文章目录
引言
以下部分完整代码见Github:https://github.com/Libra-1023/data-mining/blob/master/Bank_customer_churn/outlier_missingvalues_date_process.ipynb
一、极端值的处理
极端值又称为离群值,往往会扭曲预测结果会影响模型精度。回归模型中离群值的影响尤其大,使用该模型我们需要先对其进行监测和处理。
1.极端值(异常值)监测的重要性
- 需要自己判断极端值对建模的影响,并结合实际问题选取处理方法
- 检测极端值的重要性:由于极端值的存在,模型的估计和预测可能会有很大的偏差和变化
- 可以选择对极端值不敏感的模型,例如KNN,决策树
案例如下:
通过可视化发现,
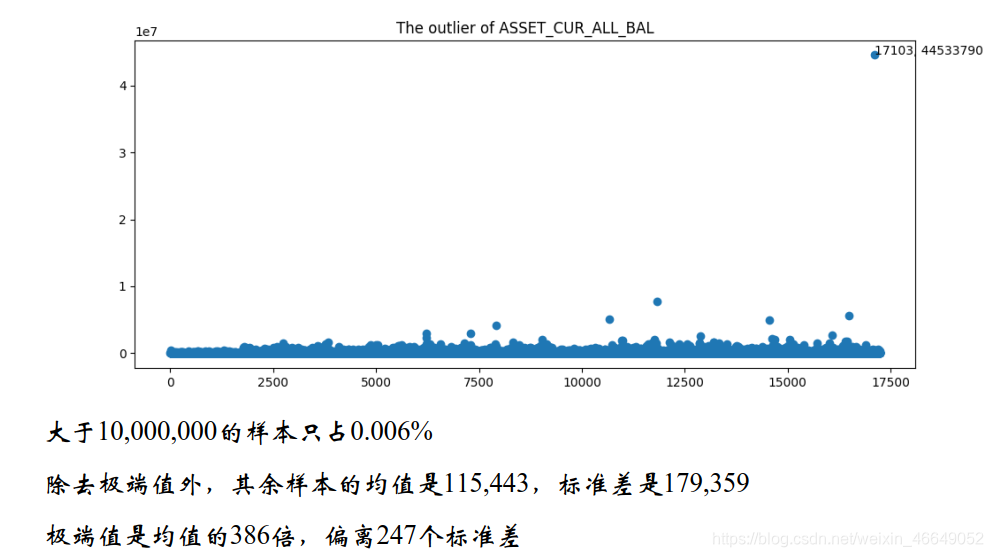
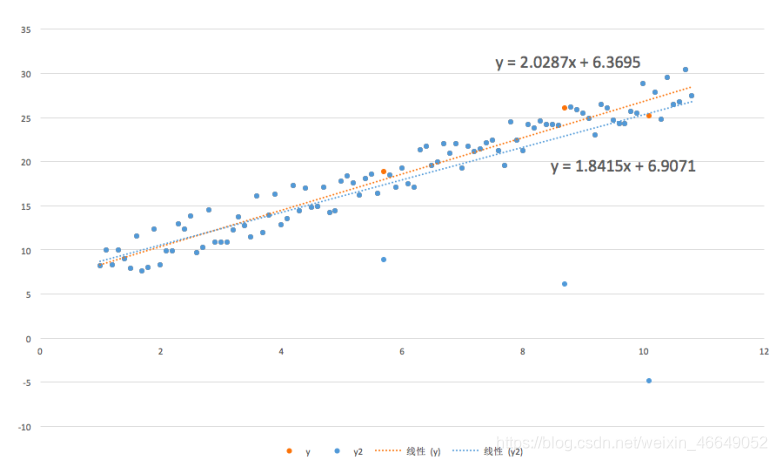
通常情况下,极端值会对模型带来一定的偏差。例如在线性回归中,极端值会显著地影响模型的参数估计。
2.极端值的处理
回归模型中,极端值通常如何处理?
- 人为降低极端值到某个正常的值,例如用95%的分位点代替(截断)
例:因为透支的信用卡使用额度超过100%,可以用100%代替 - 删除极端值
例:极个别持卡人的 年龄超过85岁 - 单独建模型
例:信用卡额度特别高
3.极端值检测的方式—3σ准则

二、缺失值的处理
1.缺失值的种类
- 完全随机缺失:缺失值跟其他变量无关,例如:婚姻状况的缺失
- 随机缺失:缺失值依赖于其他变量,例如:“配偶姓名”的缺失取决于“婚姻状况”
- 完全非随机缺失:缺失值依赖于自己,例如:高收入人群不愿意提供家庭收入
2.缺失值的处理方法
- 删除有缺失值的属性或样本(土豪行为)
- 插补填充(常用于完全随机缺失且缺失度不高的情形中)
- 将缺失当成一种属性值(常用于完全非随机缺失)
3.连续变量缺失值的处理
-
对于完全随机缺失,当缺失率不高时,可以:
1.用常数补缺,例如均值。特别地,如果存在极端值,要考虑是否剔除极端值后在计算均值
2.从非缺失值中随机抽样赋予缺失样本 -
对于依赖于其他某变量的随机缺失,可以在同一层内,用完全随机缺失的方法进行补缺
例如:变量“收入”取决于工作状态。当“工作状态”=“有工作”时,缺失值的收入可以用所有“有工作”的持卡人的已知收入的均值代替,
或者缺失值的收入可以用所有“有工作”的持卡人的已知收入的随机抽样值代替 -
对于完全非随机缺失,可以把缺失当成一种属性,将该变量转化为类别变量
4.类别型变量缺失值的处理
- 当缺失率很低时,
最常出现的类别补缺可以从其他已知的样本中随机抽样进行补缺
- 当缺失率很高时,
考虑剔除该变量(特征)
- 当缺失率介于“很低”和“很高”时,
可以当成一种类别
三、特殊变量的处理
1.类别变量
表述类别的变量,通常没有“次序”的概念,且取值范围有限。
在该数据集中指的是:性别,行业,信用卡种类等
- 有些模型可以直接读取类别变量
决策树
- 有些模型不能直接读取类别变量
回归模型
神经网络
有“距离”度量的模型(SVM,KNN等)_计算距离前要归一化 - 当类别变量不能直接放入模型时,需要编码:以数值形式代替原有值
One-hot编码—类别变量转换成稀疏矩阵
Dummy编码
浓度编码—在决策树中用的比较多
WOE编码
2.日期/时间型变量
- 常常以字符串的形式出现,例如:“2017-04-01 12:00:05”
- 本质上是数值型
- 可以基于某个基准日期,转化为天数
以观察点为基准,将所有开户日期转为距离观察点的天数
四、构建流失行为的特征
1.内部数据
- 丰富的内部交易明细数据,包括本币活期储蓄波动率、本币活期储蓄月日均余额、电话银行总交易笔数

- 可以构建的特征:
不同交易的数额的比例—ATM上交易数额与柜台上交易数额之比
单笔交易的平均数额—总交易额/总交易笔数
某种交易的笔数占全部交易交易笔数的比例 - 信息存在冗余,需要按情况进行剔除

2.外部数据
外部数据包含了客户在电信运营商的详情:
- 通话时间与次数
- 话费详情
- 特定的呼叫行为
- 其他信息
衍生的特征如下:
