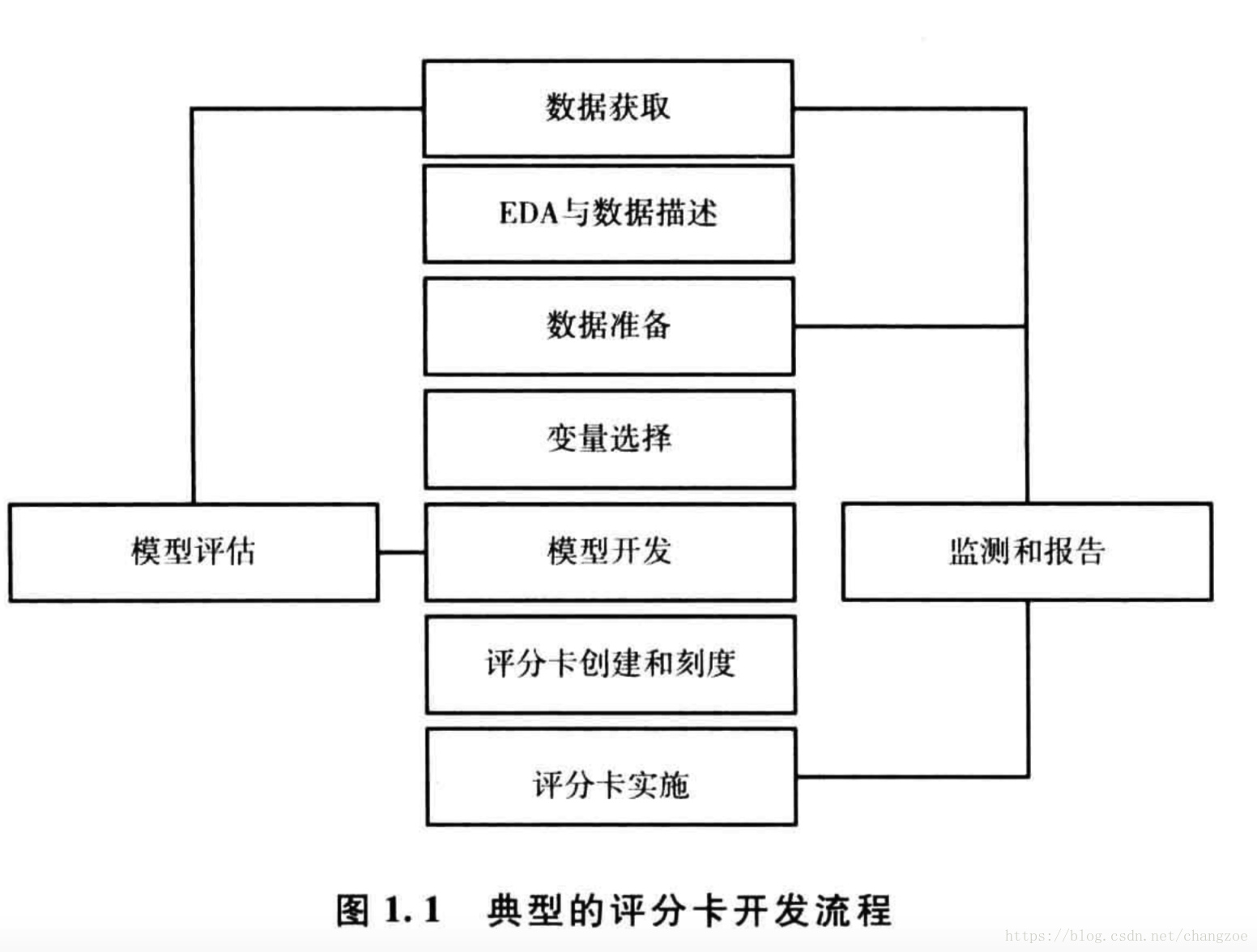
评分卡模型流程
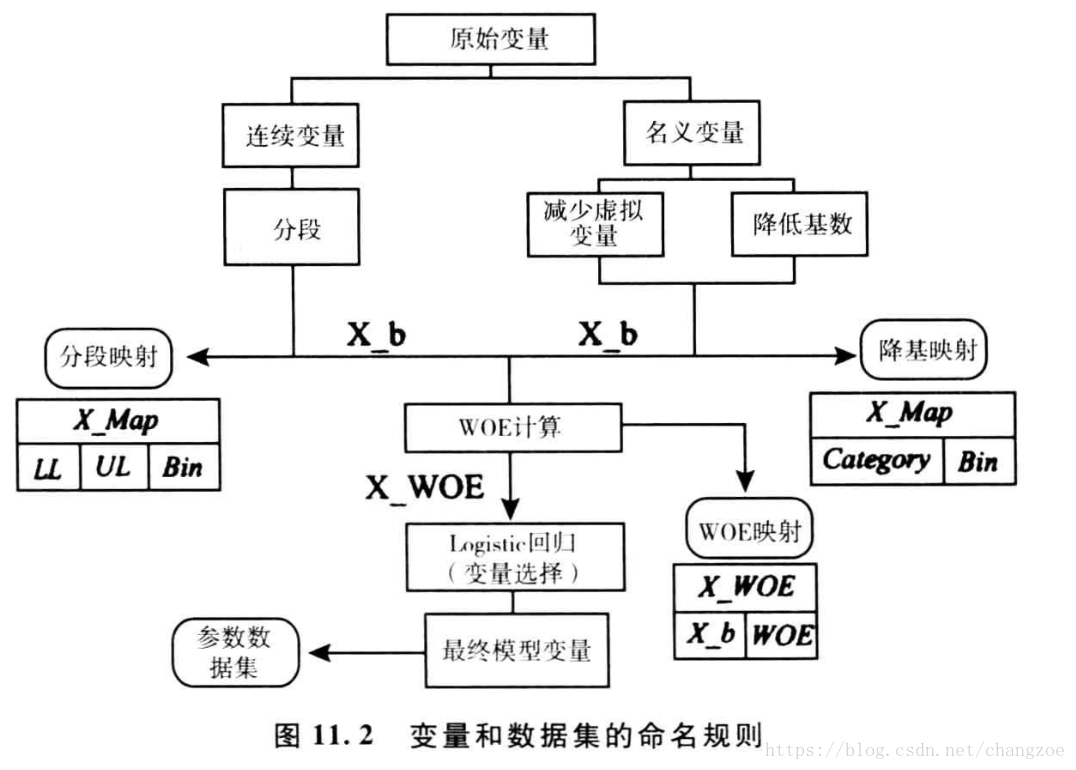
变量分群/分箱
通常是为了让变量的预测力最强
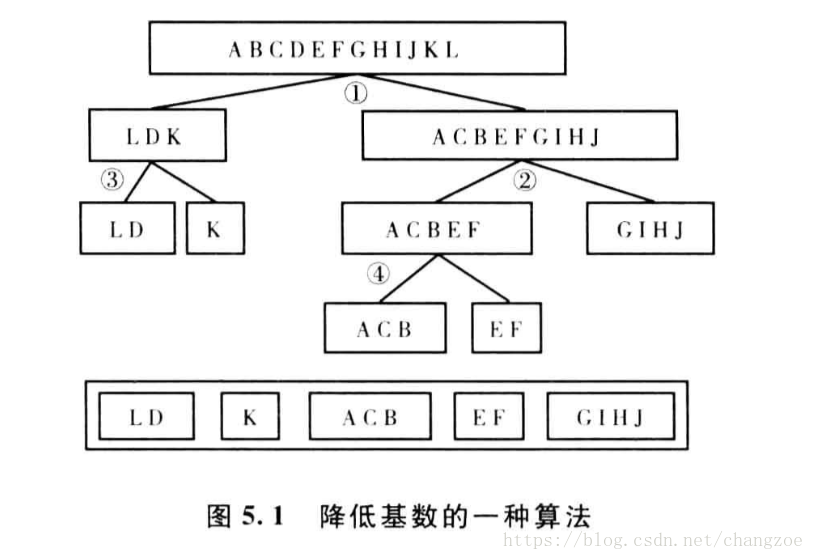
名义变量降低基数


