很多工作的基础性工作,一直没机会正式阅读过论文,这次趁着这个机会学一下
一.背景
1.1 训练策略
将预先训练的语言表示应用于下游任务有两种现有策略:基于特征和微调。
1.1.1 无监督特征方法。
主要依赖于单词嵌入,后面推广到更大的细粒度如,句子嵌入和段落嵌入。 当将上下文单词嵌入与现有的特定任务架构相结合时,单词嵌入研究ELMo提高了几个主要NLP基准的技术水平
【可参考】ELMo原理解析及简单上手使用 - 知乎 (zhihu.com)
1.1.2无监督微调方法
产生上下文标记表示的句子或文档编码器已经从未标记的文本中进行了预训练,并针对监督的下游任务进行了微调。这些方法的优点是几乎不需要从头开始学习参数。
1.2 MLM(masked language model)
从输入中随机屏蔽一些标记,目的是仅基于其上下文来预测屏蔽词的原始词汇
1.3 主要贡献
- BERT使用掩蔽语言模型来实现预训练的深度双向表示。
- 预先训练的表示减少了对许多精心设计的特定任务架构的需求。
二. BERT
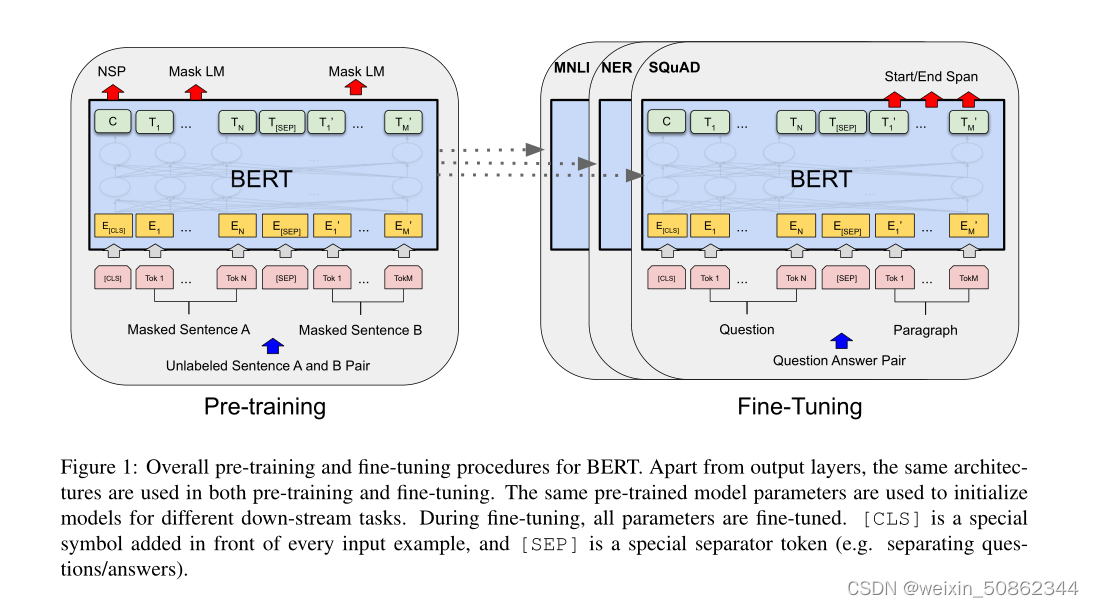
在预训练期间,在不同的预训练任务中,在未标记的数据上训练模型。对于微调,首先用预先训练的参数初始化BERT模型,并使用来自下游任务的标记数据对所有参数进行微调。BERT的一个显著特点是其跨不同任务的统一架构。预训练的体系结构和最终的下游体系结构之间存在微小的差异。
2.1 模型架构
模型架构BERT的模型架构是一种多层双向transformer编码器。
2.2 输入/输出表示
- “句子(sentence)”可以是连续文本的任意跨度,而不是实际的语言句子。
- “序列(sequence)”是指BERT的输入标记序列,它可以是一个句子或两个句子组合在一起。
- "special token"
- classification token ([CLS]):每个序列的第一个标记总是一个特殊的分类标记
- special token ([SEP]):句子对组合成一个单独的序列。(1)我们用一个特殊的标记([SEP])来分隔它们。(2)们向每个令牌添加一个学习嵌入,指示它属于句子a还是句子B。
- [MASK]:“屏蔽”单词
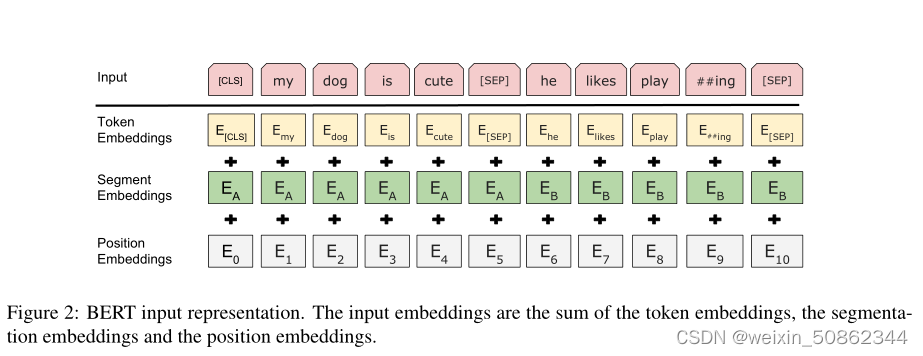
输入表示是通过对相应的令牌、分段和位置嵌入求和来构建的
2.3 预训练PERT
2.3.1 任务1:掩码语言模型(Masked LM)
深度双向模型严格地比左到右模型或左到右和右到左模型的浅级联更强大。因为双向条件反射允许每个单词间接地“看到自己”,并且该模型可以在多层上下文中预测目标单词。
训练深度双向表示:随机屏蔽一定百分比的输入令牌,然后预测这些屏蔽的单词的tooken。我们将该程序称为“Masked LM”
为了弥补[MASK]token在微调期间不会出现而造成的预训练和微调之间造成了不匹配:
(1)80%时间:[MASK]token
(2)10%时间:随机token
(3)10%时间:不变第i个token。
2.3.2 任务2:下一个句子预测
训练一个理解句子关系的模型,预先训练了一个二分类式的下一个句子预测任务
2.4 微调
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并端到端地微调所有参数。
论文后面是一些实验和消融实验,这里就不过多赘述了
三.代码
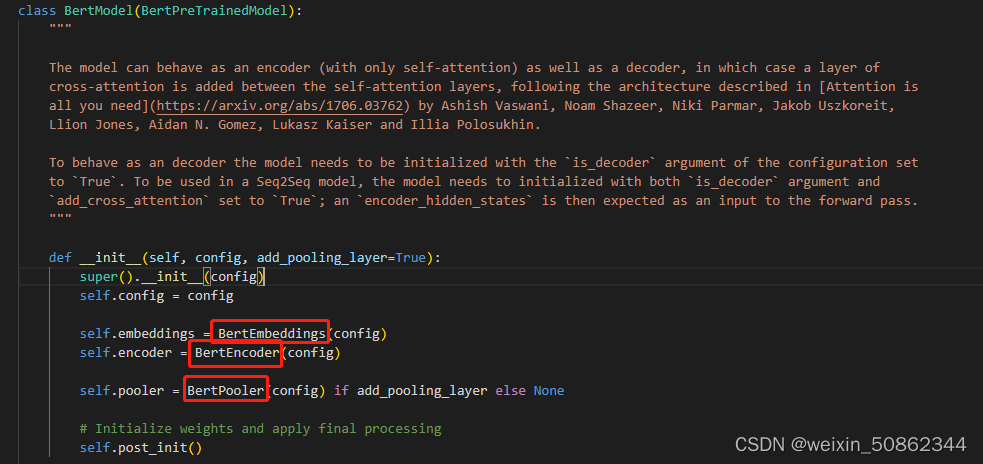
一个基本的Bert模型有BertEmbeddings,BertEncoder,BertPooler这三个部分组成
3.1 BertEmbeddings

