LDA是一种监督学习,通常作为数据预处理阶段的降维技术。监督降维方法!!!
LDA降维的步骤:
- 计算每个类别样本的均值向量,所有样本的均值向量
- 通过均值向量,计算类间散度矩阵 和类内散度矩阵
- 对 进行特征值求解,选择前K个特征向量组成 ,其中K最大为N-1(N是类别数)
- 新的子空间:
LDA核心思想:
最大化类间距离,最小化类内距离。
从简单入手,考虑二分类。
LDA最大化的目标:
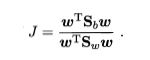
其中,
是类间散度矩阵,
是类内散度矩阵。
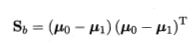
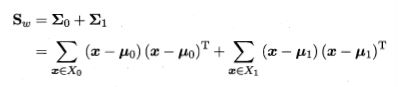
注意到,解与w的长度无关,只与其方向有关,因此,令分母为1。
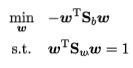
由拉格朗日乘子法,得到
前面提到
因此
,根据结合律,后面两项的结果是一个数
将LDA推广到多分类
在多分类情况下,类内散度的定义不变

其中,
是类别个数。
定义一个新的概念,全局散度矩阵=类内散度矩阵+类间散度矩阵
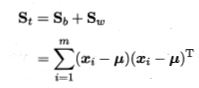
其中
是所有样本的均值向量,
是样本个数。
从而,
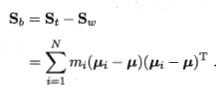
再次提醒,
是类别个数,
是第
类的样本个数。
常见的优化目标是:

其中,

多分类LDA将样本投影到K维空间(K最大为N-1,N是类别数),K通常远小于数据维度,并且投影过程中使用了类别信息,LDA是一种监督降维方法。
LDA和PCA的比较请见PCA文章
[1] https://zhuanlan.zhihu.com/p/27899927
[2] https://www.cnblogs.com/pinard/p/6244265.html