基础
将一个样本点齐次化
给定 ( 3 , 2 ) (3,2) (3,2),其对应的齐次坐标就是 ( 1 , 3 , 2 ) (1,3,2) (1,3,2),即最前面加一个1。一般地:
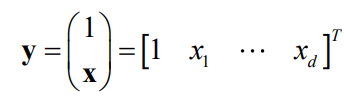
将负类样本规范化,假设 ( 1 , 3 , 2 ) (1,3,2) (1,3,2)是负类,那么将其规范化成 ( − 1 , − 3 , − 2 ) (-1,-3,-2) (−1,−3,−2)。
即:

然后我们探讨其线性可分性:
如果存在 a a a使得:

那么就是线性可分地,直观例子:
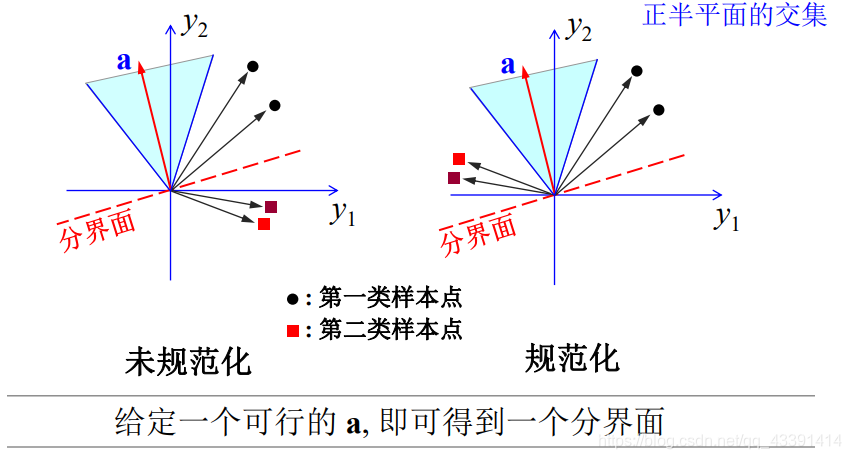
解释:a有很多,上面红色就是一个,另外,蓝色区域每一个a都是可以的,这样,我们就得到了分界函数: y = a T x y=a^Tx y=aTx。
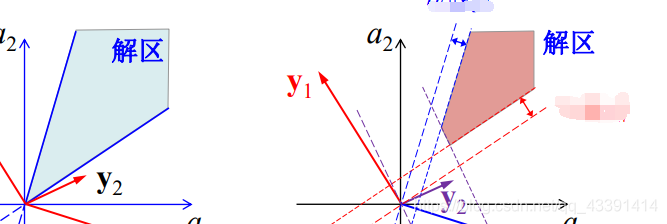
但是,我们需要限制解区间,因为如果线性可分,a有无数个。

我们可以如下:
感知准则函数


其中:

鉴于参数更新的在程序中的具体时间,分为单样本更新和批量更新。
其中,每一种更新又可以按照更新步长的大小分为固定增量和可变增量两种。即一个是更新步长固定,知道模型训练完毕,另外一个是更新步长会随着迭代次数或者梯度大小而动态调整,称为可变增量。举例:

梯度更新的几何解释:
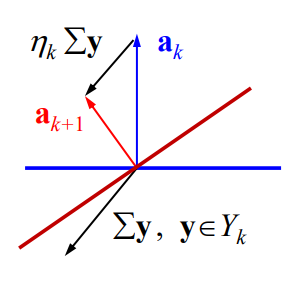
另外一个解释:

即:如果原来 y k y_k yk分错了,也就是 a k T y k < 0 a_k^Ty_k<0 akTyk<0,现在改变之后的内积,加了一个正数,那么更有可能 a k + 1 a_{k+1} ak+1可以分对 > 0 >0 >0了。
其他相关方法:

前两者均有一些缺点,第3个最好。

解释:有些人不明白为什么线性准则的目标函数是分段线性的,为什么后两者的梯度又是连续的。首先你要知道
- 分段线性是对a而言的。即a是变量,每一个a会确定一批的y,从而可以写出一个损失函数,而且是线性的,等a到某一个临界值之后(一般有很多个),会发生转折,即分段线性。可以想象 y = ∣ x ∣ y=|x| y=∣x∣的例子。这个函数在0连续,但不可导,而我们恰恰要求导数。万一运气不好a在那里了,那就不好了。但是我觉得一般是不会的。
- 对绝对值函数做一个平方,当然平滑了。
松弛准则的优点:


伪代码:

注解:此处采用的批处理更新,而且这里的批直接是指全样本。至于是否采用固定增量,随便吧。

最小化平方误差方法MSE
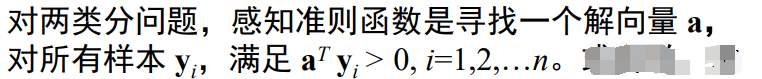

即:

原来是不等式,现在改成等式,显然是没有解向量a的,即Y不可逆,所以我们定义误差函数,背地里允许等式不相等。

马上有:


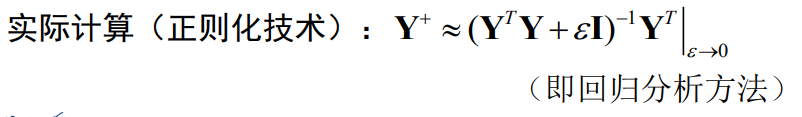


很显然,是单样本可变增量更新。

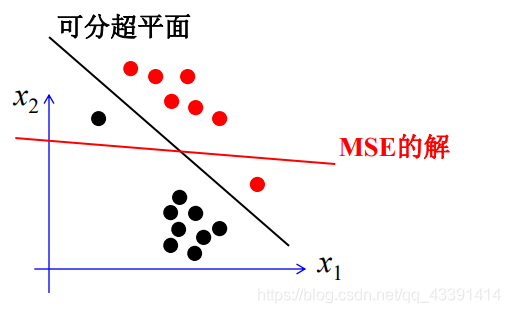
大家应该要能意识到,MSE的问题,允许不相等,那么可能会带来样本分错!


可能存在情况:
Ho-Kashyap方法

此方法还不错,很明显,我们之前的MSE是固定b是一个给定的值,比如1,所有都是 b i = 1 b_i=1 bi=1。这个改变了,也变成了一个参数但是我们不知道是几,相当于也要参与到模型的训练中并学习到。

注意这里的向量为负是指将向量的每一个分量中值为正数,则改为0,否则保持原样。

即初始化b为正数,还有其他参数初始化之后,先利用b更新a,然后再更新b,然后再下一轮。很显然,MSE一般只有一轮,即直接利固定的b使用伪逆计算得到a就完事了。所以说此算法有推广MSE的意味。


MSE多类扩展
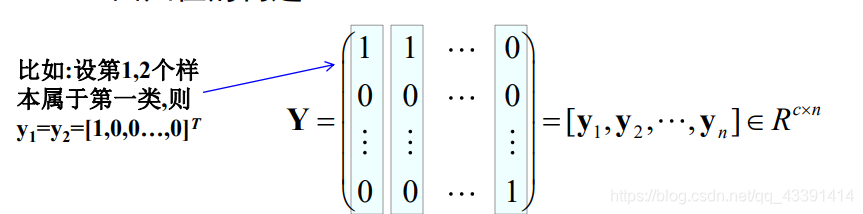
即原来是全为1的向量, b = 1 b=1 b=1,现在变成了矩阵。而且每一个类别都有一个判别函数。
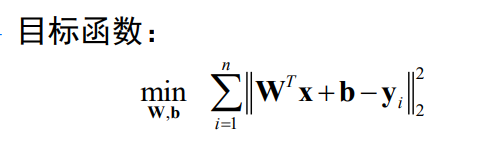
从而有:
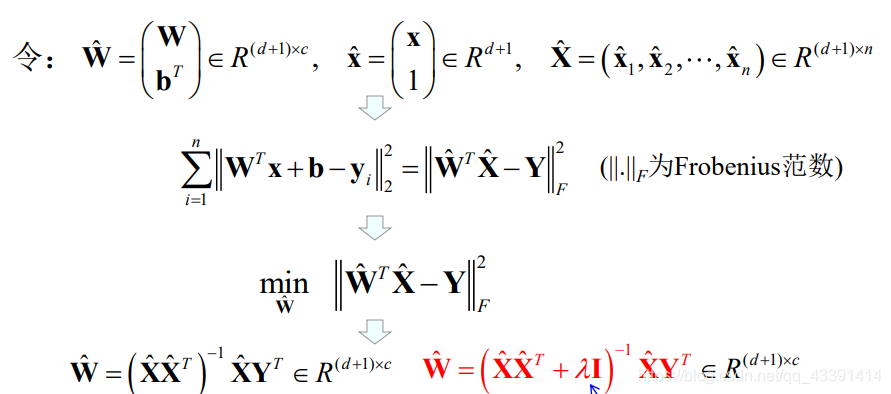
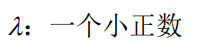
其他多类的方法:



即对一个样本,只改两个权重向量,这很启发式,所以你可以随便设计。

最后一个多类的方法:

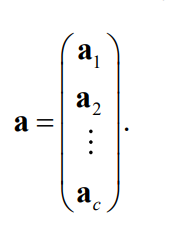
对于一个样本,复制出这么多个样本出来
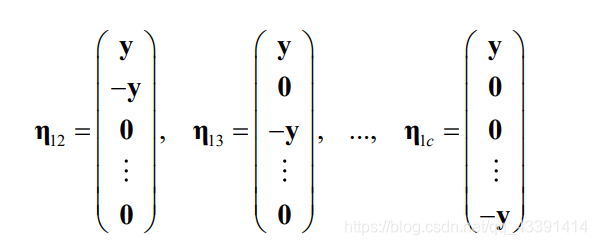
你应该要能发现:上面的 y y y样本是属于第一类的。
最终:
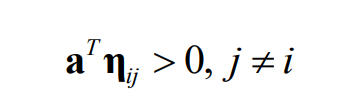
大家可以试试,对于上面的第一类样本 y y y而言,如果满足了上面的这个式子,那么有:
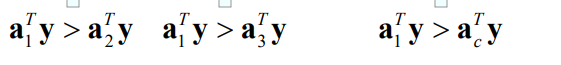
这就是我们的思路,其他样本也是类似,慢慢优化,最终使得全部样本都分对。
