文章目录
一、评分卡分数计算
评分卡模型用分数衡量逾期率的大小。

易推出p(违约概率)与score成反比
PDO证明:

1.分数的分级
在评级模型中,得到分数后需要对分数进行分级(pooling)操作,将评分的人群划分到有限的几个组别。
划分的方法:
将分数视为连续变量,采用监督室方法例如best-KS或者ChiMerge(卡方分箱)进行有序划分,且一般划分为10组左右。
实际违约率:
将评分卡结果进行分层后,每层对应一个实际违约率(表现期内),

同时,获取过去较长时间内(比如5~10)(观察期)的长期实际违约率(long run PD),以此为基准,得到较准率为
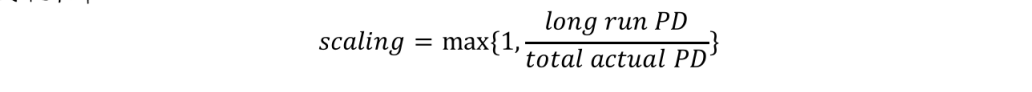
s c a l i n g > = 1 scaling>=1 scaling>=1
预期违约率:
将建模样本的实际违约率乘以较准率,得到预期违约率(预期违约率大于实际违约率)。
a s s i g n e d P D assignedPD assignedPD i i i= a c t u a l P D actualPD actualPD i i i × s c a l i n g ×scaling ×scaling
注:
- 预期违约率在评分卡模型生存周期是固定的,而实际逾期率是变化的
- 在评分卡生存周期内,预期违约率要求不低于实际违约率。当这一条件不满足时,需要做假设检验。
二、模型的验证与监控
1.模型的验证
评分卡模型训练完之后,需要在验证集上进行验证。通常,需要选择跟训练样本所在的日期不同的日期的申请样本作为验证集,称为OOT(out of date test)。这是为了验证模型在时间上的效力跟稳定性。
2.模型的监控
模型在部署并执行后,需要定期对模型的表现进行监控,以保证模型的各项性能不会出现恶化。当某项指标持续恶化时,需要按需对模型进行调整甚至重新开发。模型的监控与验证是一致的,主要包含了对模型稳定性、准确性和排序性的监测。
模型对违约与非违约人群的区分度:
申请评分卡的目的在于尽可能地区分出潜在的逾期人群和非逾期人群。区分人群的手段是看人群所对应评分卡分数的高低。有几个指标常被用作模型对违约与非违约人群的区分度。
- KS值
阈值=30%,模型的KS值越高表明模型的区分能力越强。低于30%,模型就需要调整甚至重新开发。 - Gini Score(基尼指数)
Gini Score是衡量好坏两批人群分数分布的差异性。Gini指数越小,表示模型的区分能力越强。

- Divergence Score(多样性指数)
Divergence Score越大,表明模型区分能力越强。基于全部样本计算,跟分组没有关系。
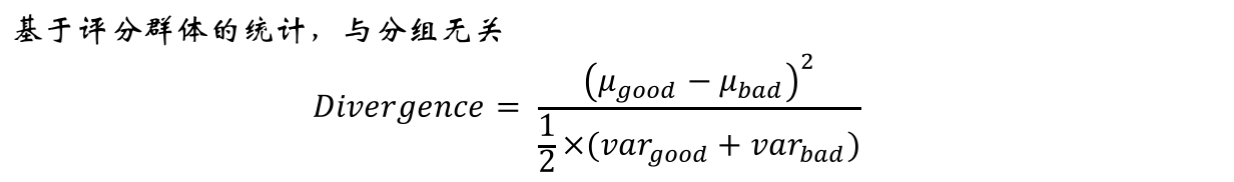
模型准确度:
评分模型通过分数的高低来判断申请者资质的好坏,意味着表现期内逾期人群的分数需要集中在低分段,非逾期人群的分数需要集中在高分段,形成一个“有序”的结果。
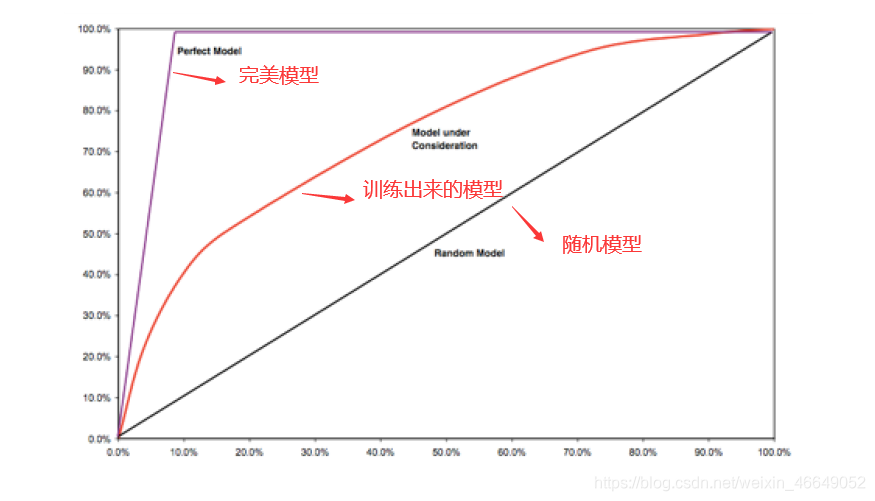
- AR
坏样本累计速度相对于全体样本累计速度的差异。
训练模型相交于随机模型的面积 / 完美模型相交于随机模型的面积 = AR
AR越近于1,模型准确度高
- Kendals Tau
实际逾期率与分数的单调性,即分数越高,实际逾期率越低。
Kendals Tau用来衡量实际逾期率与分数单调性的程度。如果严格单调递减,则Kendals Tau=1;如果单调性方向完全相反,则Kendals Tau=-1;

