引言
下面使用的是jupyter notebook,完整代码解析见Github:https://github.com/Libra-1023/data-mining/blob/master/Bank_customer_churn/Bank_customer_churn_EDA.ipynb
一、银行业客户群体与产品的类别
银行的客户总体上可分为个人客户与公司客户。
银行对个人客户的业务主要是以合理安排客户的个人财务为手段,为之提供存取款、小额贷款、代理投资理财、信息咨询以及其他各类中介服务,由此为客户取得收益,并帮助其防范风险,同时提高银行自身效益。
公司客户指与银行发生业务关系的各企事业单位及政府机关,其中以企业单位为主体。公司客户能为银行带来大量的存款,贷款和收费业务,并成为银行利润的重要来源。
零售客户一般分为以下5种:

银行的业务一般分为资产类业务与负债类业务。
银行信贷类资产业务:
- 信用贷款
- 抵押贷款—分为存货抵押贷款与不动产抵押贷款
- 保证书担保贷款
- 贷款证券化
银行负债类业务:
- 活期存款
- 定期存款
- 储蓄存款
- 可转让定期存单
- 其他种类
二、客户流失预警模型的业务意义
严格来讲,客户流失指的是客户在该行所有业务终止并销号。但是具体业务部门可单独定义在该部门的全部业务或某些业务上,客户的终止行为。
研究结果表明:商业银行客户流失比较严重,国内商业银行,客户流失率可达到20%甚至更高。而获得新客户的成本,可达维护现有客户的5倍。因此,从海量的客户交易记录中挖掘出对流失有影响的信息,建立高效的客户流失预警体系尤为重要。
客户流失的主要原因包括:
- 价格流失
- 产品流失
- 服务流失
- 市场流失
- 促销流失
- 技术流失
- 政治流失
维护客户关系的基本方法:
- 追踪制度
- 产品跟进
- 扩大销售
- 维护访问
- 机制维护
建立量化模型,合理预测客群的潜在流失风险
- 常用的风险因子
- 客户持有的产品数量、种类
- 客户的年龄、性别
- 受地理区域的影响
- 受产品类别的影响
- 交易的间隔时间
- 营销、促销手段
- 银行的服务方式和态度
三、数据介绍与描述
该数据集共17241例客户数据,其中有1741例流失样本,总流失率达到10.10%
数据分为两部分:银行自有字段、外部第三方数据
银行自有字段:
- 账户类信息
- 个人类信息
- 存款类信息
- 消费、交易类信息
- 理财、基金类信息
- 柜台服务、网银类信息
外部第三方数据:
- 外呼客户数据
- 资产类数据
- 其他消费类数据
1.单因子分析之连续变量
-
有效记录的占比—缺失率
# 提取出不含空值的包含自变量和因变量的数据集, np.nan != np.nan validDf = df.loc[df[col] == df[col]][[col,target]] # 非缺失度的百分比 validRcd = validDf.shape[0]*1.0/df.shape[0] # 格式化非缺失度 validRcdFmt = "%.2f%%"%(validRcd*100) -
整体分布
初始分布与截断分布# 截断 if truncation == True: # 截断分布 pcnt95 = np.percentile(validDf[col],95) # 将流失客户与非流失客户的存款额大于截断值的赋值于截断值 x = x.map(lambda x: min(x,pcnt95)) y = y.map(lambda x: min(x,pcnt95)) -
