本文是对《Inductive representation learning on temporal graphs》一文的浅显翻译与理解,原文章已上传至个人资源,如有侵权即刻删除。
文章目录
前言
文章在GraphSAGE和GAT的基础上,提出了temporal graph attention(TGAT)算法,该算法将从Bochner理论中发展出的时序编码技术,与自我注意力机制相结合,来有效聚合时序拓扑结构的邻居特征,从而学习时间特征的交互。
算法以自我注意力机制为框架,将原有的位置编码替换为时序编码。对时序编码,目的在于构建一个从时间域到向量空间的连续函数映射,由于直接推导该函数比较复杂,引入核函数并参照Bochner理论,展开为傅里叶级数。利用欧拉公式和蒙特卡洛积分得到核函数最终解后,再反推得到连续函数。
对连续函数中存在的参数,即维度d,算法进行了相关证明,一方面证明了d的大小较小,另一方面将核函数学习转化为对分布学习的问题。从而提出了参数化和非参数化两类思想来解决分布学习,并主要关注于非参数化的解决方案,以上即为算法的核心思想。
该算法的实现形式为一个TGAT层,该层可视为局部聚合器,以时序邻居及它们的隐藏表征(或特征)及时间戳为输入,以目标节点在任意时间点的时间感知表示为输出。除将邻居特征和目标节点的隐藏表征结合起来等基本条件外,算法还考虑了使用多端注意力,以及引入边特征等扩展。
Title
《Inductive representation learning on temporal graphs》
——ICLR2020
Main body
1 Self-attention mechanism
自我注意力机制一般由两部分构成:嵌入层和自我注意力层。
自我注意力使用位置编码来对位置信息建模,即每个位置k都表示一个向量p_k。
对一个有序实体序列e = (e_1,…,e_l),嵌入层使用实体嵌入(或特征)及其位置编码的加和或连接作为输入:
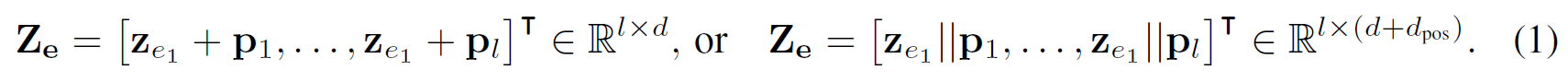
其中||表示连接操作,d_pos为位置编码的维度。
自我注意力层可以在按比例扩大点积注意力的基础上构建,即:
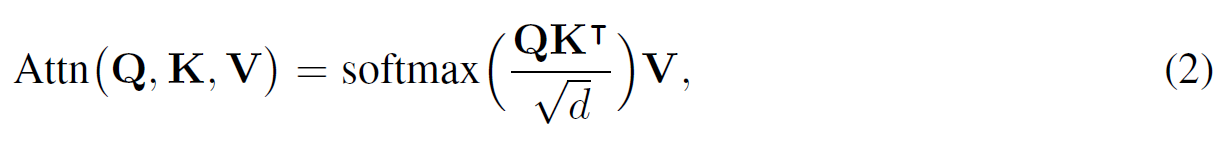
其中Q为’queries’,K为’keys’,V为’values’,它们被视为来自嵌入层输出的映射,即:
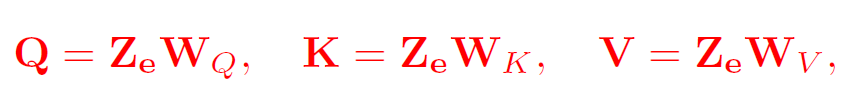
其中三个W为映射矩阵,Q、K和V的每一行都表示一个实体,Q和K进行计算构成权重,V中包含实体本身具有的值。则对点积注意力下的实体序列,其隐藏表示即为:
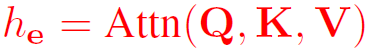
2 Functional time encoding
目标是得到一个从时间域到d_T维向量空间的连续函数映射,来代替式(1)中的位置编码。对序列中的第k个实体,用一个时间特征t_k得到的Φ(t_k)来代替向量p_k。
假设时间域可以表示为T=[0,t_max],对式(2)中的点积自我注意力,通常K和Q由Z_e在式(1)中的id或线性映射给出。
通常来说,对函数的学习是非常复杂的,在此即使用核函数K来代替对函数Φ的学习,时序核函数有:
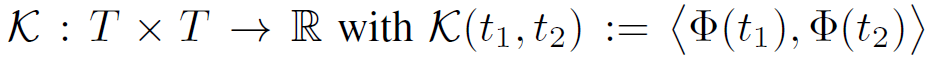
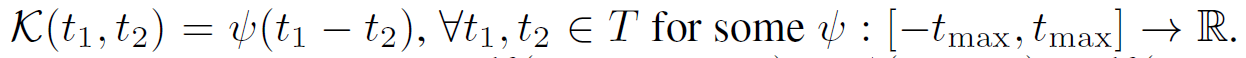
该函数具有平移不变性,因为两个时间即便等值增加,最终结果仍然为两时间的差值。
即便如此,仍然需要对Φ明确参数化,来建立有效的梯度优化。因此受Bochner’s theorem的启发,文章认为任何关于时间的周期函数都能展开成傅立叶级数,则有定理1如下。
Theorem 1 (Bochner’s Theorem):
