本文为《Indoor Visual Positioning Aided by CNN-Based Image Retrieval: Training-Free, 3D Modeling-Free》学习笔记,欢迎交流
关键词: 室内定位;图像地理定位;图像检索;CNN 特征点;位姿估计
一、摘要
问题:室内视觉定位的准确性和成本之间难以权衡
方法: 提出了一种基于图像检索的定位方法。
- 基于 CNN 的图像检索阶段,预训练的深度卷积神经网络(DCNN)提取 CNN 特征,用来比较相似性,输出匹配的图像
- 位姿估计阶段。鲁棒的 CNN 特征提取器,方案适用于复杂的室内且能移植到户外。单目视觉里程计,只需要 RGB 图像及位姿。使用 lightweight datum 呈现场景。
- 通过数据集进行验证。
结果: 该方法定位精确度高,易用性好,应用前景好,数据采集算法和位姿估计与数据扩展兼容。
二、结论
课题构思(如何一步步得到结论):
- 利用基于 CNN 的图像检索策略,将查询图像与数据库图像进行特征匹配;
- 从 ORB 特征点的对应关系中估计查询图像的姿态。
- 首次同时使用基于 CNN 的图像检索与仅使用 RGB 图像。基于图像的定位将成为主流。数据获取和位姿估计算法符合现有的 data expansion。从粗到精的思想将广泛使用
未解问题:
- 使用图像集定义空间
- 可以提高效率和鲁棒性,表示更复杂和大规模的场景。
三、粗看图表
数据来源: ICL-NUIM 数据集,TUM RGB-D 数据集
重要指标: 累计分布函数(CDF);位姿估计误差;
四、引言
研究原因:
-
移动端常用 GNSS 方法定位,易被障碍物遮挡,仅适用于户外。
-
基于指纹的定位算法 infrastructure-free,将接收到的 RSS 和 MFS 与数据库比较。
- 优点:容易构建,短期定位性能好;
- 缺点:因信号模式随时间变化,长期性能差;构建数据库耗时耗力。
- 替代方案有:Optical,RFID,蓝牙信标,ZigBee,伪卫星。精度不够,需要人工设置、额外 infrastructure-free 代价过多。
-
基于识别的图像定位方法类似于图像分类,进行特征点匹配。根据检索的相关图像估计目标图像定位。精度低
-
基于几何匹配的方法用几何参考 3D 模型表示场景,用 2D-3D 或 3D-3D 的特征点匹配估计位姿。通常需要估计 6 个 DoF 的相机参数。但其中的位置对齐问题很难解决
-
文中的方案结合了基于识别和基于几何匹配策略。精度高并且 determining orientations
课题阶段:
视觉定位系统可以大致分为三类:
-
基于结构-最常用
原理:利用局部特征估计 2D-3D 或 3D-3D 匹配,根据对应关系估算姿态。
成果:纯基于 2D 的方法定位水平低,基于 3D 的方法模型的构建和维护复杂。基于 2D 的方法与局部 SfM 重建结合,数据库构造简单且姿态估计准确,但定位时运行时间较长。
-
基于图像-受益于地理标记的图像资料库的发展
原理:将地理标记的图像作为参考,利用基于图像检索策略。
传统:基于局部描述子匹配和空间验证重排。基于内容的图像检索依靠边缘、颜色、纹理和形状等视觉内容。
当今:利用 DCNN 进行图像检索。将预训练的网络作为局部特征描述子。一些工作甚至解决了 CNN 特征的几何不变性。
-
基于学习-最近几年得益于计算机视觉任务的进步
