评分卡项目总结
一、分析目的
信用评分A卡制作,判断用户是否违约。
二、数据处理
这一步不仅涉及列名修改、去重、缺失值、异常值等常规处理,还有WOE分箱处理。
2.1、列名格式规范性处理
修改部分列名,比如数据中的‘NumberOfTime60-89DaysPastDueNotWorse’和‘NumberOfTime30-59DaysPastDueNotWorse’两列。由于一些算法或方法,列名中的某些符号会带来问题甚至报错,例如这里的"-",会在回归公式中被认为是减号,所以换成"_"。
train_data.columns=train_data.columns.map(lambda x:x.replace('-','_'))
2.2、重复数据处理
删除重复行数据。重复数据,容易导致回归系数标准误降低,使得对应p值减小。
train_data.drop_duplicates(inplace=True)
2.3、缺失值处理
2.3.1、查看缺失值分布情况
我们使用missingno库的matrix()方法查看各特征缺失值情况。
import missingno as msno
msno.matrix(train_data)
plt.show()
 从上图看,‘MonthlyIncome’和‘NumberOfDependents’两列存在缺失值,前者占比最多大于80%,后者占比较少。
从上图看,‘MonthlyIncome’和‘NumberOfDependents’两列存在缺失值,前者占比最多大于80%,后者占比较少。
2.3.2、缺失值处理逻辑
1、常规的缺失值处理方法是占比超过80%缺失值数据直接删除。对于信用评分卡来说,由于所有变量都需要分箱,故这里缺失值作为单独的箱子即可。
2、对于最后一列‘NumberOfDependents’,缺失值占比只有2.56%,作为单独的箱子信息不够,故做单一值填补,这列表示家庭人口数,有右偏的倾向,且属于计数的数据,故使用中位数填补。
2.3.2、单一值替换缺失值
将最后一列‘NumberOfDependents’的缺失值替换成中位数。
NOD_median=train_data['NumberOfDependents'].median()
train_data['NumberOfDependents'].fillna(NOD_median,inplace=True)
2.4、异常值处理
异常值常见的处理方法有删除所在的行、替换成缺失值(与缺失值一起处理)或盖帽法处理。结合业务逻辑和算法需求判断是否需要处理异常值以及如何处理,一般情况下盖帽法即可,即将极端异常的值改成不那么异常的极值,当然一些算法例如决策树中连续变量的异常值也可以不做处理。我们先定义好盖帽法函数,需要的时候再拿来用。
def block(x,lower=True,upper=True):
# x是输入的Series对象,lower表示是否替换1%分位数,upper表示是否替换99%分位数
ql=x.quantile(0.01)