一个连续且平移不变的核函数K(x,y) = ψ(x-y)在R上是正定的,当且仅当R上存在一个非负测度,使得ψ为该测度的傅里叶变换。因此,在适当缩放时,时序核函数K具有替代表达式,即:
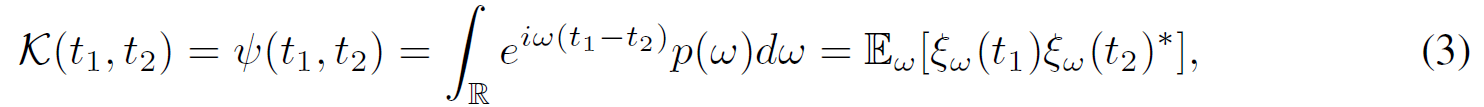
其中ξ_w(t)=e^ (iwt),有欧拉公式为e^ix = cosx + isinx。由于K和概率测度p(w)为实数,此处提取实数部分,即只保留cosx,从而由式(3)推导至(4)。
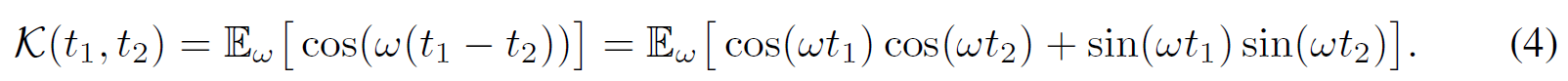
上述公式近似于蒙特卡洛积分的期望,即:
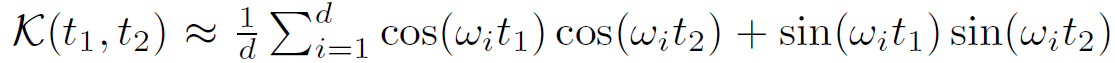
有w1,…,wd为p(w)的独立同分布,因此可以得到有限维的函数映射如下,且易得近似关系有:
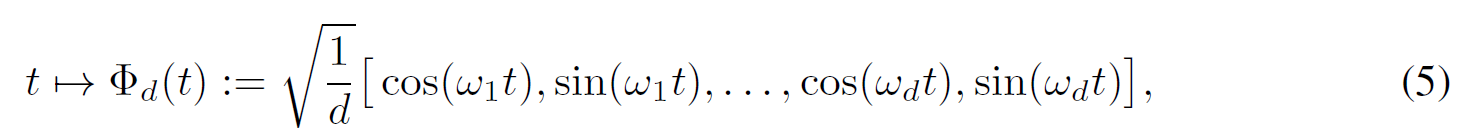
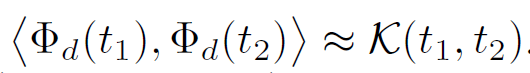
事实上,仅需合理数量的样本即可实现正确的估算,有声明1如下。
Claim 1:
设p(w)为Bochner定理中针对核函数K所述的相应概率测度,假设使用样本{wi}^d如上所述构建特征映射Φ,则只需d个样本就有:
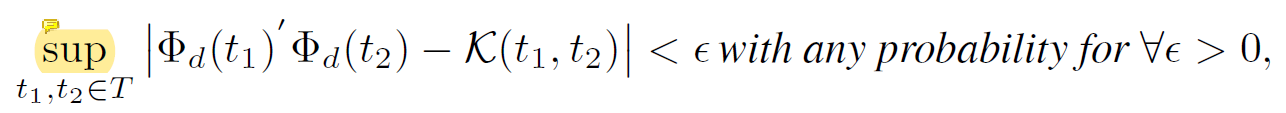
其中σ是关于p(w)的第二动量(可理解为梯度优化的速度向量),有d为:
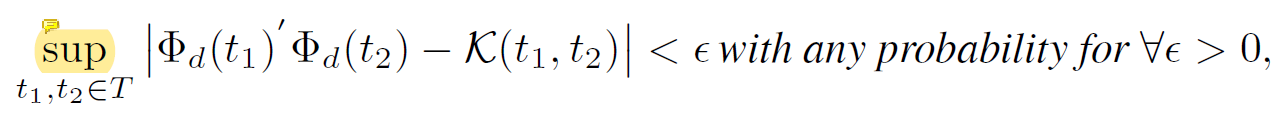
因而,可以将核函数学习转化为分布学习的问题,即评估p(w)。
一个直接的解决方案是,通过使用具有已知边际分布的辅助随机变量来应用重新参数化技巧,如在变分自编码器中一样,但再参数化往往受到分布规模的限制。另一种方法是使用逆累积分布函数(CDF)转换,该方法通过学习由基于流的网络参数化的逆累积分布函数,并从相应分布中抽取样本。
