。作者在自己的模型中没有加入neural这个词,意在强调这个模型不一定需要通过neural network实现,也可以使用别的函数。graph network的主要计算单元是GN block,GN block是一个输入输出都是graph的graph-to-graph module。在graph中,前面说过的entity就被表示成节点(node),而relation被表示成边(edge),系统层面的特征用global attribute表示。GN框架通过block的这种组织结构强调可定制性、能够结合一些能表达我们需要的relational inductive biases的新结构。关键的设计原则是:灵活的表示、结构化的可配置的block内结构(block内部结构可以灵活修改)、可组合的多block架构。
为了描述GN block,首先要提出一些定义。graph用一个3元的元组(3-tuple)表示,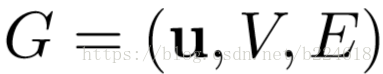
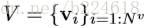
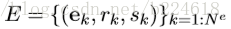

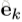
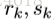

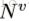
GN block的具体工作过程很清晰,可以用以下公式表述:

这几个公式就囊括了整个GN block完整的工作过程,其中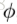
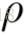
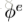
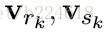
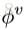
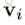

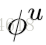


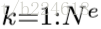
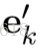
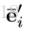

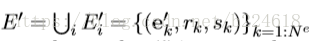
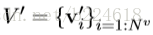
下面贴个图,是完整的GN block的计算过程的算法。

可见,这是一个函数,输入是graph的三个组成部分:node、edge、u。首先,函数在第一个循环中用更新edge的update function更新每一个edge,然后在第二个循环中,更新每个node的特征,然后用两个生成更新u所需信息的aggregation function生成相应的信息,最后更新u,函数最后的返回值就是更新后的edge、node、u。这里面,作者强调,函数
作者给了一个具体的例子来使这个更新过程更加具体可感,假定我们有一个系统,是由橡胶球以及球体之间相连接的弹簧(并不是任意两个球体之间都有弹簧,而是有些球体之间有弹簧,有些没有)构成。第一步update edge的信息可理解为计算和更新球体两两之间的作用力或者弹性势能之类的量;更新node信息可以理解为是根据这些更新好的势能或作用力等表征相互作用的量来更新球体的位置速度等信息;最后更新全局的信息可能是在计算总势能之类的全局量。在这个例子里,先更新哪个都不重要。
这种GN block的relational inductive biases是很强的,首先,每一个输入的graph的entity之间的relation都是不一定什么样的,也就是说GN的输入决定了representation之间是如何相互作用或者相互独立的,两个entity之间有直接的联系,就用一个edge连接以表示,没有直接的联系,就没有相应的edge,这两个entity之间也就不能直接相互作用,说到这就想到一个问题,有些时候人们并不会因为graph的两个node之间没有连接而不去让他们直接发生相互作用,例如在一篇人体动作识别的paper中,作者将人体关节两两之间都加上edge,来判断动作,这是因为有些关节之间虽然不是生理结构上直接相连的,但是组合起来却能完成一些动作,例如两个手拍手,这也就体现一个问题,graph中原有的edge并不一定体现我们在计算时所需要的相互作用,或者不全面,人体关节是否直接相连跟他们能否共同完成某些动作并不是唯一的决定性的关系,有很多不相邻的关节其实在我们识别动作时应该设置上相互作用的,比如两只手。relational inductive biases的第二点表现是graph将entity和entity之间的relation都用set(集合)来表示,这意味着GN对这些元素的顺序的改变要具有不变性。第三点更新graph的edge和node的函数是在所有的node和edge上复用的,这说明GN会自动支持combinatorial generalization,这是因为无论graph有多少node,node之间的连接是怎样的,GN都能够处理(其实不是很懂,但是这种解释越多,就越能感受作者想说的combinatorial generalization是什么意思)。
接着介绍graph network结构设计的设计原则,作者在这里强调,GN是不对attribute representation和函数的形式有什么限制的,但是本文会主要将注意力集中在深度学习的架构上,使得GN成为一个可学习的graph-to-graph的函数近似(function approximator,这个应该是指神经网络都是起到拟合函数的作用,因此训练出来的也就是一个函数的近似)。
1. flexible representation GN对graph representation的支持是很灵活的,一方面是global、edge、node的特征的表示都很灵活,可以是向量、tensor、sequence、set,甚至是graph。为了能和其他的深度学习结构对接,往往会将representation选为tensor或vector。此外,对于不同任务的不同需求,GN都能满足,edge-focused GN就输出edge,例如判断entity之间相互作用的任务;node-focused的就输出node,graph-focused的就输出global。另一方面,GN对输入graph的结构也没要求,什么结构都支持。我们得到的数据可能是entity之间所有的relation都已知的,也可能是都未知的,更多的时候介于这两个极端之间。有的时候,entity是怎么设定的也不知道,这时候可能需要假设,例如将句子中的每个词汇都视作一个node(entity)。relation不明确的时候,最简单的方法是假设所有entity之间都有联系,但这种方法在entity数量很大时不太好,因为这时edge数量随node数量平方增长。因此,relation缺失的问题,也就是从没结构的数据中推测出一些稀疏的结构,也是一个很重要的未来研究的方向(Neural relational inference for interacting systems,2018的ICML,值得一看)
2。 configurable within-block structure 这个主要是说GN block内部的结构是可以自由改变的,之前介绍了完整的GN block的工作过程,介绍了里面的信息的传输和使用的函数(函数未指定具体形式),但实际应用中,信息的传递结构和函数都可以随意指定,下图给出了几种形式。