qu=x.quantile(0.99)
if lower:
out=x.mask(x<ql,ql)
if upper:
out=x.mask(x>qu,qu)
return out
2.4、自定义函数,汇总数据清洗过程
我们先自定义一个函数,封装数据清洗过程,后面新数据预测时可以使用该函数同步数据清洗工作。
def datacleaning(testdata,include_y=False):
testdata.columns=testdata.columns.map(lambda x:x.replace('-','_'))
testdata['NumberOfDependents'].fillna(NOD_median,inplace=True) #新数据的缺失值需要用训练集的填充方式处理
if include_y:
testdata["SeriousDlqin2yrs"]=1-testdata.SeriousDlqin2yrs #好客户用1表示,坏客户用0表示,便于混淆矩阵指标分析提取
return testdata
三、特征选择
首先,我们自定义一个外部文件smob.py,这个文件封装了通过决策树选择特征函数、生成WOE及计算IV值函数、计算模型评估指标函数。
注:所涉及的函数,文章最后完整代码内已详细罗列。
3.1、对每个X生成分箱对象
先用‘RevolvingUtilizationOfUnsecuredLines’特征作说明,其他特征是一样的操作方法。
1、先初始化数据
y='SeriousDlqin2yrs' #初始化一个标签名变量
iv_all=pd.Series() #初始化一个空序列变量,用于存放各特征IV值
2、调用smbin函数求出特征的woe数据及IV值。
RUO=smbin(train_data,y,'RevolvingUtilizationOfUnsecuredLines')
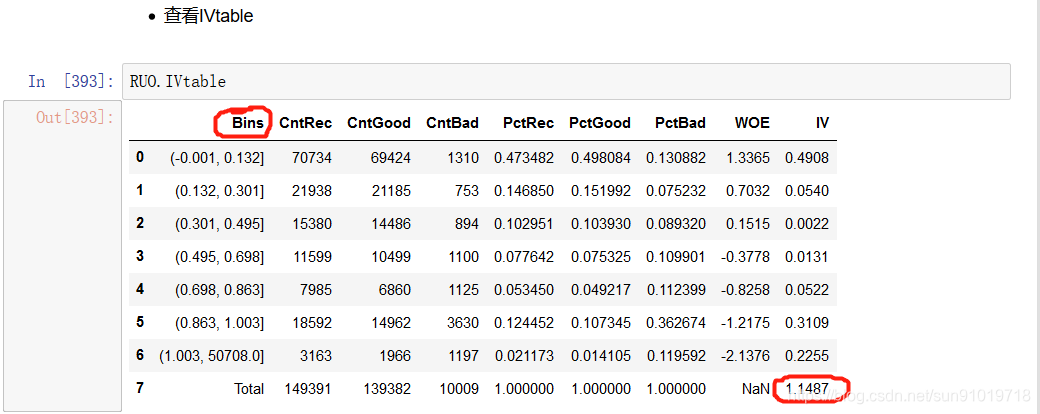
3.2、查看所有特征IV值
IV值是用于筛选重要特征的指标之一。依据IV值删除小于0.02的特征。一般地,IV<0.02,对预测几乎无帮助;0.02≤IV<0.1,具有一定帮助;0.1≤IV<0.3,对预测有较大帮助; IV≥0.3,具有很大帮助。
iv_all.sort_values(ascending=False)
 从结果上看,这些特征多少重要特征。接下来我们初步建模看看效果。
从结果上看,这些特征多少重要特征。接下来我们初步建模看看效果。
3.3、生成WOE数据
分箱原则:分箱数适中,不宜过多过少;各个分箱内记录数合理;分箱应该体现出明显的趋势特性;相邻分箱的差异不宜过大。我们是选择有监督式分箱方式,算法选择的是CART树。
1、初始化列表
之前smbin和smbin_cu得到的对象根据IV值筛选后,放在一个列表中。
x_list = [RUO,age,NO3059,DebtRatio,MonthlyIncome,NOO,NO90,NRE,NO6089,NOD]