另一方面,如果我们考虑无参数化方法来估算分布,那么学习到的F^-1及从中得到的d个样本就等同于直接优化式(4)中的{w1,…,wd}作为自由模型参数。
事实上这两种方法具有相似的高性能,因此本文主要关注于无参数化方法,因为其参数更有效且训练速度更快。这种函数时序编码可以与自我注意力机制很好地结合,因此就能够用其来代替式(1)中的位置编码。
3 Temporal graph attention layer
设vi和xi分别表示节点i及其原始节点特征,TGAT算法仅依赖于时序图注意力层。
该层可视为局部聚合器,以时序邻居及它们的隐藏表征(或特征)及时间戳为输入,以目标节点在任意时间点的时间感知表示为输出,定义节点i在t时间来自第l层的隐藏表示输出为:
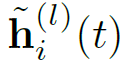
对节点v0在t时间,设其邻居为N(v_0;t) = {v_1,…,v_N},则TGAT层的输入为邻居信息Z及目标节点在当前时间的信息,即:
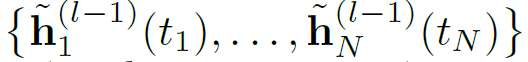
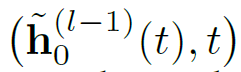
当层数l为1时,输入即为原始节点特征。
基于平移不变性的假设,算法使用当前时间与交互时间之差作为交互时间,即{t-t_1,…,t-t_N}。
为与原始自我注意力机制一致,初次得到的实体时序特征矩阵如下(即对式(1)的实例化):
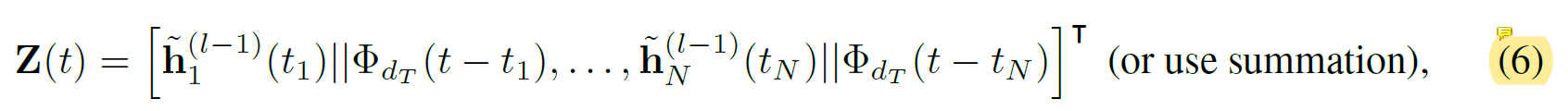
将其代入到三个不同的线性映射以获取’query’、'key’和’value’矩阵如下:
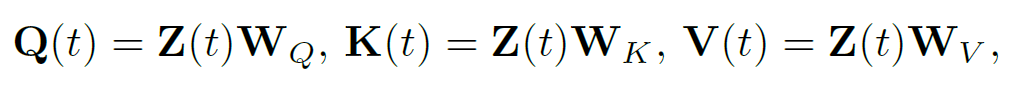
为简化符号,下述讨论将中间输出对目标时间t的依赖关系视为隐式的。