类似决策树的一种算法

连续变量的分箱
在评分卡建模中,变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。要将logistic模型转换为标准评分卡的形式,这一环节是必须完成的。信用评分卡开发中一般有常用的等距分段、等深分段、最优分段。
其中等距分段(Equval length intervals)是指分段的区间是一致的,比如年龄以十年作为一个分段;等深分段(Equal frequency intervals)是先确定分段数量,然后令每个分段中数据数量大致相等;最优分段(Optimal Binning)又叫监督离散化(supervised discretizaion),使用递归划分(Recursive Partitioning)将连续变量分为分段,背后是一种基于条件推断查找较佳分组的算法(Conditional Inference Tree)。
抽样和权重计算
随机抽样
均衡抽样
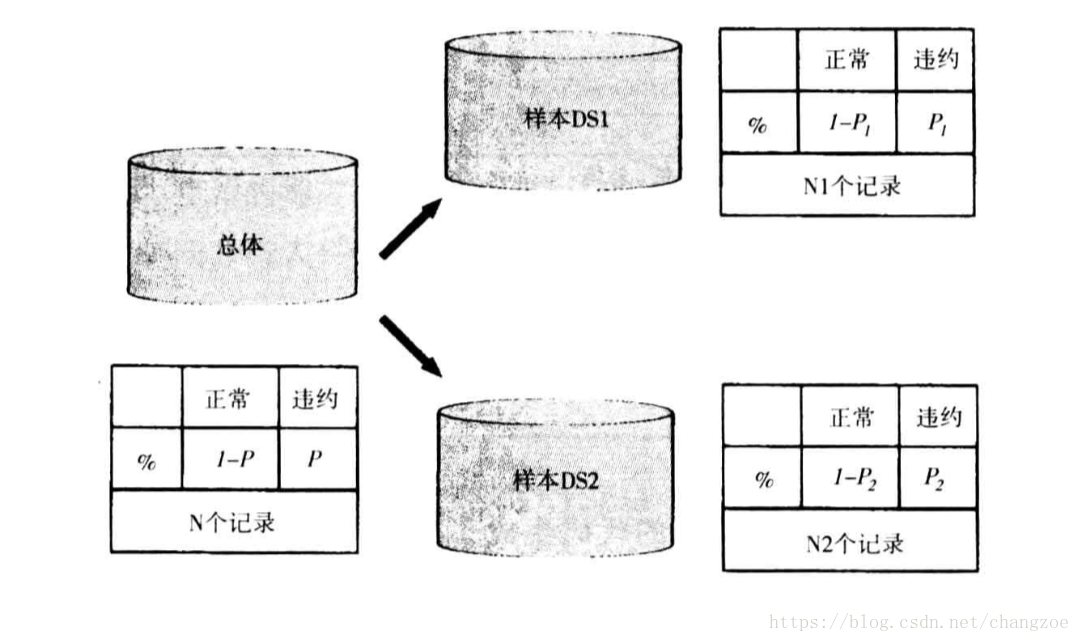

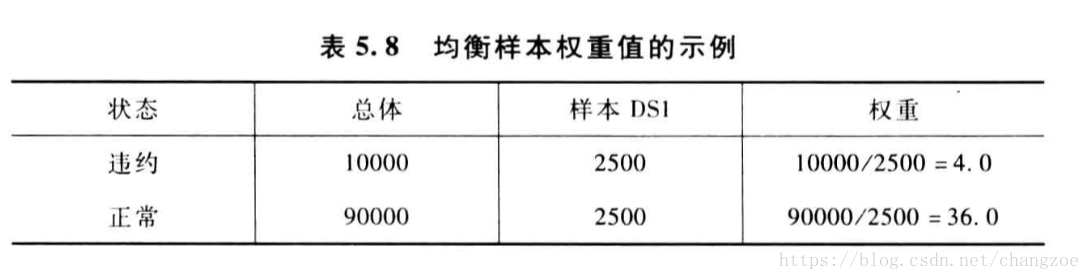
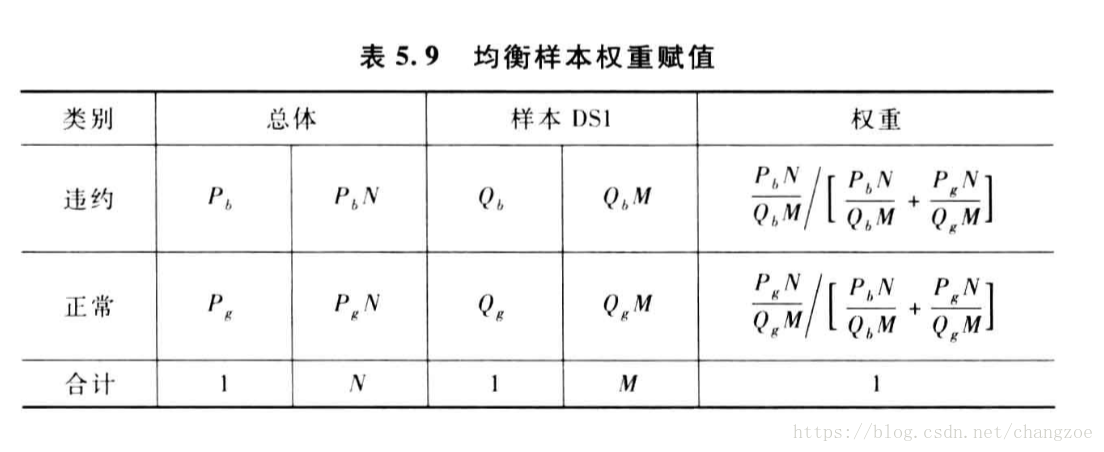

- 分层抽样
logistic回归
- 基本公式
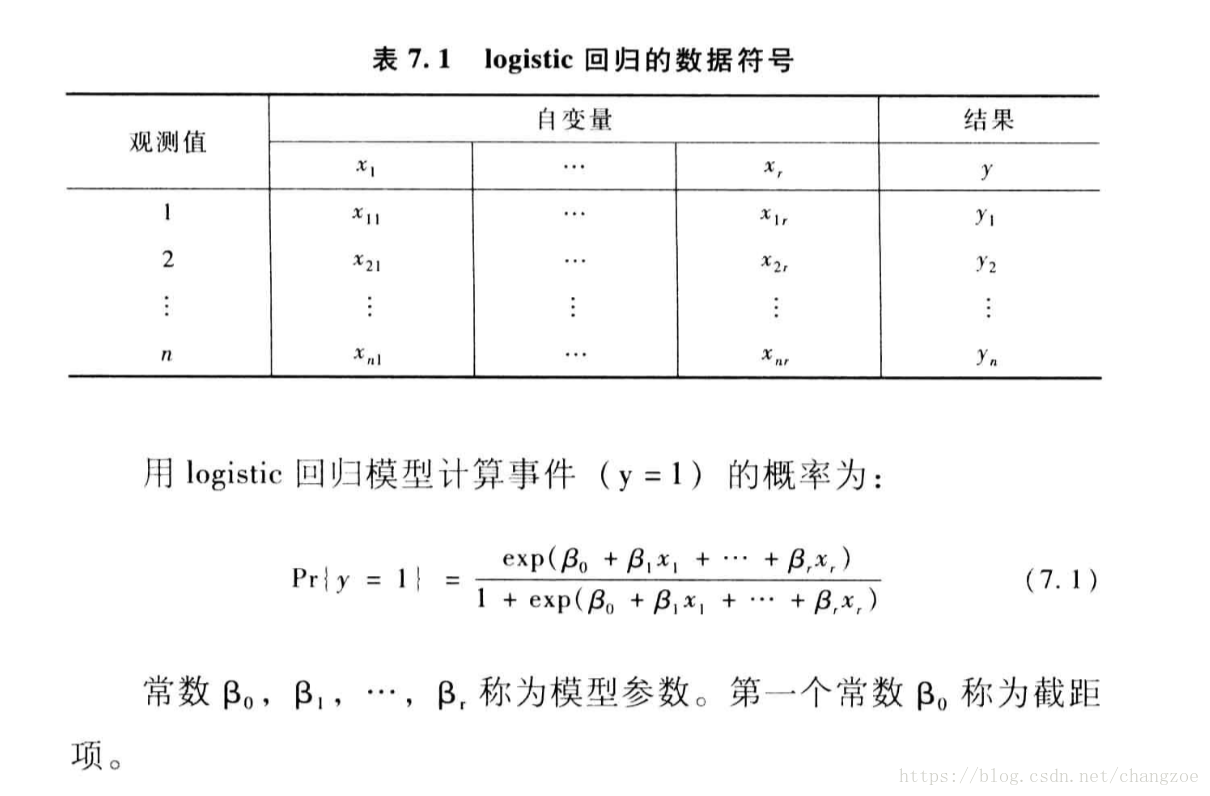

将y=1的概率记为p

- 似然方程拟合回归模型




信息矩阵



模型的方差和协方差
: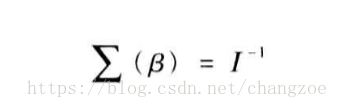
标准误
: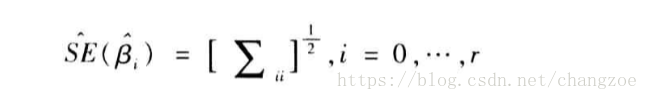
沃尔德卡方统计量:

置信区间

模型拟合的统计量
似然函数值的统计量,评估自变量引入模型的效应及aic,sc,r
hosmer-lemeshow检验:
全局零假设检验
似然比统计量
分数统计量
沃尔德统计量能