2、生成WOE数据
使用smgen函数根据得到的列表生成新数据
data_woe=smgen(train_data,x_list)
data_woe.head()
四、建模
4.1、初步建模
建立逻辑回归模型,拟合数据,查看回归结果。
glmodel=sm.GLM(Y_train,X_train,family=sm.families.Binomial()).fit()
glmodel.summary()
#可以查看系数(coef)、系数标准误(std err)
#P>|z|,就是P检验,小于0.05说明显著,说明变量是重要变量
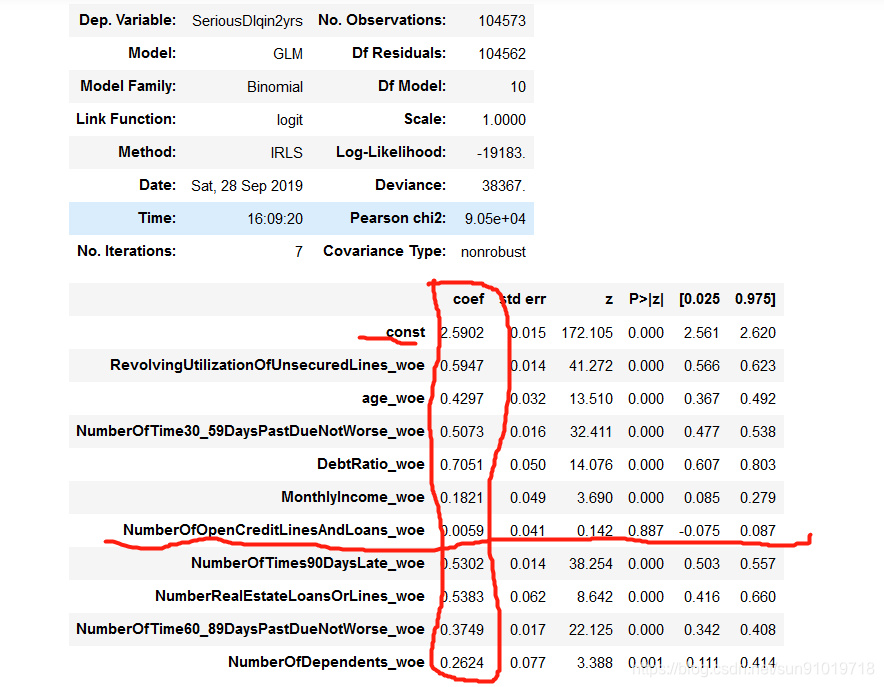
从模型返回的结果看,IV值能帮我们筛选重要特征,但不是准确方法。数据上看起来IV值很高并不一定是重要特征。接下来,我们需要进行假设检验,我们选择P检验(小于0.05,才是重要特征)。我们发现‘NumberOfOpenCreditLinesAndLoans_woe ’特征的P值高于0.05,所以我们选择删除该特征。
4.2、查看共线性
计算每个预测变量的vif值,查看变量间是否存在共线性。VIF值越大,系数标准误会越来越大,置信区间就特别小。VIF在[1,3)之间,变量可以直接用;[3,7)之间,需稍微处理数据才能用;[7,10)之间,数据必须处理才能使用;大于10,出现共线性现象,需改变变量。
vif=[variance_inflation_factor(X_train.iloc[:,1:].values,i
) for i in range(X_train.shape[1]-1)]
print(pd.Series(dict(zip(X_train.columns[1:],vif))))
 从结果上看出,变量间不存在共线现象。接下来制作评分卡。
从结果上看出,变量间不存在共线现象。接下来制作评分卡。
五、生成评分卡
5.1、生成信用评分模型原理
1、对于特定分数,好客户和坏客户有一定的比例关系,即优比(odds),odds=xPctGood/xPctBad。
2、增加一定评分值时优比增加一倍,例如增加45分,odds增加一倍(从50:1到100:1)
3、公式(5.1):Score = Offset + Factor × ln(odds);公式(5.2):Score + pdo = Offset + Factor × ln(2 × odds)
4、此时我们需要用到自定义函数smscale(模型,特征列表,pdo,score,odds)我们先是通过业务提供的分值范围结合上述两个公式来调整pdo,score,odds三个参数的值。
这里业务提高的范围是[300, 843],最终我们获得参数值:pdo=43,score=1151,odds=10。
5.2、计算各分类评分
Logistic逻辑回归得到的回归方程左边 ,代入上一步骤的信用评分公式(5.1)。
