论文标题: Relational inductive biases, deep learning, and graph networks
 论文地址: https://arxiv.org/pdf/1806.01261.pdf
论文地址: https://arxiv.org/pdf/1806.01261.pdf
项目地址:https://github.com/deepmind/graph_nets
文章导读
这篇文章联合了DeepMind、谷歌大脑、MIT和爱丁堡大学的27名作者(其中22人来自DeepMind),用37页的篇幅,对关系归纳偏置和图网络(Graph network)进行了全面阐述。
那么,这篇论文是关于什么的呢?DeepMind的观点和要点在这一段话里说得非常清楚:
这既是一篇意见书,也是一篇综述,还是一种统一。我们认为,如果AI要实现人类一样的能力,必须将组合泛化(combinatorial generalization)作为重中之重,而结构化的表示和计算是实现这一目标的关键。
正如生物学里先天因素和后天因素是共同发挥作用的,我们认为“人工构造”(hand-engineering)和“端到端”学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益。
在论文里,作者探讨了如何在深度学习结构(比如全连接层、卷积层和递归层)中,使用关系归纳偏置(relational inductive biases),促进对实体、对关系,以及对组成它们的规则进行学习。
他们提出了一个新的AI模块——图网络(graph network),是对以前各种对图进行操作的神经网络方法的推广和扩展。图网络具有强大的关系归纳偏置,为操纵结构化知识和生成结构化行为提供了一个直接的界面。
作者还讨论了图网络如何支持关系推理和组合泛化,为更复杂、可解释和灵活的推理模式打下基础。
论文简介
Abstract
人工智能最近经历了一场复兴,在视觉、语言、控制和决策等关键领域取得了重大进展。取得这些进展的部分原因是由于廉价的数据和计算资源,它们符合深度学习的天然优势。然而,在不同压力下发展起来的人类智力,其许多决定性特征对于目前的方法而言仍是触不可及的。特别是,超越经验的泛化能力——人类智力从幼年开始发展的标志——仍然是现代人工智能面临的巨大挑战。
本论文包含部分新研究、部分回顾和部分统一结论。我们认为组合泛化是人工智能实现与人类相似能力的首要任务,而结构化表示和结构化计算是实现这一目标的关键。正如生物学把自然与人工培育相结合,我们摒弃“人工构造”与“端到端”学习二选一的错误选择,而是倡导一种利用它们互补优势的方法。我们探索在深度学习架构中使用关系归纳偏置如何有助于学习实体、关系以及构成它们的规则。我们为具有强烈关系归纳偏置的 AI 工具包提出了一个新构造块——图网络(Graph Network),它泛化并扩展了各种对图进行操作的神经网络方法,并为操作结构化知识和产生结构化行为提供了直接的接口。我们讨论图网络如何支持关系推理和组合泛化,为更复杂的、可解释的和灵活的推理模式奠定基础。
1 Introduction(介绍)
一些定义和阐述:
-
组合泛化(combinatorial generalization):对应的是语言的可以无限生成的能力, 从有限的词汇和规则中,通过组合可以生成无限的序列和意义。论文中的定义为:constructing new inferences, predictions, and behaviors from known building blocks。
-
认知机制(cognitive mechanism):对关系的复杂心理结构表征, 以及基于关系的推理, 构成了人的认知系统, 而认知系统衍生了人类强大的组合泛化能力。
-
接着,介绍了解释的本质(The Nature of Explanation),是学术界对人去理解解释世界的模型。
指出我们在学习的时候(接受一个正确实例的时候), 可以做两个事情: -
将新的知识放入已有的结构化知识框架
-
调整框架去适应新的知识.
-
现在的实现组合泛化的系统
逻辑、语法、经典规划、图形模型、因果推理、贝叶斯非参数化和概率规划(logic, grammars, classic planning, graphical models, causal reasoning, Bayesian nonparametrics, and probabilistic programming);
其下面的子领域都明确的以实体和关系为中心进行学习。
人工智能的核心问题是如何构建表现出组合泛化的人工系统,也是许多结构化方法的核心。
- 结构化方法如此重要的原因
部分是因为数据和计算资源非常昂贵,而结构化方法的强归纳偏置对改进的样本复杂性非常有价值。 - 目前深度学习方法状况
现代深度学习方法经常遵循“端到端”设计理念,强调最小的先验表征和计算假设,并试图避免显式结构和“人工构造”。并且在很多领域取得了显著成果,比如,图像分类,自然语言处理等等。但是这样就需要大量的数据和大量的计算时间. 并且其无法解决一下几种问题:
(1)复杂的语言以及场景的理解
(2)结构化数据的推理
(3)不同训练条件下的迁移学习
(4)小数据量的任务
需要解决这些问题,就需要添加组合泛化( combinatorial generalization) - 早期的结构化方法(有着强归纳偏置) 来解决上述无法解决的问题
在模拟制造、语言分析、符号操作和其他形式的关系推理等领域中,研究人员开发了各种创新的表示和推理结构化对象的子符号方法( sub-symbolic approaches)以及关于大脑如何工作的更加综合的理论(more integrative theories for how the mind works)。 - 结构的方法和深度学习方法结合
文章认为现代人工智能的一个核心是将组合泛化作为首要任务,提倡采用综合方法来实现这一目标,将基于结构的方法和深度学习方法结合起来。最近,在深度学习和结构化方法的交集中出现了一类模型,这些模型关注于对显式结构化数据,特别是对图进行推理的方法。这些方法的共同之处在于,它们都具有在离散实体,以及实体之间的关系上执行计算的能力(have in common is a capacity for performing computation over discrete entities and the relations between them)。 最重要的是,这些方法带有强烈的关系归纳偏置(relational inductive biases),以特定的架构假设的形式,引导这些方法学习实体和关系。
- 文章接下来章节的介绍
(1)通过关系归纳偏见的视角来研究各种深度学习方法,表明现有的方法往往带有关系假设,这些假设并不总是显式的或立即可见的。
(2)提出了一个基于实体和关系的推理的通用框架——我们称之为图网络(graph networks)——用于统一和扩展现有的对图进行操作的方法,并描述了使用图网络作为构建块构( building blocks)建强大架构的关键设计原则。
Box1: Relational reasoning(关系推理)
结构(structure):一组构建块(building block)组成的产物
结构化表示(structured representations):获取结构的组成成分(即元素(element)的排列)
结构化计算(structured computations):把元素(element)及其组成作为一个整体进行操作
关系推理(relational reasoning):操纵实体(entities)和关系(relations)的结构化表示,并使用关于如何构成它们的规则(rules)
- 实体(entity):具有属性的元素
- 关系(relation):实体之间的属性
- 规则(rule):将实体和关系映射到其他实体和关系的函数
2 Relational inductive biases(关系归纳偏置)
Box 2: Inductive biases(归纳偏置)
归纳偏置(Inductive biases)允许学习算法将一种解决方案(或解释)优先于另一种解决方案(或解释),而与观察到的数据无关。理想情况下,归纳偏置既可以改善对解决方案的搜索,又不会显著降低性能,并有助于找到以理想方式推广的解决方案;但是,不匹配的归纳偏置通过引入太强的约束也可能导致次优性能。
归纳偏置可以表达关于数据生成过程或解决方案空间的假设。这些假设不需要明确 ,只是解释了模型或算法如何与世界的连接。
- 深度学习中的各种模型其实就可以看作是由不同的初级构建块(building block) 组成的复杂的深层的层级结构或者图结构。初级building block包括, “fully connected” , "convolutional layers"等。
- 复杂的结构, 例如 多层感知器(MLP)就是由多个 “fully connected” 组成的。 这个时候, “MLP” 也可以作为一个building block。
- 卷积神经网络(CNNs)就是由 “convolutional layers” 和 “MLP” 组成的一个新的building block。
- 最重要的是, 不同的building block都包含着不同的 “relational inductive biases”, 也就是不同的设计指导思想.