图(a)是一个完整的GN block,其余的是变种。图(b)是函数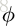
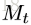
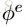
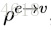
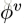
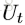
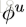


发表出来的NLNN模型其实是不考虑edge的,每两个node之间都会计算一个attention weight,然后加权求和(这也是为什么叫non-local,并不是局部进行卷积,而是全局进行加权),但是一些其他和NLNN类似的工作是只计算有edge相连的节点间的attention weights的,包括Attentional multi-agent predictive modeling(Hoshen 2017)和Graph attention networks。上图其实是将图(d)的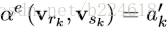
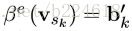

这三个公式的顺序应该是1、3、2,也就是先更新了edge,然后
接着作者简介一些其他的GN的变种,指出了完整的GN的各个部分根据需要都可以忽略,有的模型忽略了global信息,有的却只需要global信息,不需要的就算得到了也直接忽略就好。在输入的时候,如果有的信息没有,比如没有edge信息,那么就当成attribute vector的长度为0即可。
3. Composable multi-block artchitectures 设计graph networks的一个关键原则就是通过将GN block组合起来得到复杂的结构。因为GN block输出和输入一样都是graph,因此内部结构不同的GN block也可以方便的组合起来,就像标准的deep learning模型输入输出都是tensor一样。注意一点,不同的GN block组合起来可以复用内部的函数,就像展开的RNN一样,并且在合并input graph和hidden state的时候,可以采用LSTM或者GRU一样的gating机制,而不是简单地合并起来。
一些关于graph networks编程的问题,由于node和edge的update function都是在所有node和edge复用的,因此它们的更新都是可以并行计算的;此外,多个graph可以看成一个大的graph的不相连的子图,也可以并行起来计算。
最后是一些讨论。首先讨论一下graph networks的combinatorial generalization,作者说道,GN的结构很自然的会支持combinatorial generalization,因为计算不是在整个系统的宏观层面执行的,计算是在各个entity和relation上复用的,这使得之前从来没见过的系统也能够进行处理,感觉这个说的意思其实就是测试数据的graph可以是从未出现过的结构,也能进行处理,好像并不是什么那么高端的优点。一些相关的研究也探索了GN模型的能力(capacity),Battaglia在2016年的研究中发现用来进行单步物理状态预测的GN模型可以模拟未来成千上百步的系统变化,并且能够zero-shot迁移到一些之前未见到过的,entity数量是训练时系统entity数量的一半或两倍的系统上。之后又用一些例子介绍了GN能够胜任测试时entity数量与训练时相比差距巨大的任务。
接着分析了一些GN的局限性,一方面是有些问题无法解决,像是区分一些非同构的graph之类的问题,还介绍了一些相关的研究观点,但是我不是很懂背后的原因。另一方面是有些问题不能直接用graph来表示,像一些recursion、control flow、conditional iteration之类的概念至少需要一些额外的假设(举了个例子是interpreting abstract syntax tree),但其实这一部分我也不是很理解。后面还说表示这些概念要用programs和more computer-like的处理是更合适的,有些人认为这是人类认知的很重要的部分,目前还不是很理解。
深度学习模型可以直接处理原始的感受器得到的信息,但是GN需要的graph如何生成也是个问题,将得到的image,text搞成全连接的graph不是很好,而且直接将这些原始数据的基本元素视作entity也不见得合适,例如参与卷积的像素点并不是图片中的物体,而且实际物体之间的relation可能是稀疏的,如何获取这个稀疏性也是一个问题。因此,能够从原始数据中提取出entity是一个重要的问题(我在想,现在的图像识别算法,或者文字处理算法不能用来进行这个任务吗?)另一个存在的问题是,在计算的过程中,graph也可能发生变化,例如某一个entity代表的物体可能会破碎,那么代表这个物体的node也应该相应的分离开来,类似的,有些时候物体之间的关系也会发生变化,需要添加或者去除edge,这种适应性的问题也正在被研究,现在已经有一些识别graph的underlying structure(潜在的结构)的算法可能是可以用来进行这个任务的。
由于GN的行为和人类对世界的理解类似,都是将世界解释成物体和相互关系组成的,因此GN的行为可能会更加容易解释,变得更加易于分析,更容易可视化。探索GN的可解释性也是未来一个有趣的方向。
虽然本文是将注意力集中在graph上的,但是与此相关的一个方向便是将deep learning和structured representation相结合,相关的工作有很多,作者举了几个例子,都不是很懂。其他还有一些方法试图通过模仿电脑的软硬件来更好地抓取不同的结构。