关于概率比解读
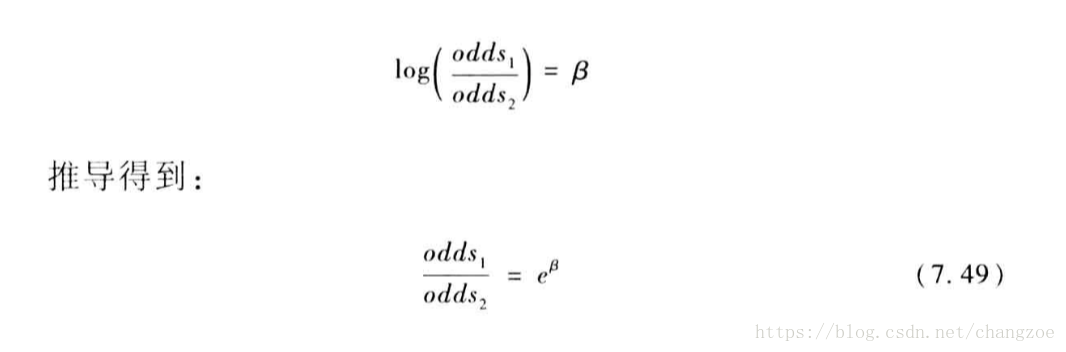

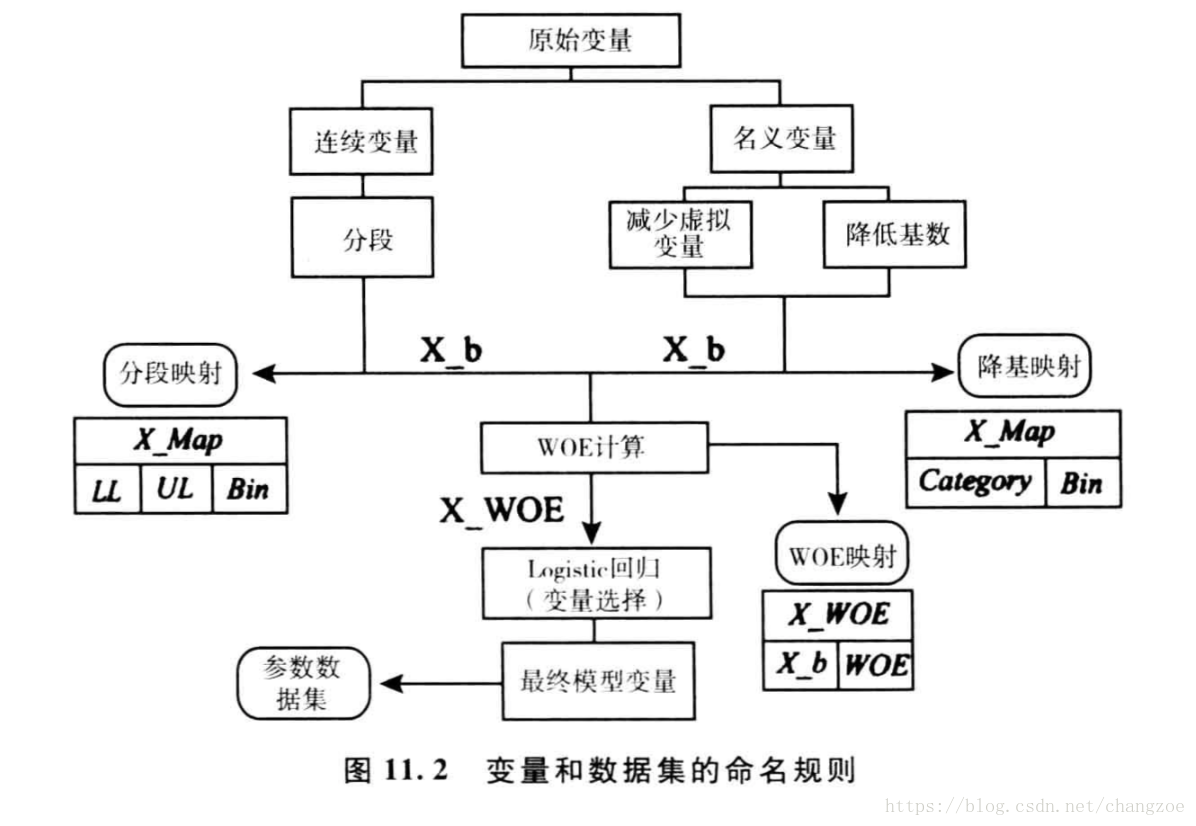
证据权重WOE
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
WOE()=ln[(违约/总违约)/(正常/总正常)]。
用WOE(x)替换变量x,
如果一个已经经过WOE转换的自变量对logistic回归模型进行拟合,则该变量对应的模型参数正好是1.0
证据权重和标准评分卡
名义变量:

连续变量的WOE:
将变量分箱

若WOE值和分段好的序量表之间的线性关系或者单调关系不存在,有两种可能的解释:

变量选择的方法
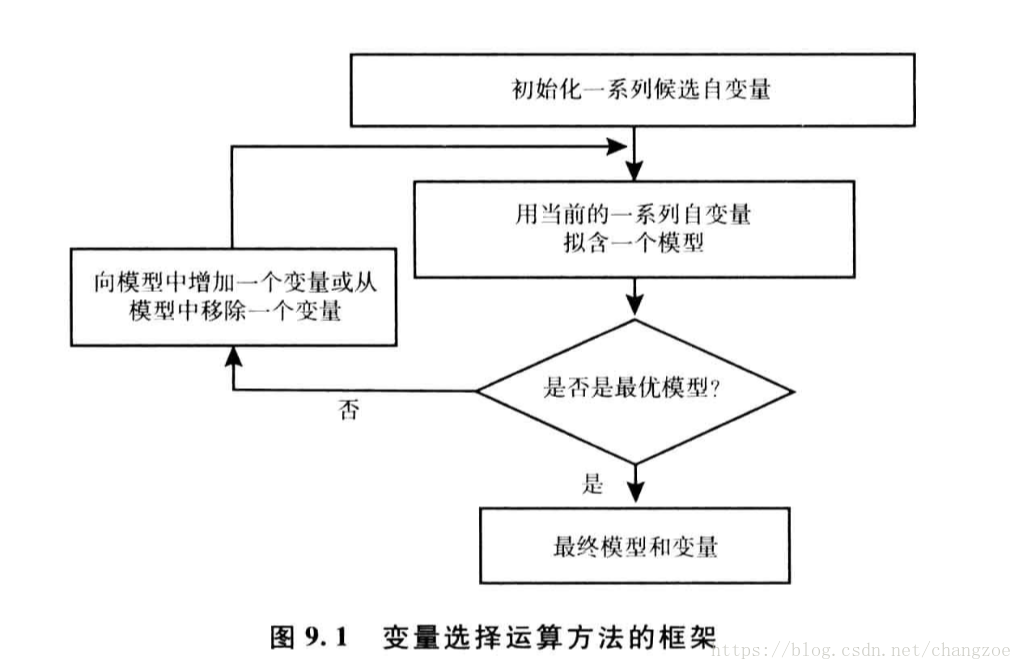
- 使用所有变量 selection=none 将所有变量啊如模型,常用与初始探索性模型拟合
- 正向选择 selection=forward 从几句相对模型拟合,从没有纳入模型的变量选择卡方统计量最大,符合条件的变量,进入的变量不会被移除
- 逆向选择 selection=backward 移除wa l d卡方统计量的p值最大的变量
- 逐步选择


sas参数:

逐步变量选择
优点:

SLE = p-值 SLS= p-值
分别设定允许变量进入和保留在模型中的显著性水平

强制变量进入模型

控制变量的优先级顺序

模型评估
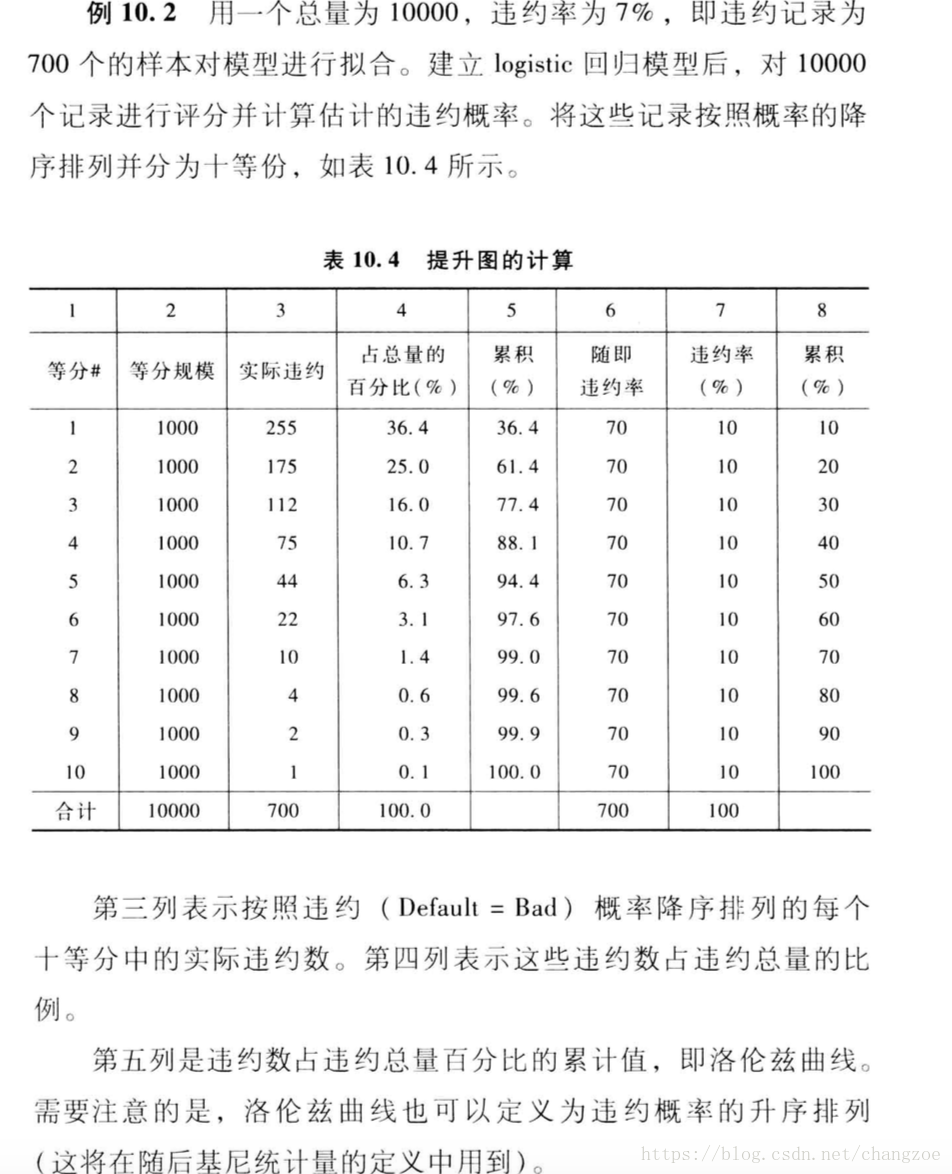
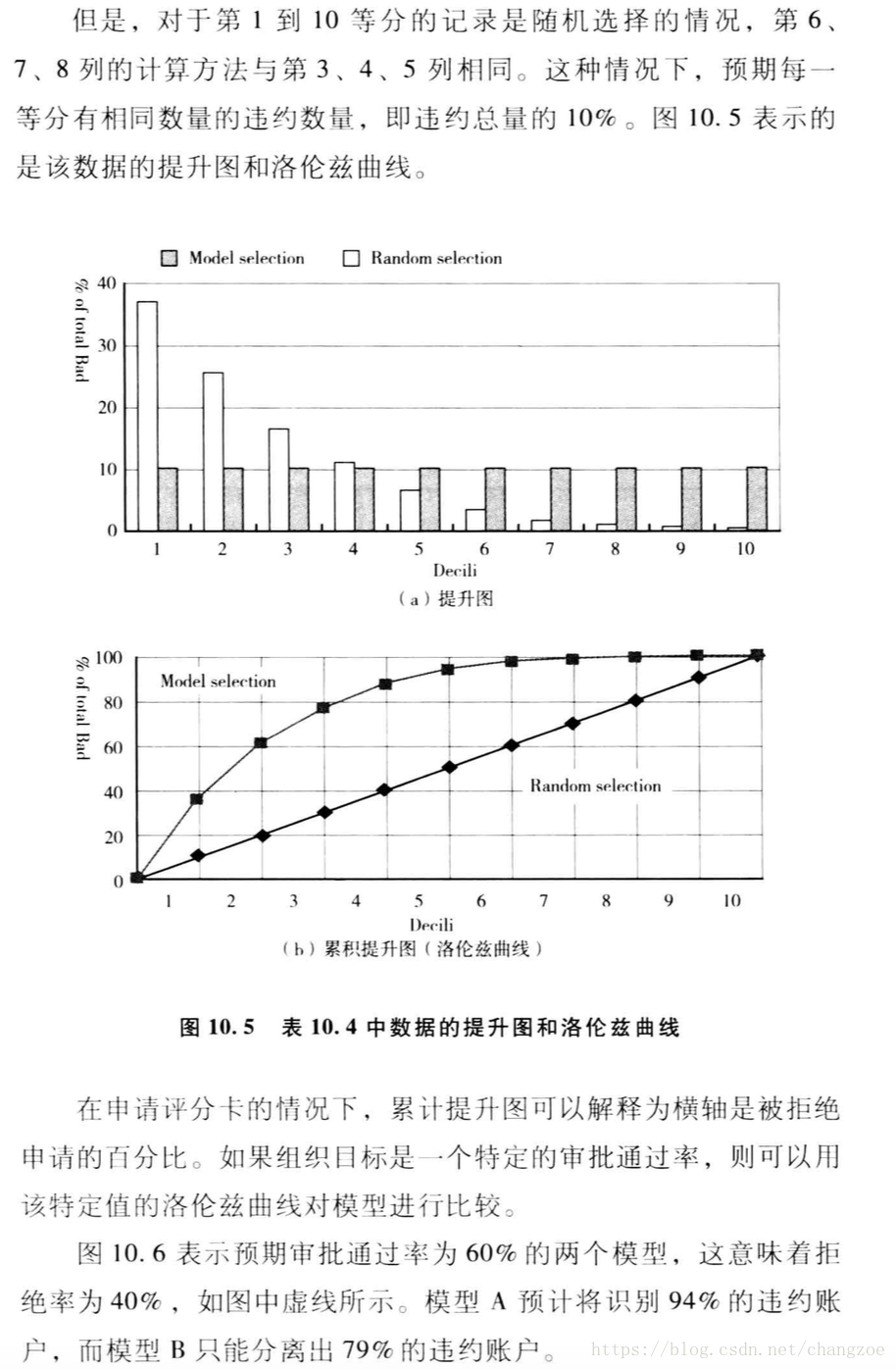
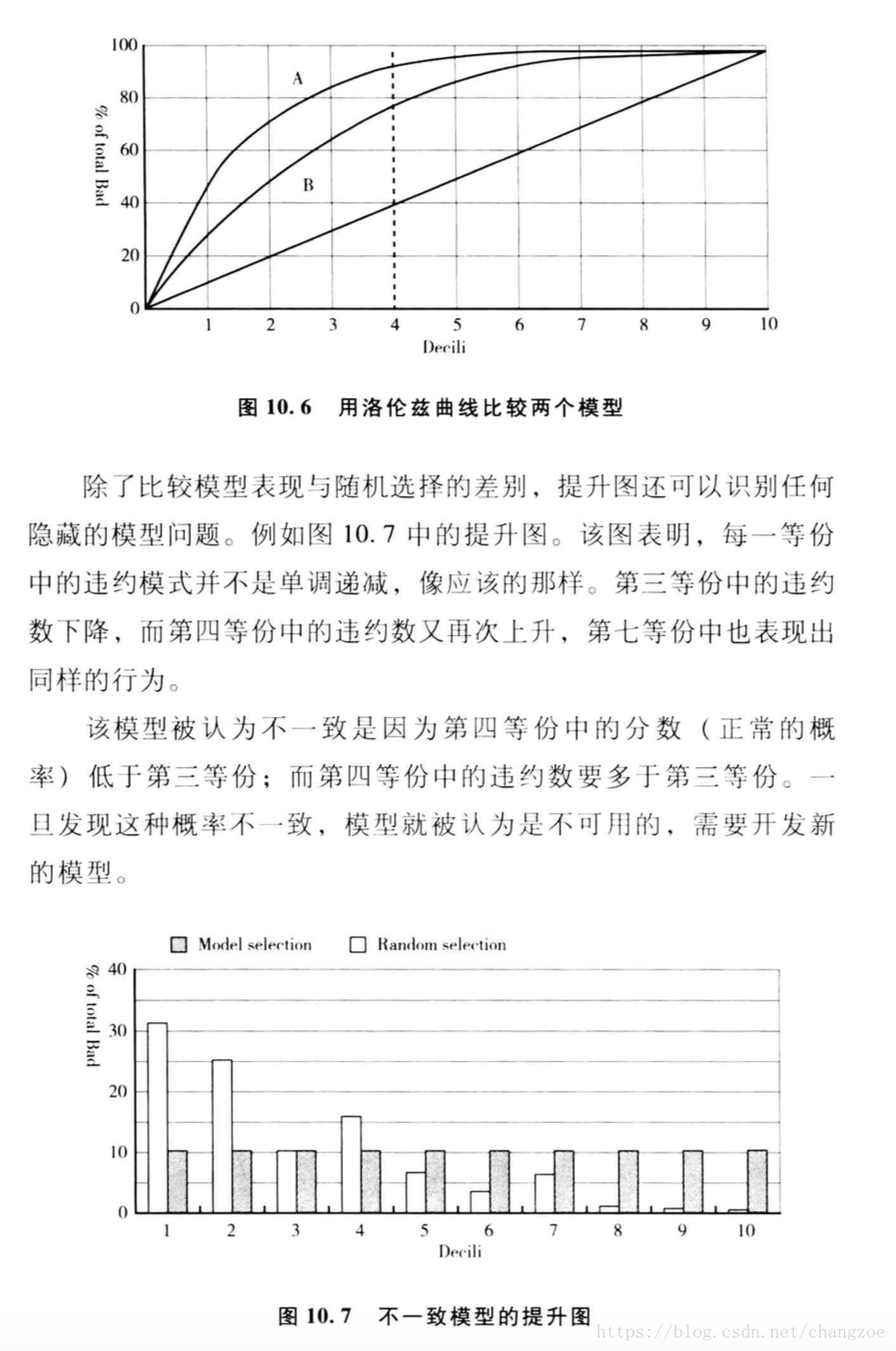
提升图和洛伦兹曲线
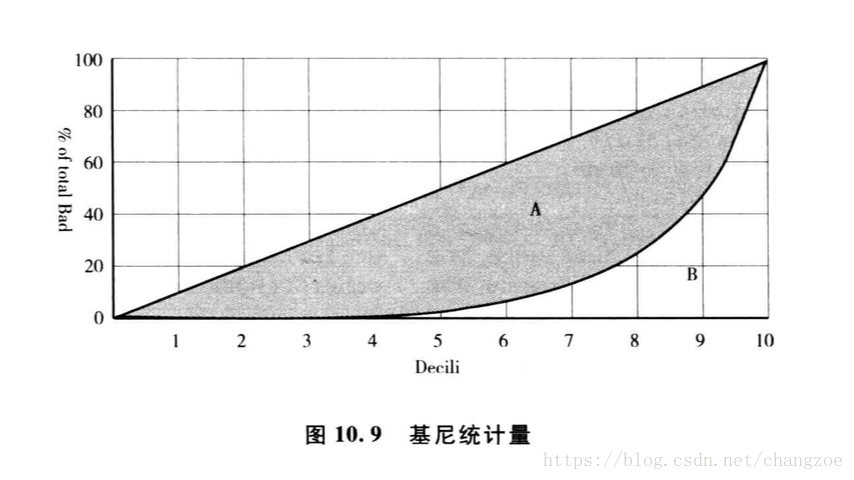
基尼系数