式(2)中softmax函数输出的注意力权重{α_ij}^N,解释了节点i如何参与到节点j的特征中,有:
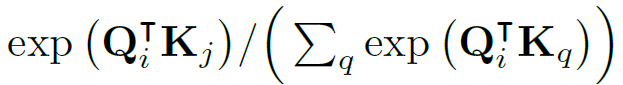
对任意节点vi的隐藏表征,都由线性结合给出:
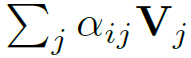
从而将上述点积自我注意力输出按行加和,作为隐藏邻居表征,即:
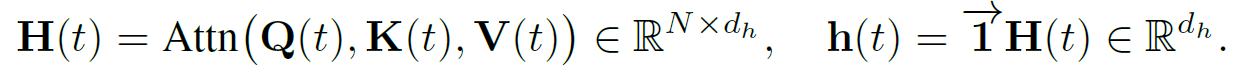
文章将邻居表征与目标节点特征向量z_0相结合,并送入前向传播神经网络中,来得到特征间的非线性交互如下:
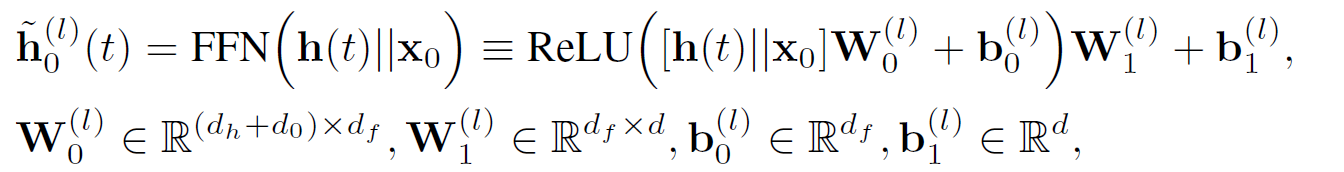
该式即为目标节点在t时间的时序感知节点嵌入的最终表示输出。
有想法认为在GAT算法中使用多端注意力可以提高性能并更加稳定,文章同样证明了TGAT层也能便捷扩展为多端设置。
算法认为点积自我注意力输出来源于k个不同端的总和,即:
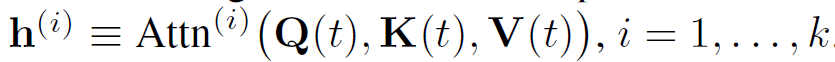
首先将k个邻居表征结合为一个向量,再执行相同流程:
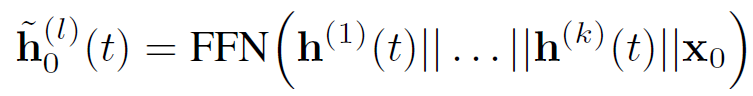
TGAT层聚合了局部单个邻居,通过堆叠L层就聚合了L个邻居,并不严格要求邻域的大小,对TGAT层的图解如下: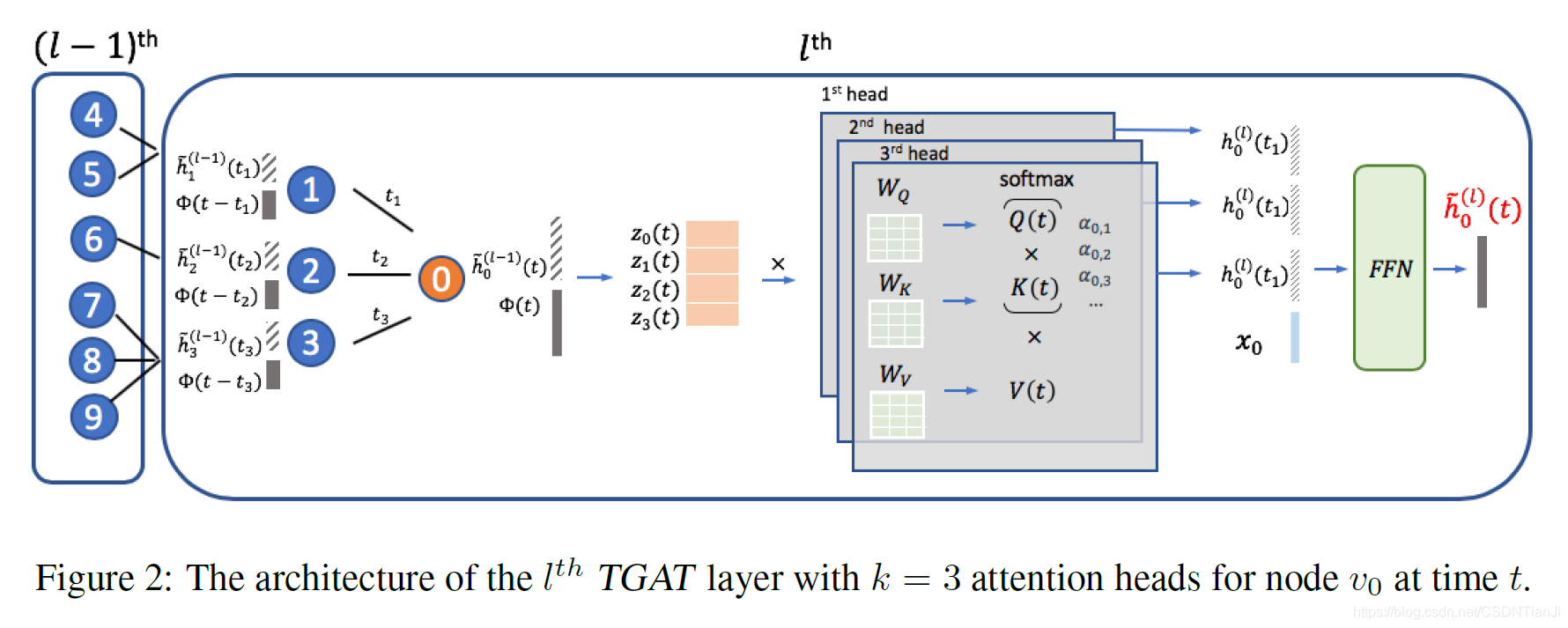
4 Extension to incorporate edge features
文章证明了TGAT层可以扩展为在消息传递过程中运用边的特征,v_i和v_j在时间t的交互可归结为特征向量x_ij(t),为在TAGT聚合中传播边特征,文章对式(6)中的Z(t)进行拓展如下:
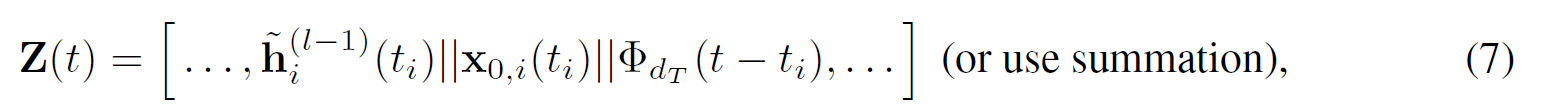
从而边信息就传播到了目标节点的隐藏表征中,并传递给了下一层。