文章中提到了几个例子:

表 1:标准深度学习组件中的各种关系归纳偏置。详见论文原文第 2 节。 - 探讨深度学习方法中的关系归纳偏置
深度学习中,entities和relaitions是分布表征,也就是不同building block的输出。
rules是 neural network function approximators(神经网络函数逼近器)、也就是各层之间的激活函数。
每个深度模型的entities, relations 和 rules都是不一样的, 为了更好的理解他们, 这里定义了几个术语:
(1)arguments : 是 rule functions的输入, 就是entities和relations
(2)reused, shared : 指的是 rule functions 是否被reused或者shared(也就是说不同relation(连线)之间是否使用相同的rules(激活函数,不同权重算不同函数)).
(3)interactions, isolation : 得出的结果是全部entities之间协作的结果的话就是interactions, 否则就是isolation。
2.1 Relational inductive biases in standard deep learning building blocks(标准深度学习构建块中的关系归纳偏置)
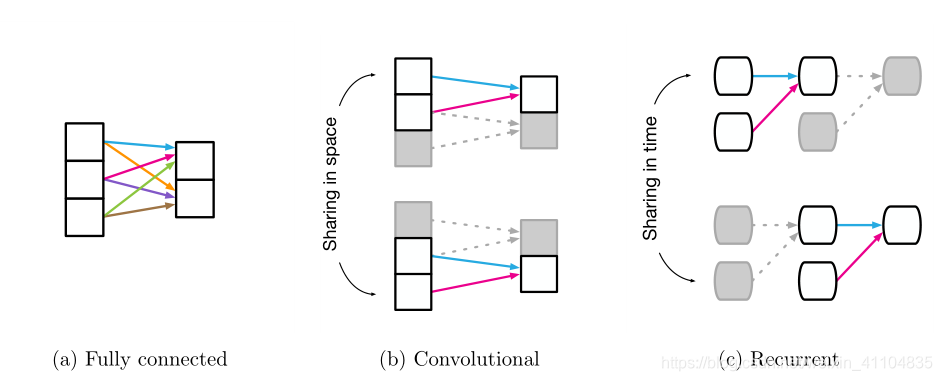
图 1:重复使用和共享常见的深度学习构件。(a)全连接层,其中所有权重都是独立的,没有共享。(b)卷积层,其中局部核函数在输入端被多次使用。共享权重由具有相同颜色的箭头指示。(c)循环层,其中相同的功能在不同的处理步骤中重复使用。
2.1.1 Fully connected layers(全连接层)
- entities : the units in the network
- relations : all-to-all( all units in layer i are connected to all units in layer j )
- rules : specified by the weights and biases
- The argument to the rule is the full input signal, there is no reuse, and there is no isolation of information.
- relational inductive bias : very weak: all input units can interact to determine any output unit’s value, independently across output
2.1.2 Convolutional layers(卷积层)
- entities: still individual units (or grid elements, e.g. pixels)
- relations: sparser,不再是all-to-all
- relational inductive biases: locality and translation invariance
locality : 意思是空间相近的实体有联系远的没有
translation invariance : 局部单元对于rules(核函数)的复用
distal entities之间是isolated 的,entities之间不会产生协作
2.1.3 Recurrent layers(循环层)
- entities:the inputs and hidden states at each processing step
每个处理步骤中的输入和隐藏状态 - relations: the Markov dependence of one step’s hidden state on the previous hidden state and
the current input,前一隐藏状态和当前输入的一步隐藏状态的马尔可夫依赖性 - rule : 接受 a step’s inputs 和 hidden state作为arguments to update the hidden state
- reused : The rule is reused over each step
- relational inductive bias : temporal invariance
- entities全部是Interaction
2.2 Computations over sets and graphs(集和图的计算)
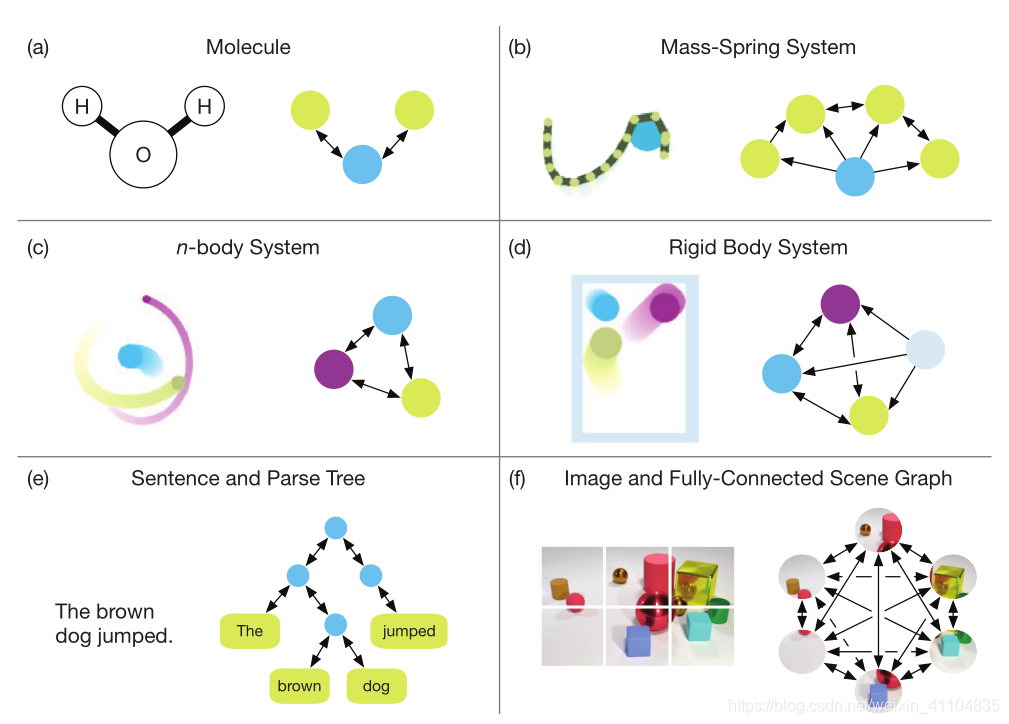
图 2:不同的图表征。(a)一个分子,其中每个原子表示为对应关系的节点和边(Duvenaud 等,2015)。(b)一个质量弹簧系统,其中绳索由在图中表示为节点的质量序列定义(Battaglia 等,2016;Chang 等,2017)。(c)一个 n 主体系统,其中主体是节点,底层图是完全连接的(Battaglia 等,2016 年;Chang 等,2017)。(d)一个精密的主体系统,其中球和壁是节点,底层图形定义球之间以及球和壁之间的相互作用(Battaglia 等,2016 年;Chang 等,2017)。(e)一个句子,其中单词对应于树中的叶子,其他节点和边可以由解析器提供(Socher 等,2013)。或者,可以使用完全连接的图(Vaswani 等,2017 年)。(f)一张图像,可以分解成与完全连接图像中的节点相对应的图像块(Santoro 等,2017;Wang 等,2018)。
- 具有处理结构性知识的模型
我们到目前的关于模型的定义通常采用图示,以及一些特殊的定义, 并没有赋予他们在一个广义框架下的明确的定义方式。论文想做的一个是实体和关系的明确表示和抽象化数学定义, 以及利用这种数学定义去表达知识中的结构特性,以及设计一个学习算法用于计算其交互作用的规则,也就是rules。 - entities in the world (such as objects and agents) do not have a natural order; rather, orderings can be defined by the properties of their relations.真实世界的物体之间通常是没有order的, 但是, 他们之间的order是可以通过他们的关系的属性去决定的。
- Sets 通过顺序不明确或是不相关的实体描述的系统的自然表示。具体可以参考文中的solar system examples的例子。
3 Graph networks(图网络)
首先简介过往有关 ‘graph nerual network’ 任务。其次, 提出自己的 ‘graph network framwork’。
3.1 Background(背景)
- 介绍了很多利用图神经网络模型(Models in the graph neural network)做的任务
- 介绍了一些利用graph neural network模型去解决需要对离散的实体和关系进行推理的任务。 例如组合优化问题, boolean satisfiability(布尔可满足性问题), 以及 performing inference in graphical models等。
- 列出了和graph neural networks相关的论文
3.2 Graph network (GN) block(图网络块)
提出的图网络框架
-
文章中提出的图网络(GN)框架定义了一类对图结构表征进行关系推理的函数。该 GN 框架泛化并扩展了多种图神经网络、MPNN 和 NLNN 方法。
-
功能
supports constructing complex architectures from simple building blocks.
