Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking论文笔记
CSDN新的开始
文章目录
Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking
Oxford and Paris是图像检索中深受欢迎的两个数据集,其中Oxford有5063张图像,Paris有6392张图像,(图像分辨率为1024*768),包含了多达数百张正样本图像。
一、Oxford and Paris
1 两数据集基本情况
1.)在这两个数据集中,没个数据集包含了55个查询,共11个landmark,每个landmark包含5个查询
2.)原始的标注是手动进行的,由11个gt列表组成(同一个landmark的5个图像组成一个查询组)
3.)使用了3个标签:Positive、Junk、Negative
4.)性能是用55个查询的mAP来衡量的(标签为Junk的图像被忽略了,就仿佛他们不在数据库中一样)
2 存在问题
然而,由于年份较久且标注视角在变化,这两个数据集存在一些问题亟待解决
1.)标注错误
2.)数据量少
3.)现有的这两个数据集很难再定量评估目前的新方法
3 论文贡献
为解决上述问题,论文作出了以下贡献
1.)在原有的数据集上,提出了ROxford、RParis和R1M
ROxford和RParis作出了以下改变:
(1)重新标注,修复了之前的标签存在的问题
(2)增加了查询的数量,从55个查询变为70
(3)重新分配了标签:Easy、Hard、Unclear和Negative
2.)提出了三种评估方式:Easy、Medium、Hard
3.)进行了实验,对多种知名方法进行实验验证
二、Revisiting
数据集的annotation是由5个标注者执行的,并按照以下步骤进行
1.1 Query groups
查询组共享相同的gt列表并简化了标签问题,但这也会导致原注释的不准确
例如:
在原有的数据集中,第2和第4个查询,有两个地标是分别从不完全对称的不同侧面进行描述的,
此外,在凯旋门这一地标中,有三天两夜的查询,而昼夜匹配一直是图像检索领域一个比较值得关注的课题
本文作者在思考了上述情况后,把这些cases归到不同的组里,结果就是形成了Oxford的13个查询组和Paris的12个查询组
1.2 Additional queries
与原来数据集相比,本文引入了新的更具有挑战性的查询
下图是来自文章图1,向我们展示了新添加的数据集查询ROxford(top)和 RParis(bottom),与原始的合并后,一共有了70个查询
70
= 55(原有query:11个地标 * 5张图像)
+15 (新query:选择原11个地标中的5个地标 * 3张图像)
defined by visual similarity,ROxford和 RParis的查询组分别是26和25

并且作者对他们做了处理,模拟了图像检索的实际应用中可能出现的试图去除背景clutter或者大规模遮挡的情况
1.3 标记步骤1: 潜在正样本的选择
作者做了一系列工作,就是为了把原数据集中标记错成负样本的正样本找出来并加以改正,为每一个地标都创建了一个潜在正样本的列表
1.4 标记步骤2: 标签分配
5个标记者手动检查了每个查询组的潜在正样本列表并分配标签,可能出现的标签有以下4个:Easy、Hard、Unclear和Negative
下表展示了将标签从原始标注(Positive、Junk、Negative)切换到新的标注(Easy、Hard、Unclear和Negative)的图像数
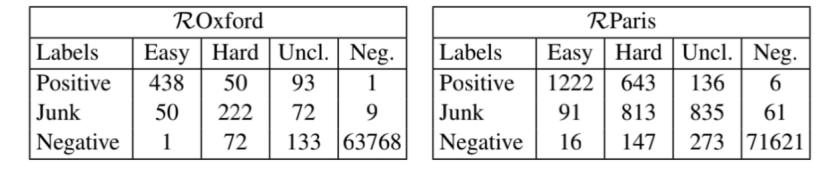
1.5 标签步骤3: 细化
5个标记者根据投票的方式来决定最终标签,先分为3组进行投票{ Easy、Hard }(E和H最后再进行比较)、{Unclear}和{Negative}
例如:
(EEHUU) ——> E
(HHUUN)——> U
(HHUNN)——> U
1.6 重访数据集:ROxford和 RParis
任何预处理都不应包括查询图像的任何部分
在删除70个查询后,重新访问的数据集ROxford和RParis分别包含4993和6322个图像。
下图来自文章图2,展示了原始极端的标记错误的典型示例。向我们展示了查询(蓝色)图像和最初标记为负数(红色)或正(绿色)的关联数据库图像

在图3中,为几个查询提供了简单、困难和不清晰图像的代表性示例

2 评估方案
遵循性能评估报告平均平均精度(mAP)[33]的标准实践。此外,还报告了秩K (mP@K)的平均精度。前者反映了排行榜的整体质量。后者反映了搜索引擎结果的质量,因为用户可以直观地检查结果。
在计算期间,应该检索正图像,同时每个查询也有一个忽略列表。通过将标签(容易、难、不清楚)视为正面或负面,或忽略它们,定义了三种不同难度的评估设置:
简单(E):标记为easy的图像被视为positive的,而hard和unclear的被忽略(和[33]中的junk一样)。
中等(M):标记为easy的图像和hard的图像被视为positive,而unclear的图像则被忽略。
困难(H):hard图像被视为positive,而标记为easy的图像和unclear的图像被忽略。
3 Distractor set R1M
本文构造了一个新的Distractor set,它包含1,001,001 幅高分辨率(1024×768)图像,我们称之为R1M数据集。它是用半自动过程清洗的。
本文作者会自动为许多最先进的方法选择Hard评估方案,从而产生具有挑战性的大规模设置。
三、广泛实验
本文在新的基准测试中评估了许多最先进的方法,并为未来的比较提供了一个丰富的测试平台。
在文章的第三小节中列出了它们,这些方法属于两大类,即使用局部特征的经典检索方法和基于CNN的生成全局图像描述符的方法。
总结
本文是一个Benchmarking,相当于建立了一个较大的实验台,讲了对已有两个数据集作出的改进与之前的数据集之间的性能比较,在进行图像检索学习之前,对这篇论文进行简单的了解,有助于我们更好的使用这两个数据集。