转载自:https://blog.csdn.net/huozi07/article/details/50451078
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。 Logistics回归模型中因变量只有1-0,两种取值。
一、模型输入:
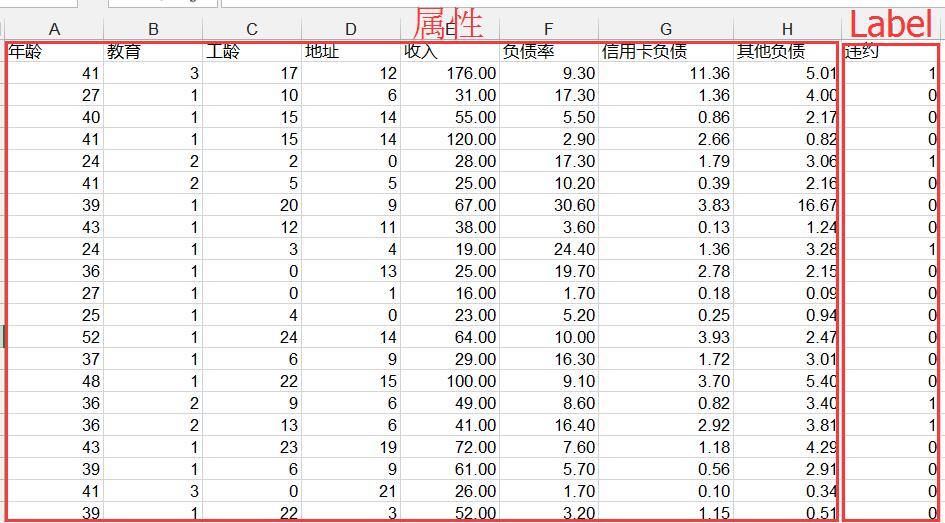
二、特征选择:
特征选择是模型成功的基础性重要工作。一般特征筛选方法有
(1)看模型系数显著性(F值大、P值小)
(2)递归特征消除:反复构建模型,根据变量系数选择最好特征,然后再递归在剩余变量上重复该过程,直到遍历所有特征。特征被挑选出顺序就是特征重要性排序顺序。
(3)稳定性选择:在不同特征子集、数据子集上运行算法,不断重复,最终汇总特征选择结果。统计,各个特征被认为是重要性特征的频率作为其重要性得分(被选为重要特征次数除以它所在子集被测试次数)。
三、pythonCode:
#-*- coding: utf-8 -*-
#逻辑回归 自动建模
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
#参数初始化
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].as_matrix()#8个属性
y = data.iloc[:,8].as_matrix()#第九列 结果标签
#稳定性选择方法 挑选特征
rlr = RLR(selection_threshold=0.5) #建立随机逻辑回归模型,筛选变量 特征筛选用了默认阈值0.25
rlr.fit(x, y) #训练模型
rlr.get_support() #获取特征筛选结果
print(u'通过随机逻辑回归模型筛选特征结束。')
print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support()]))
x = data[data.columns[rlr.get_support()]].as_matrix() #筛选好特征,重新训练模型
lr = LR() #建立逻辑货柜模型
lr.fit(x, y) #用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'模型的平均正确率为:%s' % lr.score(x, y))四、结果
通过随机逻辑回归模型筛选特征结束。
有效特征为:工龄,负债率,信用卡负债
逻辑回归模型训练结束。
模型的平均正确率为:0.8