模型的稳定性
评分卡结果,要求在人群分布不变的情况下保持一定的稳定性。可以用PSI来衡量评分分布的波动:
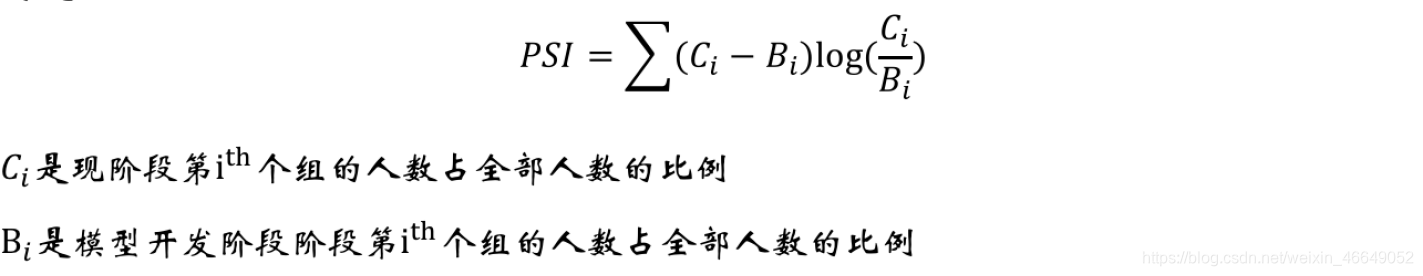
PSI越小,模型的性能越稳定。
注:
- 该指标同时依赖于分数的划分方式
- 当PSI超过阈值(通常是25%)时,表明人群分布发生变化,或者评分稳定性减弱,需要重新评估模型的有效性。
预期违约率的保守性
从风险评估的角度,预期违约率需要比实际违约率高一些,称为保守估计。在监控工作中,当发现分组后第 i i i组的预期违约率低于实际违约率时,要做二项检验。

三、评分卡的其他细节
基于逻辑回归的评分卡模型在完成了开发、验证和审计后,可以进入到部署阶段。不同的使用场景,应该选用不同的部署方式—实时计算与非实时计算。
1.实时计算
实时计算用于线上申请行为,且模型部分依赖三方数据。当申请信息传入到部署模型的服务器时,服务器会从后台数据库里实时查询相关信息(包括调用第三方数据),将数据转换成特征,完成分箱操作和WOE编码,代入到模型。
- 优点:准确度高
- 缺点:变量计算不宜涵盖太长的时间切片,且本机构、第三方数据源接口不能有延时。
2.非实时计算
非实时计算用于线下申请行为。当申请信息传入到部署模型的服务器时,服务器会根据传入数据计算分数。
- 优点:
服务器并发压力小,可人工干预,特征跨度不受限制 - 缺点:
准确度较差,不能抓住突发事件
3.拒绝推断
评分卡模型在开发过程中,选取的数据是历史申请准入后,有实际表现的数据。而在使用时,被准入的客户可以观测到实际表现,被拒绝的客户则无法推断。换言之,我们可以推断评分卡准入客户的好坏情况,却无法推断拒绝客户的情况。针对这一情况,目前尚未有很好的的办法解决这一问题,一般可以借鉴:
- 在审核阶段,随机抽取少量低分段人群给予准入,以此来推断评分卡在低分段人群的表现。
代价:会有违约损失 - 跟踪被拒绝客户在其他平台上的表现
代价:跟踪成本极高
四、申请评分卡的使用
业务人员、风控人员根据评分卡的结果,对于申请进件准入或者拒绝。一般有两条原则进行准入分的设定:
对于非首次使用评分卡的机构
- 当以提高业务量为目标时,在不升高坏账率的前提下,降低现有准入分
- 当以降低违约率为目标时,在保持跟之前的人数一样多的情况下,提高准入分
对于首次使用评分卡的机构
- 领导决定通过率
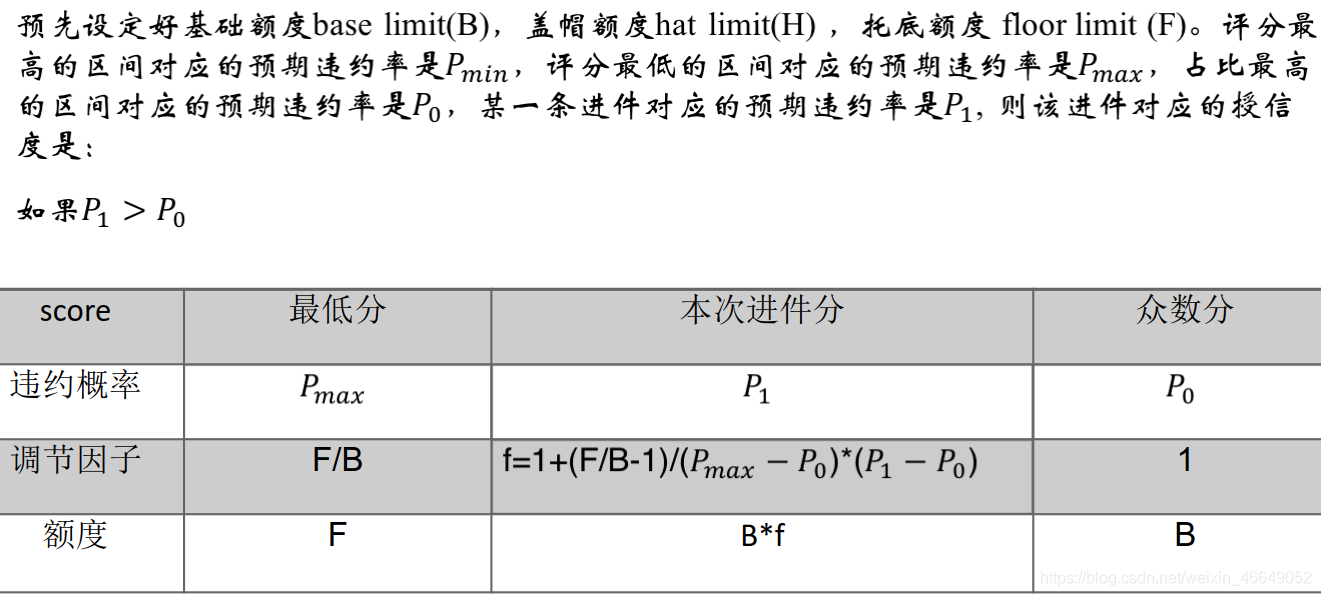
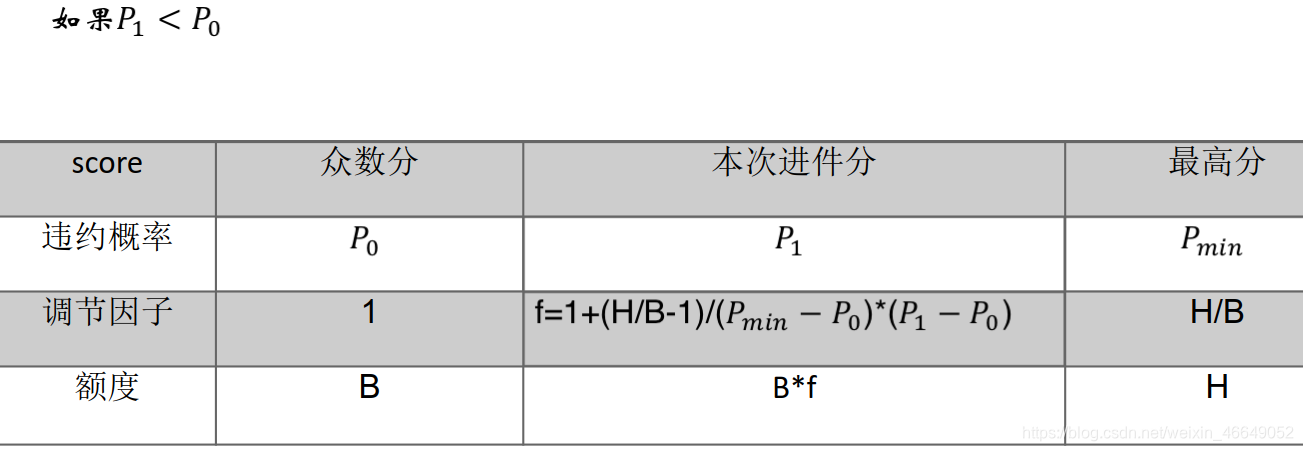
1.授信额度
2.利率定价