原理:利用带姿势信息的图像训练模型,来表示场景。可以预测位姿估计的匹配或直接回归相机位姿。
成果:PoseNet 使用 DCNN 解决度量定位问题,用贝叶斯 CNN 解决位姿不确定性;利用 LSTM 和对称编码器-解码器等架构提高 DCNN 的性能。
从粗到精的思想
- 利用场景识别定位场景级别的区域,采用多传感器融合方法来给出确切定位;
- 纯基于视觉的方法:将定位问题转换为在包含线段的 3D 模型中,查询图像的边缘对齐问题
- 利用基于识别的阶段粗略定位,然后在小区域内采用匹配。但基于 SIFT 的图像检索在室内环境不稳定,无法广泛使用;
- 文中提出的方法采用基于 CNN 的图像检索方案。对于室内场景有效,且无需 3D 模型。
主要贡献: 将图像检索与基于特征的位姿估计结合,图像检索阶段使用 ImageNet 上预训练的网络作为特征提取器。基于地理标记的图像估计位姿,使用相邻帧的图像并且估计第一帧的位姿。用两张连续图像表示局部场景,从其中一个图像中计算查询图像的位姿。但是位姿估计依赖图像间的相似程度。
- 基于图像的视觉定位方案,匹配最相似的图像
- 无需 3D 模型,从 2D-2D 匹配中恢复位姿
- DCNN 模型很稳健,无需为特定场景训练特殊模型。具有通用性
- 使用轻量模型,使用更少的图像进行位姿定位
五、实验过程
模型步骤,每个步骤的结论:
系统概述及方法
-
系统架构:使用 RGB 图像,实现亚米级精度且能估计 orientation。
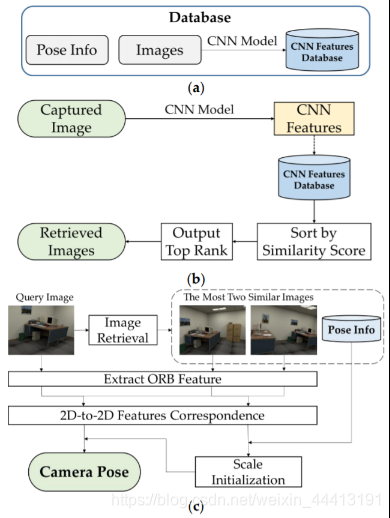
- 数据准备:通过预先训练的 CNN 模型从 RGB 图像中提取 CNN 特征,离线完成。
- 图像检索:加载数据库中图像的所有 CNN 特征,根据特征相似度排序,输出最高相似度的图像集。
- 姿态估计:利用从 2 张检索到的图像中提取特征点的 2D-2D 对应关系计算单目视觉 setting 中的尺度,利用特征点匹配计算查询图像位姿。
-
数据准备
相邻图像要有足够的相似区域以进行特征匹配;图像太多,数据采集和计算的时间过多。数据库的组成如下:

其中 为对应场景下的彩色图像, 为图像关联的位姿,其中旋转部分用四元数表示。
-
基于 CNN 的图像检索
-
深度卷积神经网络(DCNN)
CNNs 的配置与 VGG16 相似,VGG16 在大规模图像识别任务中性能较好。VGG-Nets 采用了与普通 CNNs 相同的原理,该方法的关键是利用 3×3 卷积过滤器体系结构来增加深度。
文章使用 VGG16,包括 13 个卷积层+ 5 个 max pooling 层+ 3 个全连接层+ 1 个 soft-max 层。使用 CNN 进行图像的特征提取。鉴于 CNNs 的表达能力,采用基于 ImageNet 的预训练网络。
-
CNNs 提取的深度特征
在特征地图的可视化中,更深层的特征可以更好的表现图像。深层特征可以更好的表示图像,图像检索精度更高。卷积层(ReLU 和 max pooling)从输入图像中提取特征,特征对尺度和平移鲁棒。随后将图像特征聚合为固定长度的紧凑特征向量。
-
使用深度特征检索图像
使用 计算图像间的得分,排序后输出最相似的检索图像集(取 2 个)。
-
-
姿态估计
图像检索阶段获得与查询图像最相似的 2 个地理标记图像。位姿估计步骤:
- 提取关键点和描述符表达 3 个图像;
- 计算图像间从 2D-2D 匹配的变换;
- 使用变换和 2 个检索图像位姿,计算单目视觉的缩放比例;
