重点为分类模型的数据理解与数据准备

数据介绍
-
账户表(Accounts):每条记录描述一个账户的静态信息

-
顾客信息表(Clients):每条记录描述一个客户的特征信息

-
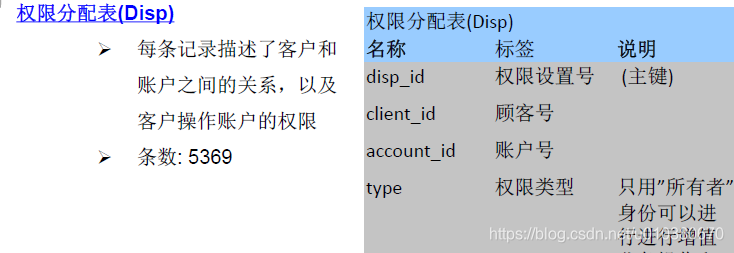
权限分配表(Disp):每条记录描述顾客和账户之间的关系,以及客户操作账户的权限
-
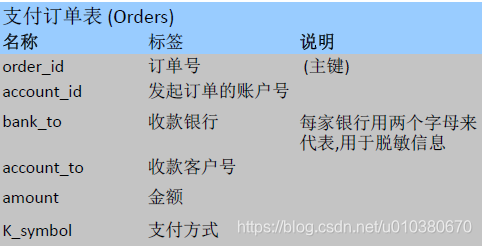
支付订单表(Orders):每条记录代表一个支付命令
-
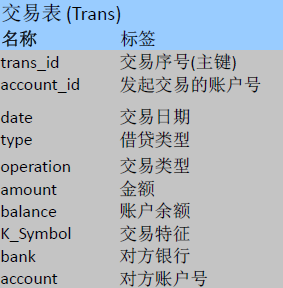
交易表(Trans):每条记录代表每个账户上的一条交易
-
贷款表(Loans):每条记录代表某个账户上的一条贷款信息

-
信用卡(Cards):每条记录描述一个顾客号的信用卡信息

-
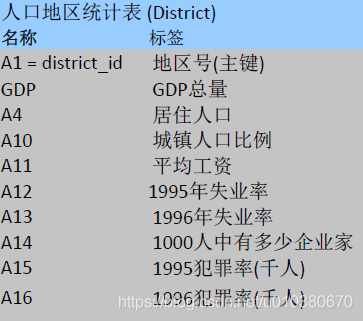
人口地区统计表(District):每条记录描述一个地区的人口统计信息
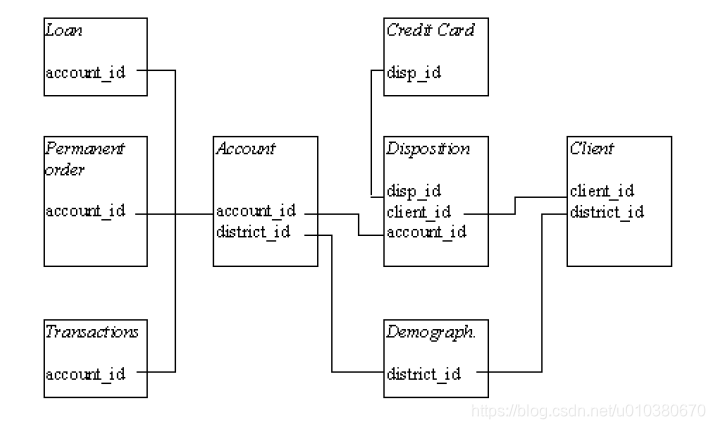
关系实体图(E-R图)可以直观描述表间关系:
业务分析
在贷款审批方面,可以通过构建量化模型对客户的信用等级进行一定的区分。在信贷资金管理方面,得知了每个账户的违约概率后,可以预估未来的坏账比例,及时做好资金安排。在这个量化模型中,被解释变量为二分类变量,因此需要构建一个排序类分类模型。而排序类分类模型中最常用的算法是逻辑回归。

数据理解
建模分析中,需要根据建模的主题进行变量的提取。
第一步维度分析
(1)属性表征信息:在分析个人客户时,又称人口统计信息。这类指标对客户的行为预测不具有因果关系,只是根据历史数据统计可得到的一些规律。
(2)行为信息:行为是内部需求在外部特定环境下的一种表现。
(3)状态信息:指客户的社会经济状态和社会网络关系。
(4)利益信息:如果可以知道客户的内在需求,当然是最理想的,而这类数据获取方式匮乏。传统方式只是通过市场调研、客户呼入或客户投诉得到相关数据。现在利用社交媒体的留言信息可以便捷地获取客户评价信息。

数据整理
在贷款表中还款状态(status)变量记录了客户的贷款偿还情况,其中A代表合同终止且正常还款,B代表合同终止但未还款,C代表合同未结束且正常还款,D代表合同未结束但是已经拖欠贷款了。以此构造一个客户信用评级模型,预测其他客户贷款违约的概率。
-
数据提取中的取数窗口

取数窗口的长短和模型易用性是一对矛盾体:窗口期越短,缺失值越少,可分析的样本就越多,越便于使用。但是单个变量的观测期越短,数据越不稳定;窗口越长,新的客户就会因为变量缺失而无法纳入研究样本。
同样,预测窗口取决于构建什么样的模型以及目标变量是什么。比如营销响应预测窗口取三天到一周,信用卡违约须要一年。 -
导入数据
import pandas as pd
import numpy as np
import os
os.chdir(r’’)
os.getcwd()
loanfile = os.listdir()
createVar = locals()
for i in loanfile:
if i.endswith("csv"):
createVar[i.split('.')[0]]=pd.read_csv(i,encoding = 'gbk')
print(i.split('.')[0])
bad_good = {'B':1,'D':1,'A':0,'C':2}
loans['bad_good']=loans.status.map(bad_good)
loans.head()
- 表征信息
将所有维度的信息归结到贷款表上,每个贷款账户只有一条记录。
data2 =pd.merge(loans,disp,on = 'account_id',how ='left')
data2 = pd.merge(data2,clients,on = 'client_id',how = 'left')
- 状态信息
提取借款人居住地情况
data3 = pd.merge(data2,district,left_on = 'district_id',right_on = 'A1',how = 'left')
- 行为信息
根据客户的账户变动的行为信息,考察借款人还款能力
#将贷款表和交易表按照account_id内连接
data_4temp1=pd.merge(loans[['account_id','date']],
trans[['account_id','type','amount','balance','date']],
on = 'account_id')
data_4temp1.columns = ['account_id','date','type','amount','balance','t_date']
data_4temp1 = data_4temp1.sort_values(by=['account_id','t_date'])
#将来自贷款表和交易表的两个字符串类型日期变量转换为日期
data_4temp1['date']=pd.to_datetime(data_4temp1['date'])
data_4temp1['t_date']=pd.to_datetime(data_4temp1['t_date'])
#账户余额和交易额度为字符变量,有千分位符,需要进行数据清洗,并转换为数值类型
data_4temp1['balance2']=data_4temp1['balance'].map(lambda x:int(''.join(x[1:].split(','))))
data_4temp1['amount2']=data_4temp1['amount'].map(lambda x: int(''.join(x[1:].split(','))))
`
#窗口取数,只保留贷款日期前365天至贷款前1天内的交易数据、
import datetime
data_4temp2 = data_4temp1[data_4temp1.date>data_4temp1.t_date][data_4temp1.date<data_4temp1.t_date+datetime.timedelta(days=365)]
#每个贷款账户贷款前一年的平均账户余额、账户余额的标准差和变异系数
data_4temp3 = data_4temp2.groupby('account_id')['balance2'].agg([('avg_balance','mean'),('stdev_balance','std')])
data_4temp3['cv_balance'] = data_4temp3[['avg_balance','stdev_balance']].apply(lambda x:x[1]/x[0],axis=1)
type_dict ={'借':'out','贷':'income'}
data_4temp2['type1'] =data_4temp2.type.map(type_dict)
data_4temp4 = data_4temp2.groupby(['account_id','type1'])[['amount2']].sum()
data_4temp5 = pd.pivot_table(data_4temp4,values = 'amount2',index = 'account_id',columns = 'type1')
data_4temp5.fillna(0,inplace = True)
data_4temp5['r_out_in']=data_4temp5[['out','income']].apply(lambda x: x[0]/x[1],axis = 1)
data4 = pd.merge(data3,data_4temp3,left_on = 'account_id',right_index = True,how = 'left')
data4 = pd.merge(data4,data_4temp5,left_on = 'account_id',right_index = True,how = 'left')
data4['r_lb'] = data4[['amount','avg_balance']].apply(lambda x:x[0]/x[1],axis=1)
data4['r_lincome'] = data4[['amount','income']].apply(lambda x: x[0]/x[1],axis=1)
建立分析模型
- 提取状态为C的样本用于预测
data_model = data4[data4.status!='C']
for_predict = data4[data4.status=='C']
train = data_model.sample(frac = 0.7, random_state = 1235).copy()
test = data_model[~data_model.index.isin(train.index)].copy()
print("训练集样本量:%i \n测试集样本量:%i" %(len(train),len(test)))
- 使用向前逐步法进行逻辑回归建模
import statsmodels.formula.api as smf
import statsmodels.api as sm
def forward_select(data, response):
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
aic = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit()
return(model)
candidates = ['bad_good','A1','GDP','A4','A10','A11','A12','amount','duration','A13','A14','A15','a16','avg_balance','stdev_balance',
'cv_balance','income','out','r_out_in','r_lb','r_lincome']
data_for_select = train[candidates]
lg_ml= forward_select(data=data_for_select,response='bad_good')
lg_ml.summary().tables[1]
- 模型效果评估
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
fpr , tpr,th = metrics.roc_curve(test.bad_good,lg_ml.predict(test))
plt.figure(figsize=[6,6])
plt.plot(fpr,tpr,'b--')
plt.title('ROC curve')
plt.show()
模型运用
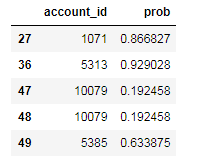
for_predict['prob']=lg_ml.predict(for_predict)
for_predict[['account_id','prob']].head()