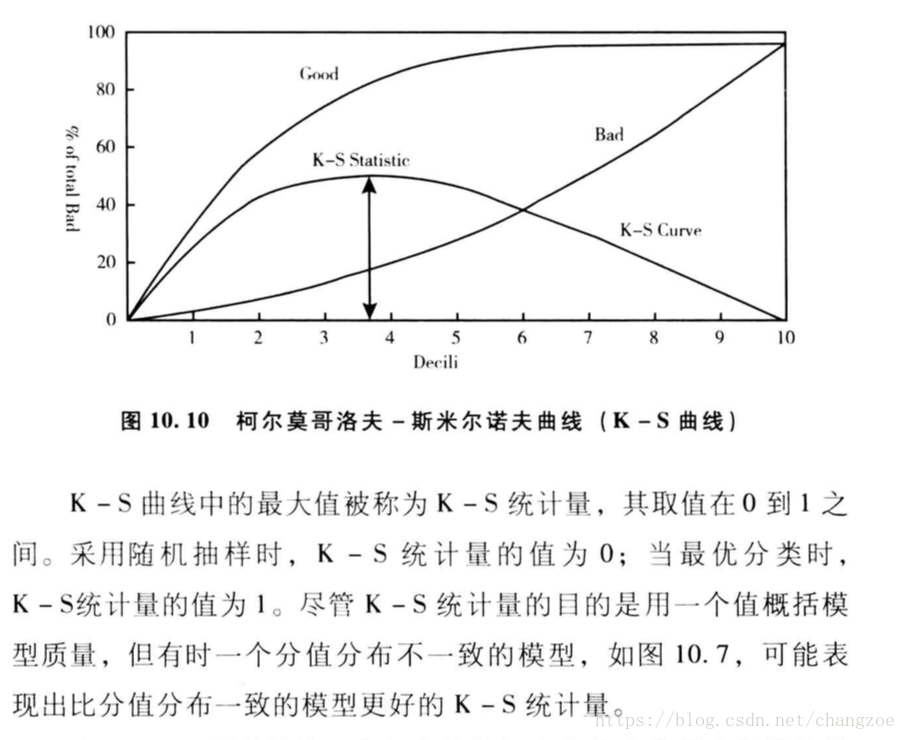
KS曲线
将总体10等分按违约概率降序排列,计算每一份违约与正常的百分比的累积分布,绘制两者的差异
ROC曲线

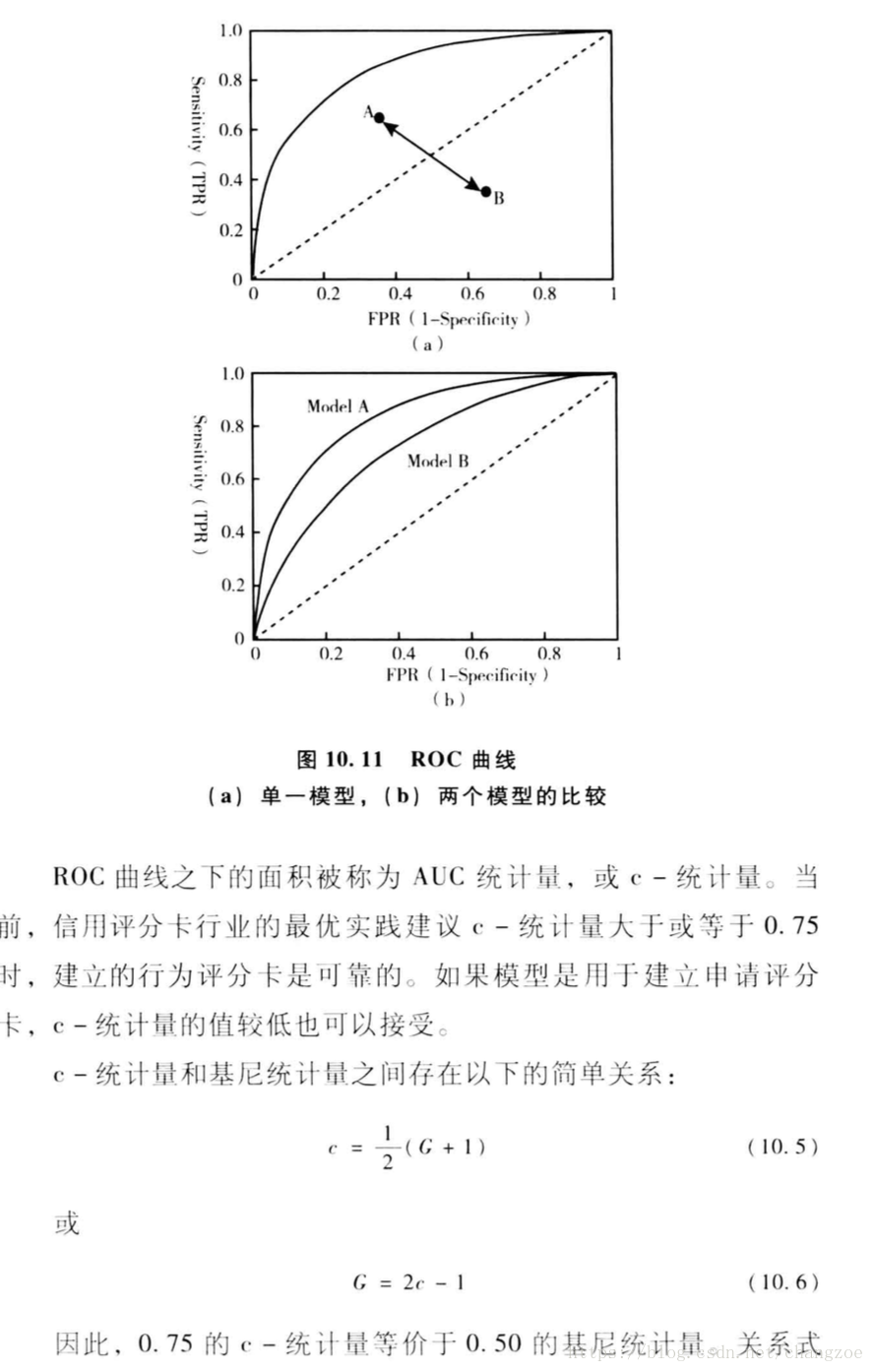
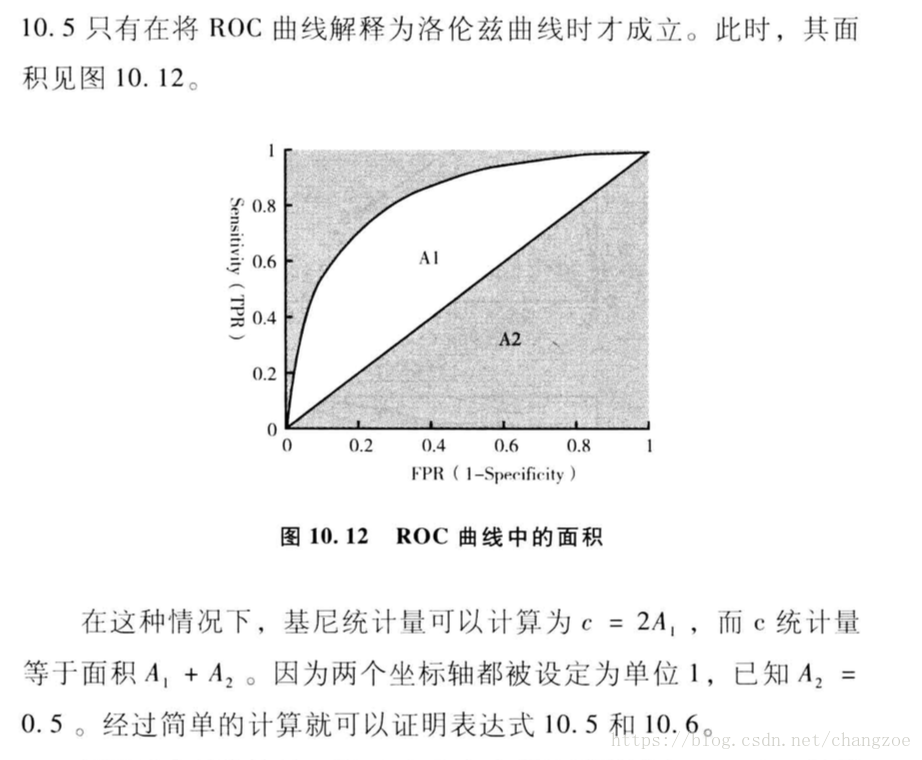
模型整体评估