- 通过单目视觉比例及查询图像和最相似图像间的转换来计算查询图像的位姿。
如果图像用不同相机获取,则相机内参的差异可能会影响定位性能,因此需事先标定。若前 2 个检索图像估计位姿失败,则所有图像在检索阶段重排序。若计算图像间 2D-2D 匹配的变换失败,取下个排名的检索图像进行变换计算。
-
特征检测和匹配
SIFT 的计算成本过大,文章选取 ORB 作为点特征检测器,用汉明距离作为距离度量以匹配特征。
-
图像特征对应的移动(与《视觉 SLAM 十四讲》2D-2D 部分相同)
使用对极约束可从 2D-2D 特征对应关系计算本质矩阵 E,用来描述两个图像间的几何关系。使用奇异值分解(SVD)从 E 中提取旋转和平移。
-
确定尺度
本质矩阵缺少尺度信息。对检索图像 使用对极约束计算出 ,再用计算出 。对比两者,旋转矩阵部分约等,平移向量部分相差一个比例即为深度。
-
查询图像的位姿估计
使用 2 个检索图像计算深度。已知检索图像位姿,可以通过 1 个检索图像计算变换矩阵,从变换矩阵中计算出位姿
实验评估
-
数据采集
利用视觉里程计的图像及位姿(视觉定位和视觉里程计的任务相似)。从 ICL-NUIM 和 TUM RGB-D 的不同场景中手动选择图像来组成自己的实验数据集。
-
图像检索的性能
使用平均精度(=良好匹配数量/图像总数)估计图像检索的性能。因为特征提取和匹配影响位姿估计,我们需要尽可能多的特征点,才能有更多的相似区域。提取特征点和描述子,设定最小距离的两倍和常数间的较大数为阈值(因为海明距离可能很小),计算良好匹配的数量。
目前基于图像的室内定位方案在 SIFT 特征上使用 FLANN 搜索,匹配精度不如本文提出的基于 CNN 特征方案,因为 CNN 特征可以更好地表示图像。
-
定位结果与分析
位姿估计性能达到亚米级,使用误差中位数评价平移和旋转估计的性能(未移除异常点)。
使用 CNN 特征和点特征联合估计位姿,与当前的 CNN 方案相比有更好的定位精度和相同的旋转精度。
构建数据库时需要的数据更少,减少存储。并分析了时间性能。
讨论
- 基于 CNN 的策略的输出图像有很高的空间相关性,并且能够表示场景。无需 3D 模型,带有原始图像和位姿的 CNN 特征能在视觉定位中表示整个区域
- 使用对应点策略估计位姿。与 2D-3D、3D-3D 方法相比,文中的方案只需要校准的单目相机
- 对比端到端的基于学习的方案,它是直接回归位姿,文中方案的优点是可以进行离线准备阶段
- 文中方案需要更少的数据库图像,并且增加原始数据时不会影响提取器,可以扩展到基于 crowsourcing 的方法。
六、文章总结
问题: 室内视觉定位的准确性和成本之间难以权衡
方法:基于图像检索的定位方法。
论证过程:
- 基于 CNN 的图像检索阶段,预训练的 DCNN 提取 CNN 特征,比较相似性,输出匹配的图像
- 位姿估计阶段。利用 2 张检索图像中提取特征点的 2D-2D 对应关系计算单目视觉 setting 中的尺度,利用特征点匹配计算查询图像位姿
- 通过数据集进行验证。
优点:
- 位姿估计精度高
- 构建数据库需要的图像少
- 无需 3D 模型
- 易用性好,应用前景好,方便扩展数据集,更换场景无需重新训练模型
缺点:
- 姿势估计的性能与查询图像和参考图像之间的相似性高度相关,具有较强的耦合性,模块间独立性较低,姿势估计的性能过于依赖图像检索
- 没考虑运动复杂和大规模场景,没有对系统长期运行性能做测试