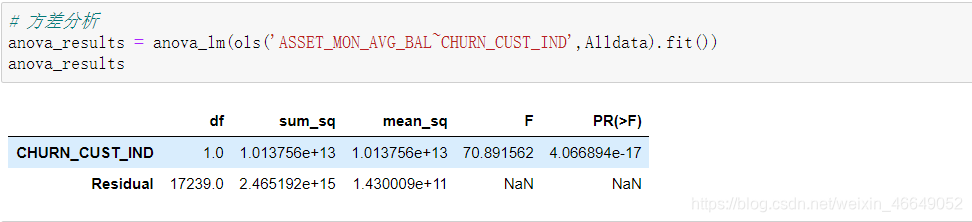
按目标变量分布的差异
方差分析:维基百科—方差分析
2.单因子分析之类别变量
-
有效记录的占比
validDf = df.loc[df[col] == df[col]][[col, target]] validRcd = validDf.shape[0]*1.0/df.shape[0] recdNum = validDf.shape[0] validRcdFmt = "%.2f%%"%(validRcd*100) -
种类
-
整体分布
# 对类别型变量进行单因子分析 filepath = path+r'/单因子分析/类别型变量/' for val in stringCols: CharVarPerf(Alldata,val,'CHURN_CUST_IND',filepath) -
按目标变量分布的差异
卡方检验:维基百科—卡方检验
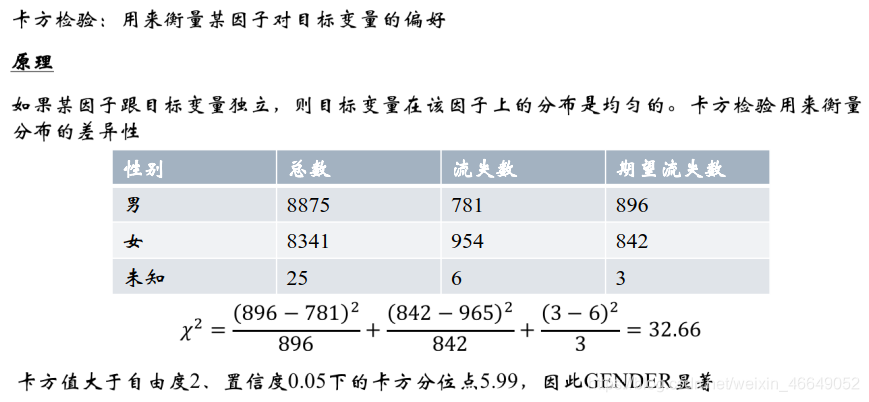
chisqDf = Alldata[['GENDER_CD','CHURN_CUST_IND']]
grouped = chisqDf['CHURN_CUST_IND'].groupby(chisqDf['GENDER_CD']) # 分组
count = list(grouped.count())
churn = list(grouped.sum())
chisqTable = pd.DataFrame({
'total':count,'churn':churn})
# 0.101为期望流失率,相乘即为期望流失人数
chisqTable['expected'] = chisqTable['total'].map(lambda x: round(x*0.101))
chisqValList = chisqTable[['churn','expected']].apply(lambda x: (x[0]-x[1])**2/x[1], axis=1)
# chisqVal即为卡方
chisqVal = sum(chisqValList)
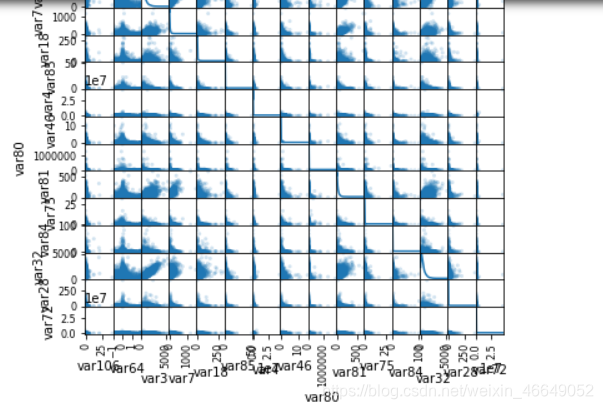
3.多因子分析
变量之间由于业务关系、计算逻辑等业务存在一定的两两共线性,需要研究这种共线性并做适当的处理
- 信息的冗余
- 维护数据的成本
- 对某些模型存在一定的影响
# 使用短名称代替原始名称,因为原始名称太长而无法显示
col_to_index = {
numericCols[i] : 'var'+str(i) for i in range(len(numericCols))}
# 在columns列表中取样,因为单个图无法显示太多的列
corrCols = random.sample(numericCols,15)
sampleDf = Alldata[corrCols]
for col in corrCols:
sampleDf.rename(columns = {
col : col_to_index[col]},inplace = True)
# 画散点矩阵图
# diagonal = 'hist' or 'kde',当diagonal = 'hist'时,为对角线直方图,当diagonal='kde'时,为核密度估计函数
# alpha=0.2为透明度
scatter_matrix(sampleDf, alpha=0.2, figsize=(6, 6), diagonal='kde')