评分卡刻度与实施
评分卡的刻度
估计违约的概率为p,估计得正常的概率即为1-p,这两个事件互斥且互为补集
违约与正常的比率:
则p为:
评分卡设定的分值刻度可以通过将分值标示为比率对数的线性表达式来定义。:
score = A - Blog(odds)
logistic 计算比率如下:
常数A和B需要两个假设:
- 在某个特定的比率设定特定的预期分值
- 制定比率翻番的分数(pdo)
设定比率为
的特定嗲的分值为
,然后比率为
的点的分值为
,则:
解为:
A通常为称为补偿,B刻度
实施

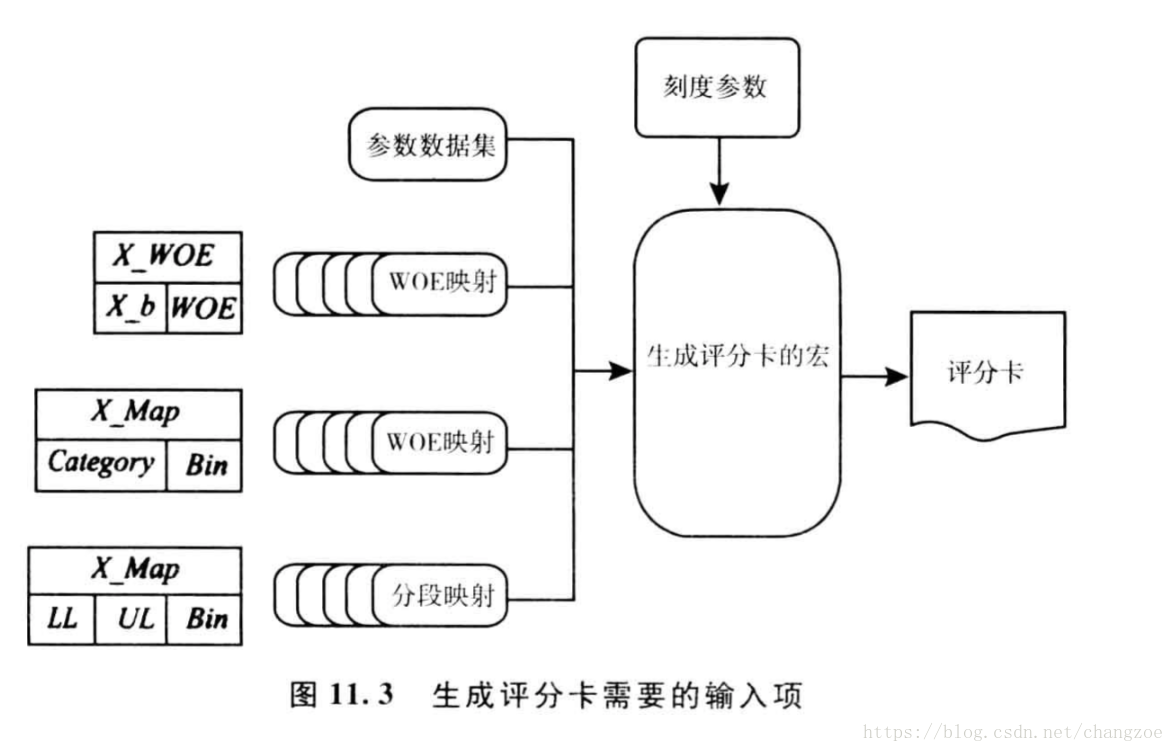
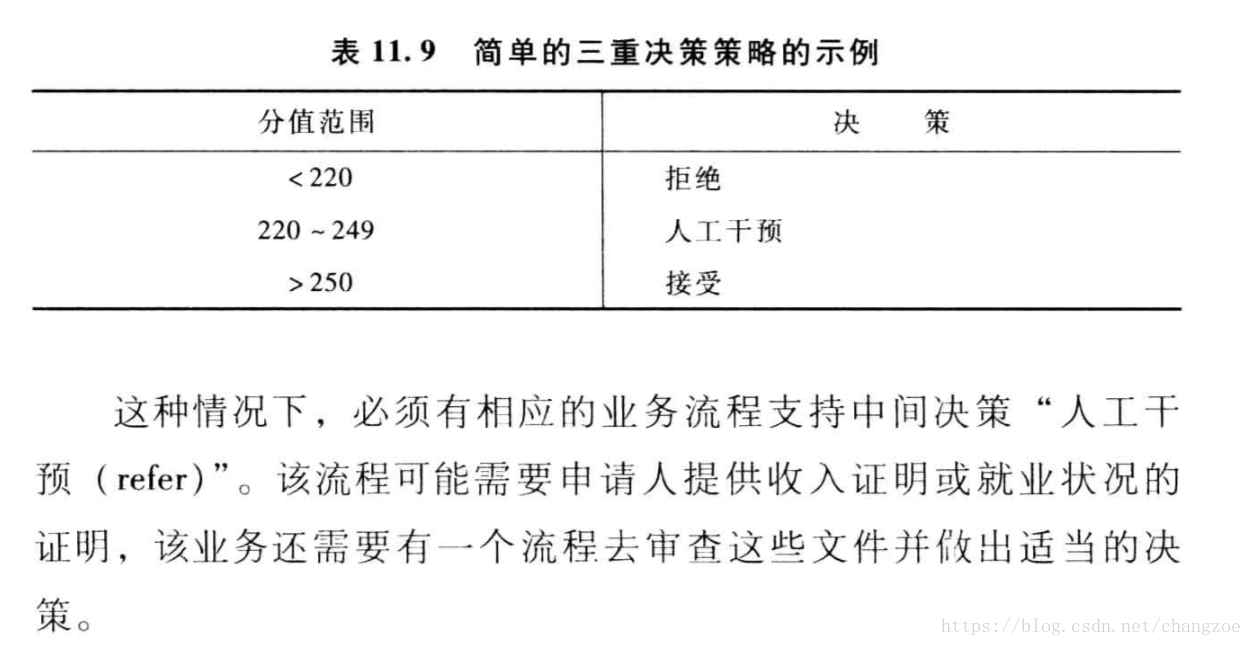
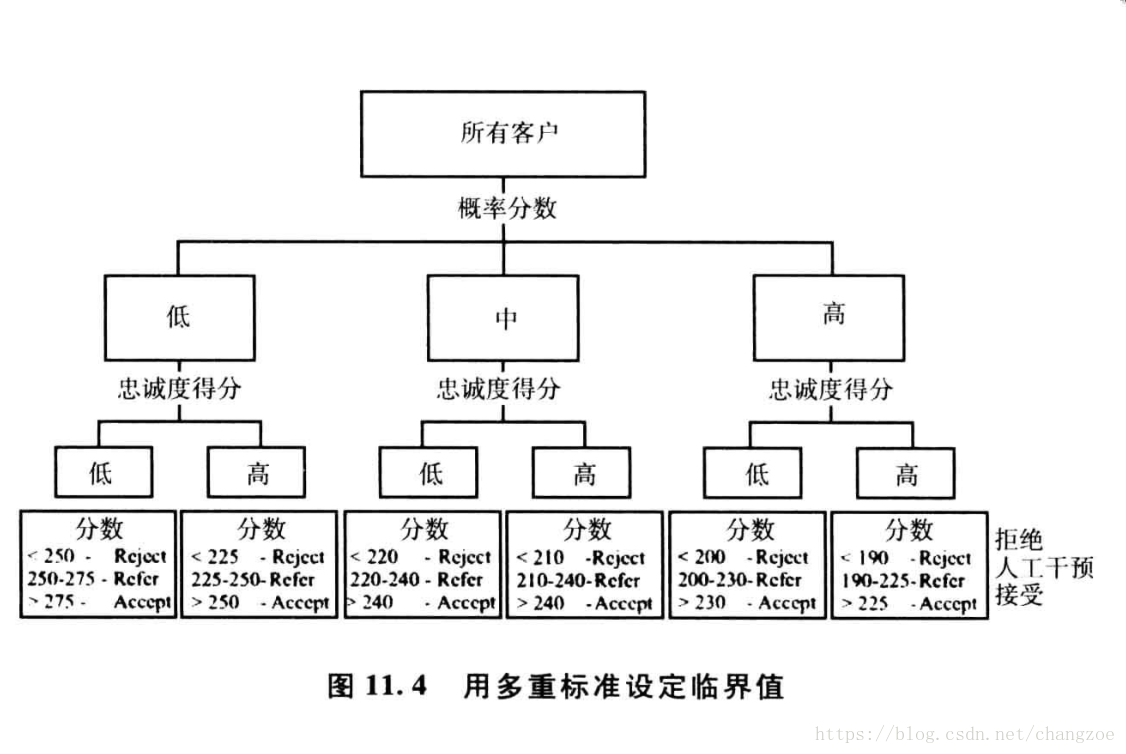
设定临界值水平