支持用简单的 building blocks构建复杂的结构。
注意:没有在graph network中使用neural术语,以反映它可以用函数而不是神经网络来实现,虽然在这里关注的是神经网络实现。 -
组成
(1) GN框架的基本计算单元是 GN block,也就是一个“graph-to-graph”模块,输入是graph (表现在网络中就是unit, 结合任务比如说神经翻译,就可以是词向量, 字符向量等等),在结构层面上执行计算,输出也是graph。
(2) graph’s nodes表示entities,the edges表示relations ,global attributes表示system-level properties
(3)GN 框架的模块组织强调了可定制性,并能合成可以表达关系归纳偏置的新架构。其关键的设计原则是:灵活的表征(Flexible representations);可配置的模块内部结构(Configurable within-block structure );以及可组合的多模块框架( Composable multi-block architectures)。具体参考第四章。
Box 3: Our definition of “graph”
论文作者用 “graph” 表示具有全局属性的有向(directed)、有属性(attributed)的 multi-graph。一个节点(node)表示为,一条边(edge)表示为,全局属性(global attributes)表示为u。和表示发送方(sender)和接收方(receiver)节点的指标(indices)。具体如下:
- Directed:单向,从 “sender” 节点指向 “receiver” 节点。
- Attribute:属性,可以编码为矢量(vector),集合(set),甚至另一个图(graph)
- Attributed:边和顶点具有与它们相关的属性
- Global attribute:graph-level 的属性
- Multi-graph:顶点之间有多个边
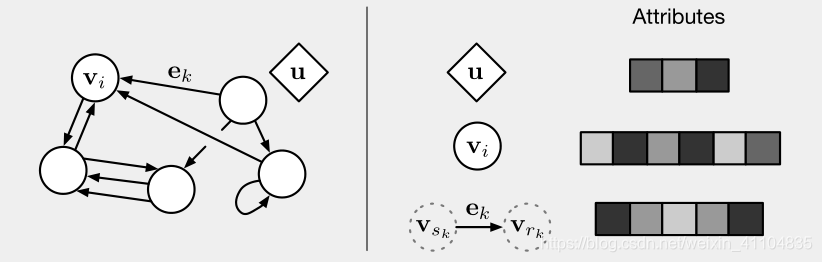
- 用一个例子来更具体地解释 GN
考虑在任意引力场中预测一组橡胶球的运动,它们不是相互碰撞,而是有一个或多个弹簧将它们与其他球(或全部球)连接起来。我们将在下文的定义中引用这个运行示例,以说明图形表示和对其进行的计算。
3.2.1 Definition of “graph”
- 论文中的解释
在我们的 GN 框架中,一个 graph 被定义为一个 3 元组的G= (u,V,E)
u 表示一个全局属性,例如,u 可能代表重力场。

- 如果不太清楚的话,可以看简洁的解释

3.2.2 Internal structure of a GN block(GN块的内部结构)

- 三个更新函数中含有三个聚合函数
- 对每一个边的状态进行的更新

- 对每一个节点的状态进行的更新

其中:

它是一个聚合函数, 其接受参数为一个边的集合, 然后利用集合中所有边的信息去调整一个node的状态。 - 对全局状态进行更新

其中包含两个聚合函数:

第一个,其接受参数为一个边的集合, 然后利用集合中所有边的信息去调整全局状态。
第二个,其接受参数为一个点的集合,然后利用集合中所有点的信息去调整全局状态。 - 聚合函数需要具有的特点
输入顺序不变, be invariant to permutations of their inputs
参数的数量可变,take variable numbers of arguments
3.2.3 Computational steps within a GN block(GN块的计算步骤)
- 算法 1:一个完整的 GN block 的计算步骤

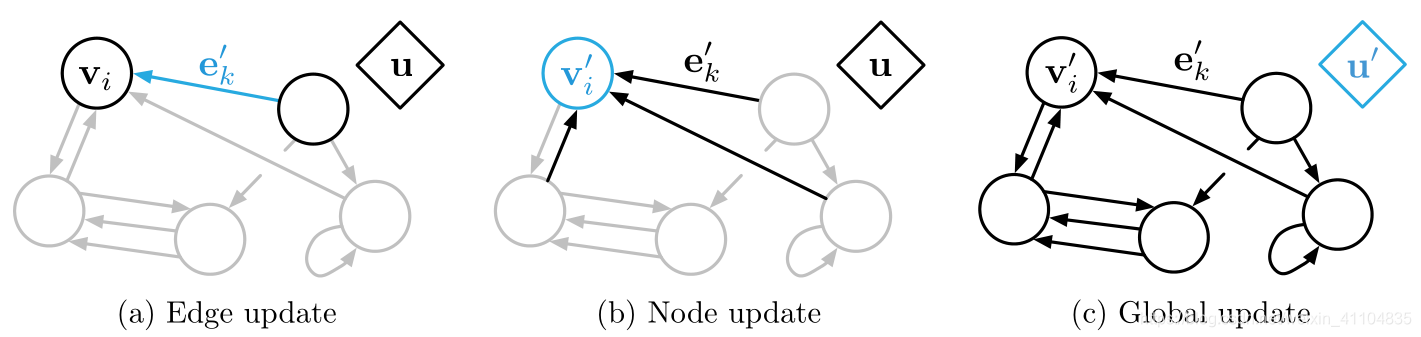
图3:GN 区块中的更新。蓝色表示正在更新的元素,黑色表示更新中涉及的其他元素(请注意,更新中也使用蓝色元素表示前更新值)。有关符号的详细信息,请参见等式 1。 - 当一个graph作为 GN block的输入时,计算过程从edge到node,再到global level。 值得注意的是,计算顺序不是固定的,是可以改变的。
- 具体步骤:
可以参考论文中的具体解释,并用了橡胶球的运动的例子进行了说明。不过和3.2.2中论述的相差不大。
3.2.4 Relational inductive biases in graph networks(图网络中的归纳偏置)
- 在学习的过程中,GN framewor如何实现strong relational inductive biases
(1)graph本身可以根据实体和关系去设计。在之前的网络结构中, 我们通常是对node没有进行关于输入的分别, 而是一视同仁, 即任何词汇都可以instantiated到每个node. 但是, 其实(为了准确, 放上原文):
graphs can express arbitrary relationships among entities, which means the GN’s input determines how representations interact and are isolated, rather than those choices being determined by the fixed architecture.
个人理解是, graph的node之间的关系是可以根据对node的输入来定的, 这样的话, 网络架构就会变成一个动态的架构。
(2)图关于entities和他们之间的relations是的表征是基于set的。也就是说, 对于参数位置的交换是没有反应的。GN block对于参数的顺序不敏感, 这个就支持了对于很多对顺序不敏感的模型的支持。
(3)每个node和每个edge都是可以被复用的, 这个就支持了组合泛化。这个是相当重要的,在决定了GN block后可以根据实例改变size以及shape。
4 Design principles for graph network architectures(图网络结构的设计原则)
接着针对深度模型的 graph network 设计规则,让GN block 成为一个可学习的 图到图函数逼近器(graph-to-graph function approximator)。
4.1 Flexible representations(灵活表示)
- GN 支持flexible graph representations表现在两个方面:
(1)the representation of the attribute,属性值表征的灵活性
(2) the structure of the graph itself,图的结构本身的灵活性
4.1.1 Attributes(属性)
- attributes的表现形式