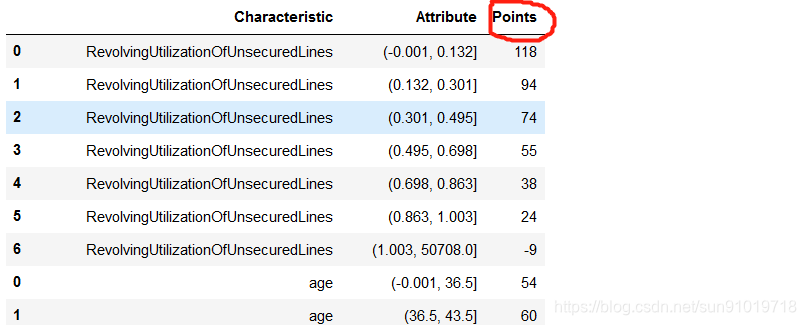
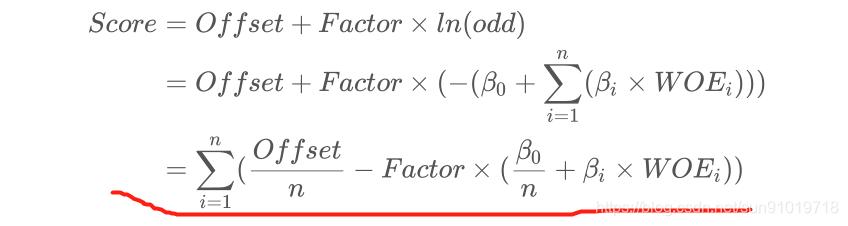 我们自定义函数ScoreCard保存的就是各分类评分结果,scorecard.ScoreCard即可获得数据。
我们自定义函数ScoreCard保存的就是各分类评分结果,scorecard.ScoreCard即可获得数据。
六、评估模型
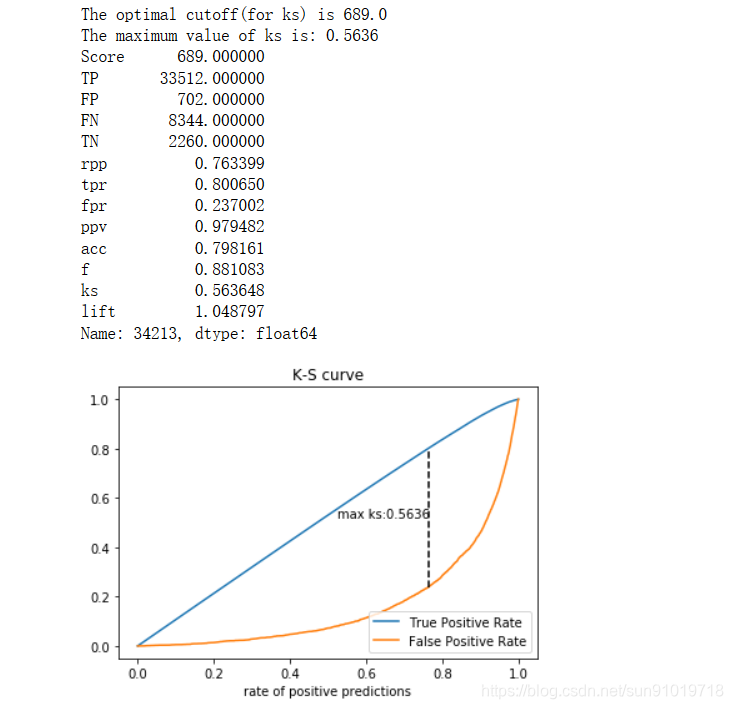
我们是通过绘制KS曲线来进行评估。
1、根据之前的分卡对象得到测试集分数。
testscore=smscoregen(scorecard,X_test)
2、通过测试集中真实的y,和预测的分数,绘制ks曲线;同时得到对应的最优阈值以及相关度量。
evaluate1=evaluate01(Y_test,testscore['Score'],index='ks',plot='ks')
七、新数据预测
1、先读取数据。
test_data=pd.read_csv('data/CreditScore_data/give-me-some-credit-dataset/cs-test.csv',index_col=0)
2、对数据进行与训练数据相同的清洗,即使用之前定义的清洗函数。
test0=datacleaning(test_data)
3、由之前得到的分箱对象生成包含woe列的数据。
test_woe=smgennew(test0,x_list)
test_woe.head()
4、抽取WOE数据生成预测用数据,并加上常数项列。
T=test_woe.iloc[:,-len(x_list):]
T=sm.add_constant(T)
5、预测每行数据的分数,生成总分数和每个特征的分数。
Tscore=smscoregen(scorecard,T)
6、根据分数和训练得到的阈值判断客户的好坏,好客户是1,坏客户是0。
test0[y]=(Tscore.Score>evaluate1.cutoff)*1
test0.head()
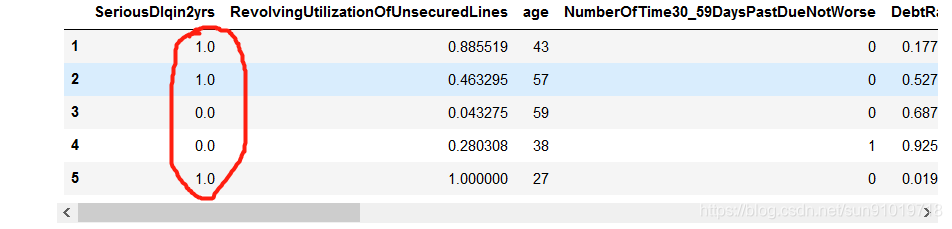
查看AUC值:evaluate1.AUC=0.8609421718165055。说明我们的模型泛化能力还是不错的。
八、总结
1、本项目的重点是分箱和找出重要特征,数据清洗的工作较少。
2、本项目难点是调参,先要固定一个score参数,然后调整其他两个参数,观察数据变化趋势。score参数相当天平中线,另两个参数pdo和odds是左右两边的砝码,左右砝码增减数据就可以达到目标。
3、需要注意的是回归类算法对重复值、缺失值、变量间共线现象特别敏感。在建模前一点要分析和处理到位。
4、另一个注意的细节就是我们在作缺失值处理前需要先划分数据集,然后再进行数据处理。在对训练集进行处理时,也要同步处理测试集数据(一定要先按训练集的逻辑)。