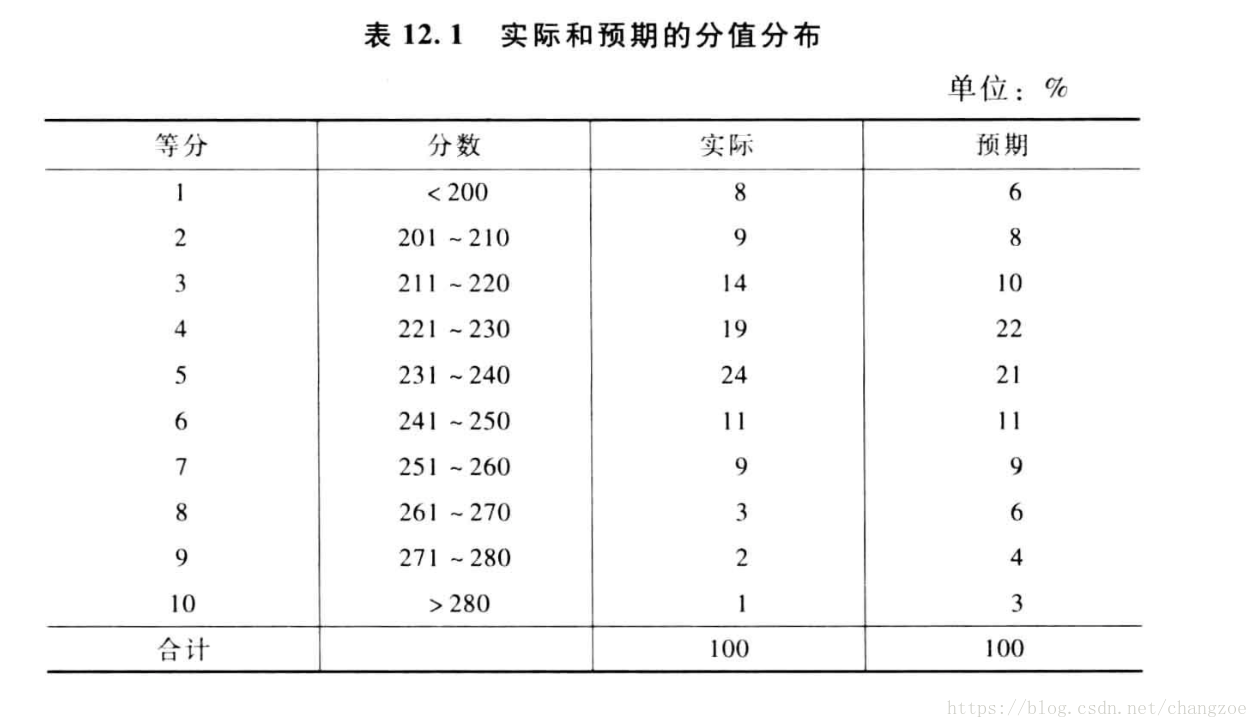
监测报告
稳定性报告

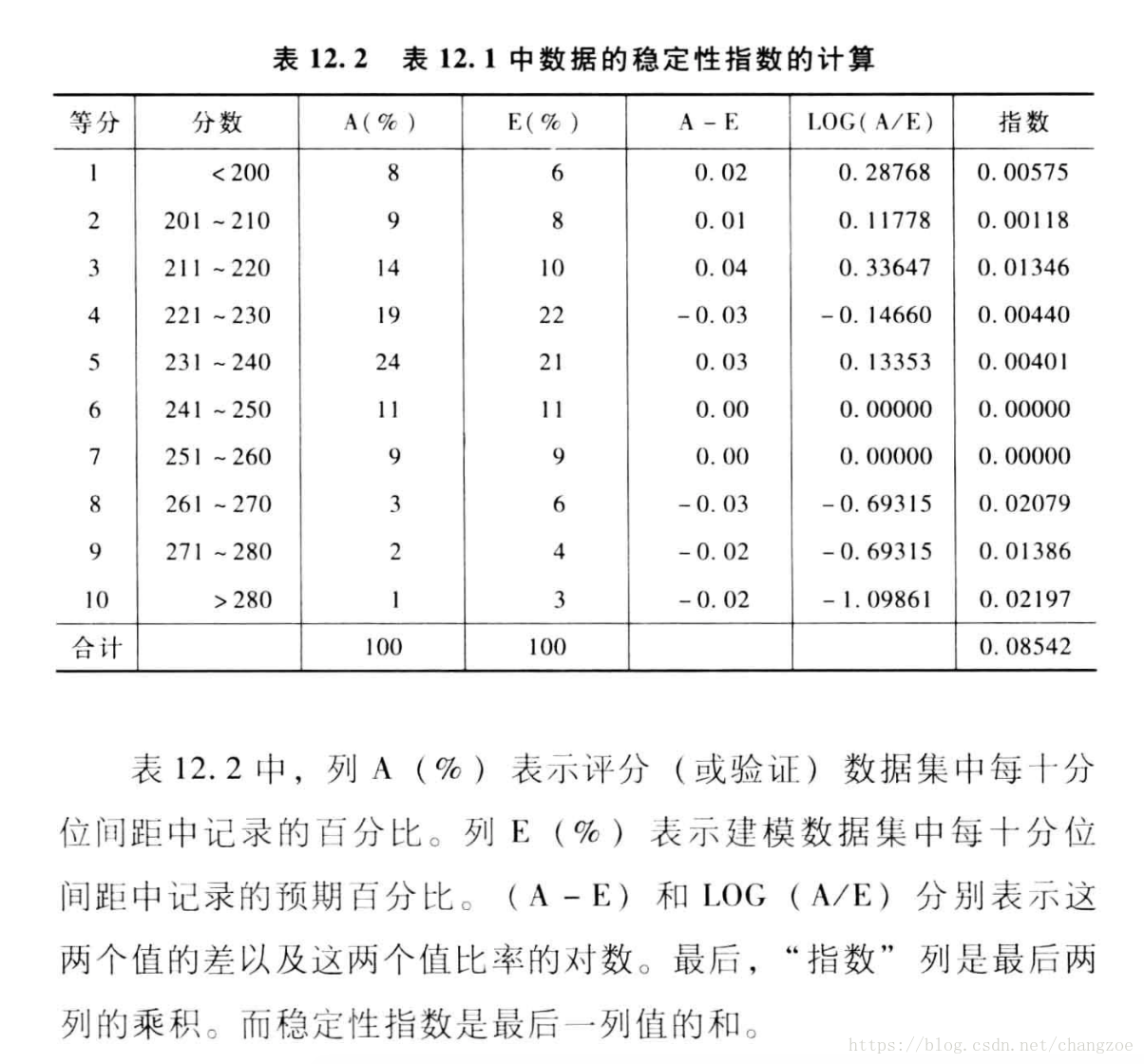
总体稳定性指数I:
与信息值相同



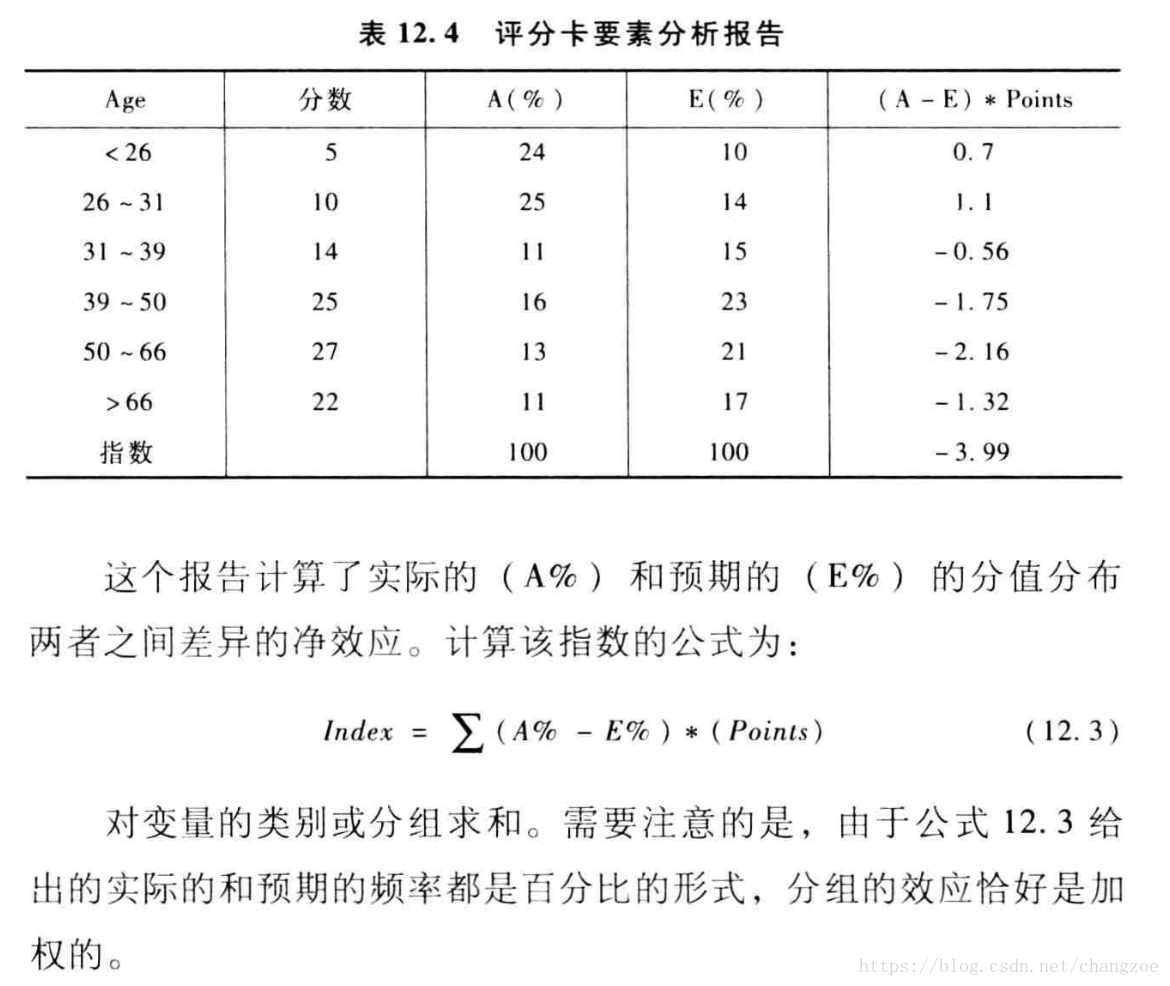
评分卡要素分析
评估自变量分布的变化对最终评分结果的分析
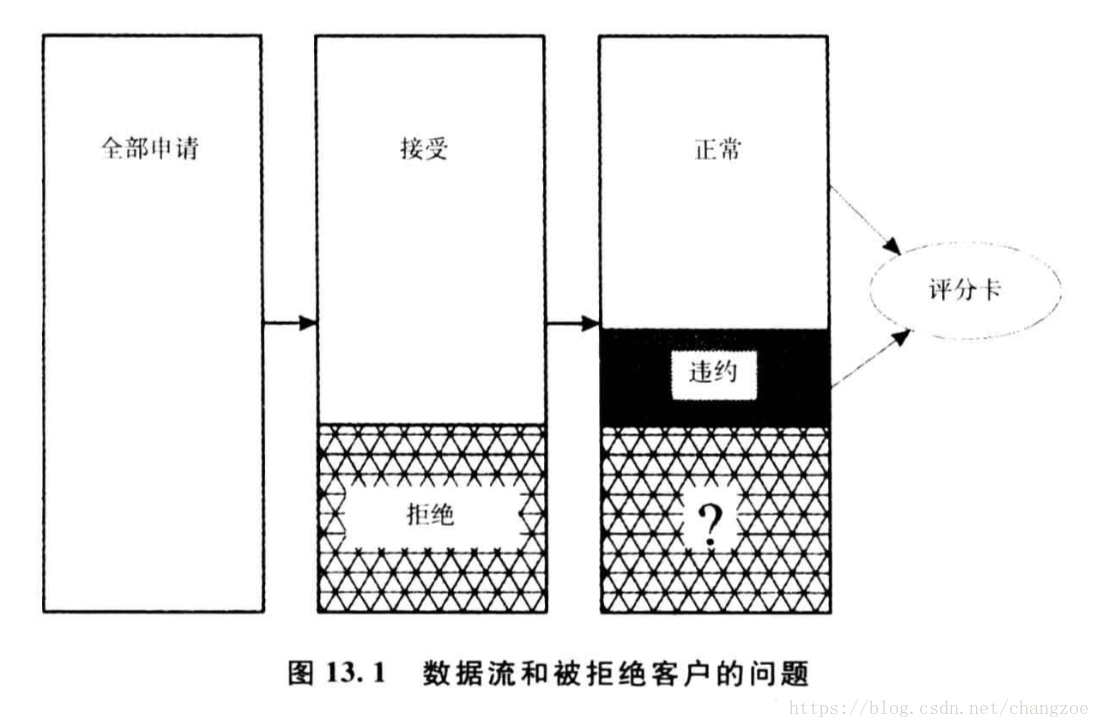
拒绝演绎
仅用于申请评分卡