GN block中的global, ledge,node属性的表示形式可以是任意的。深度学习中,通常使用real-valued vectors and tensors表示。对于数据结构,常常使用sequences, sets, or even graphs - attributes的表示取决于任务的要求,要求不同,表示也不同。
- 输出单元
根据任务的不同, global, ledge,node的输出也是不同的,有三种基本类型的输出:
(1)An edge-focused GN: uses the edges as output
(2)A node-focused GN: uses the nodes as output
(3)A graph-focused GN: uses the globals as output - 依据任务的不同,nodes, edges, and global也可以混合匹配输出
4.1.2 Graph structure(图结构)
- 把输入数据表示成graph的时候,会出现两个问题:第一,输入数据明确指定了关系结构。第二,输入数据没有指定关系结构,但是关系结构可以推断或者假设出。
- 第一个问题
有着明确实体和关系的数据的例子有:知识图谱,社交网络,解析树,优化问题,化学图,道路网和具有已知交互的物理系统 - 第二个问题
关系结构不明确,需要推断或者假设的数据的例子有:视觉场景,文本语料库,编程语言源代码和多代理系统 - 对于问题举出的具体的例子可以看一下论文
4.2 Configurable within-block structure(可配置的块内结构)
- 通过定制 GN block 中的函数改变模型功能的案例,体现了 GN 的灵活性
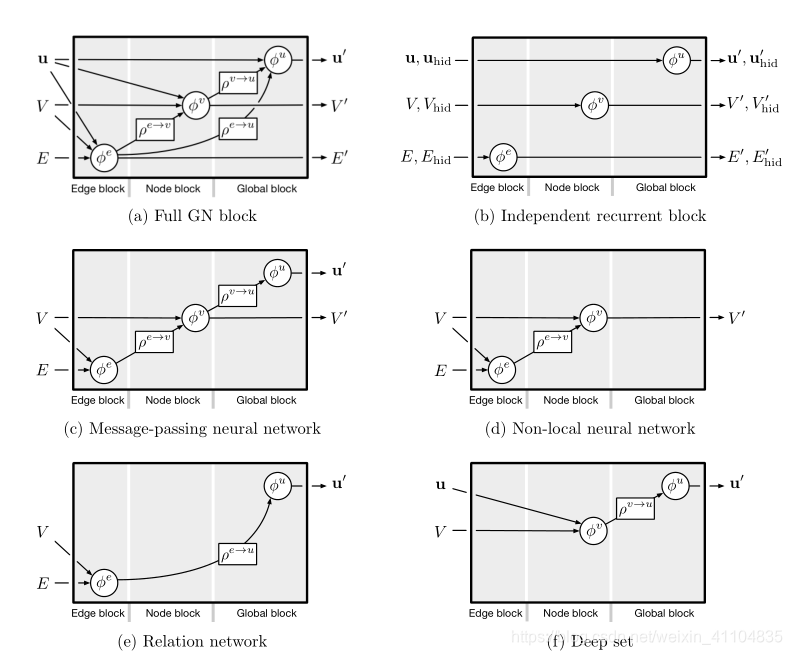
图4:不同的内部GN块配置。 有关表示的详细信息,请参阅第3.2节;有关每个变量的详细信息,请参阅第4节。 (a)基于传入节点,边缘和全局属性,一个完整GN可以预测节点,边和全局输出属性。 (b)独立的循环更新块采用输入和隐藏图形,φ函数是RNN(Sanchez-Gonzalez等,2018)。 (c)MPNN(Gilmer等,2017)基于传入的节点,边缘和全局属性预测节点,边缘和全局输出属性。 请注意,全局预测不包括聚合边。 (d)NLNN(Wang等,2018c)仅预测节点输出属性。(e)关系网络(Raposo等,2017; Santoro等,2017)仅使用边缘预测来预测全局属性。 (f)深度集(Zaheer等,2017)绕过边更新并预测更新的全局属性。
4.2.1 Message-passing neural network (MPNN)(消息传递神经网络(MPNN))
介绍了消息传递神经网络模型
4.2.2 Non-local neural networks (NLNN)(非局部神经网络(NLNN))
介绍了非局部神经网络模型,基于加权图模型。
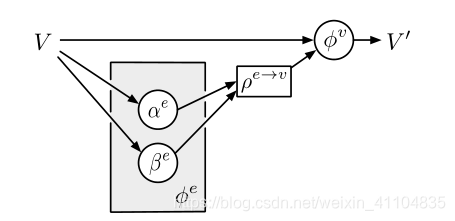
图5:NLNN作为GN。 示意图显示了如何在GN框架下通过φe和ρe→v实现NLNN(Wang等,2018c)。 通常,NLNN假设不同的区域
图像(或句子中的单词)对应于完全连接图中的节点,并且注意机制在聚合步骤期间定义节点上的加权和。
4.2.3 Other graph network variants(其他图网络变种)
介绍了其他图网络的变种模型
4.3 Composable multi-block architectures(可组合的多块体结构)
- 一个GN block的输入和输出都是 graph, 那么一个Block的输出就可以当成另外一個BLock的输入,即:
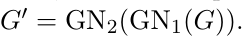
- 接下来,介绍三个组合方式:
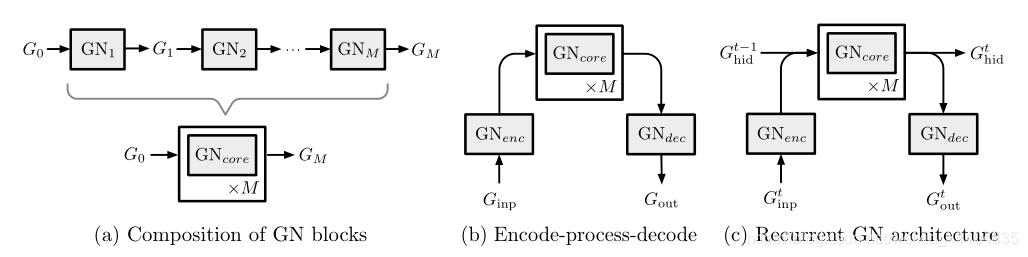
图6:(a)按顺序组成多个GN块以形成GN“核心”的示例。 这里,GN块可以使用共享权重,也可以是独立的。 (b)编码 - 处理 - 解码架构,它是组成GN块的常用选择(见4.3节)。 GN编码输入图,然后由GN核处理。 核心的输出由第三个GN块解码为输出图形,其节点,边缘和/或全局属性将用于特定于任务的目的。 (c)在顺序设置中应用的编码 - 处理 - 解码架构,其中核心也随着时间推移(可能使用GRU或LSTM架构),除了在每个时间步骤内重复之外。 合并的行表示连接,分割线表示复制。
4.4 Implementing graph networks in code(在代码中实现图网络)
Box 4:Box 4: Graph Nets open-source software library: github.com/deepmind/graph_nets
举了三个例子,可以到项目中下载下来,自己学习一下
4.5 Summary(小结)
从三个角度讲了GN的设计原则. 是从底到上的顺序
-
最底层, 从 GN 的属性设置和graph 边的设计方法阐释了 GNN 的灵活性
-
从GN 的多种变种阐述了 GN 的灵活性
-
从GN 的组合来阐述灵活性
5 Discussion(讨论)
5.1 Combinatorial generalization in graph networks(图网络中的组合泛化)
介绍了证明 graph network 具有组合泛化能力的论文
5.2 Limitations of graph networks(图网络的局限性)
介绍了GN不能解决的一些问题
5.3 Open questions
5.4 integrative approaches for learning and structure
强调本文主要在graph network计算部分, 而在设计思路上只给出了以下的几个方向:
(1)linguistic trees
(2)partial tree traversals in a state-action graph
(3)hierarchical action policies
(4)capsules
(5)programs
5.5 Conclusion(结论)
强调了组合优化的重要性,肯定 graph network的同时, 也承认了他的不足, 并且提供了几个作者认为有意思的有前途的但是不是很热门的方向,具体可以看一下论文。
参考
[1] https://blog.csdn.net/qq_32201847/article/details/80708193
[2] https://zhuanlan.zhihu.com/p/38861547
[3] https://zhuanlan.zhihu.com/p/38310918
[4] 机器之心.学界 | DeepMind等机构提出「图网络」:面向关系推理
[5] 新智元.【CNN已老,GNN来了】DeepMind、谷歌大脑、MIT等27位作者重磅论文,图网络让深度学习也能因果推理