建立评分卡时对被拒绝账户的状态进行演绎并纳入评分卡开发数据集
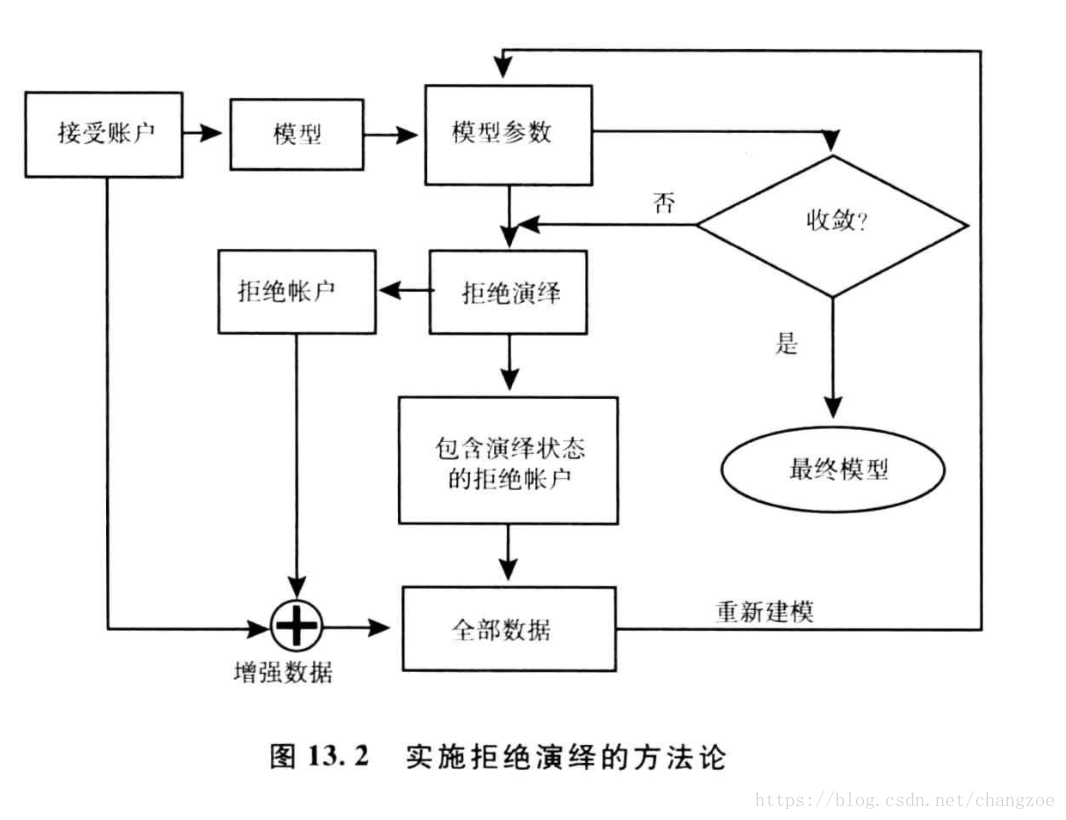
方法

简单赋值法
- 忽略被拒绝申请
- 赋予所有被拒绝申请违约状态
- 比例赋值:随机赋予被拒绝账户和违约状态
强化法
- 简单强化:用数据中接受部分开发的模型对被拒绝账户进行评分,第分值的拒绝账户,低于预先约定的临界值,将被赋予违约状态,而剩余的被拒绝账户则被赋予正常状态
建议:选择的临界值应该使被拒绝账户的坏账率是接受账户的2-5倍
模糊强化
打包法
引用:
信用卡评分