每个输入标记由三个部分组成:单词嵌入(word embeddings)、位置嵌入(position embeddings)和标记类型嵌入(token type embeddings)
- 单词嵌入:为每一个单词根据上下文学习一个向量
- 位置嵌入:为输入序列中的每个标记分配一个嵌入向量,以表示其在序列中的位置。这些嵌入向量通常是通过学习得到的,并且根据标记在序列中的相对位置进行编码。
- 标记类型嵌入:主要用于处理句子级别的任务,如文本分类、句子关系判断等。它的作用是为模型提供关于标记所属句子的信息,帮助模型区分不同句子之间的关系。通常情况下,BERT模型中将输入序列划分为两个句子(例如,[CLS]句子1[SEP]句子2[SEP]),其中[SEP]标记用于分隔两个句子。
3.2 BertEncoder

由若干个BertLayer堆叠

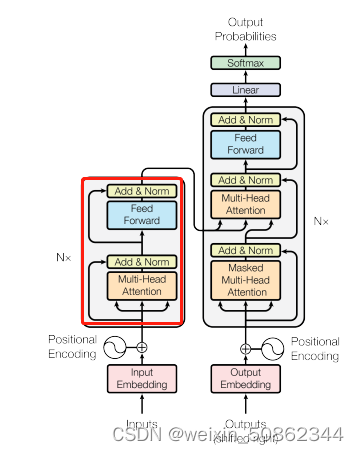
BertAttention其实就是一个多头注意力 +【 带激活函数的全连接 + 全连接输出】
【 带激活函数的全连接 + 全连接输出】其实也可以视为一个feed-forward结构,其实这里就是tranformer中encoder的结构
3.3 BertPooler

————————————————————————————————————————
其实对于bert就两个核心问题:1.怎么在所有层中联合调节上下文? 2.双向体现在哪里?
-
在BERT中,通过共享参数的方式在所有层之间实现上下文的联合调节。BERT模型采用了Transformer的多层堆叠结构,每一层都是由多头自注意力机制和前馈神经网络组成。每一层都有自己的参数,但这些参数是通过预训练阶段进行共享的。在预训练阶段,BERT模型使用大规模的语料库进行无监督的学习,通过训练来学习上下文信息。这样,在后续的微调阶段,BERT模型可以利用这些学到的上下文信息来对特定任务进行 fine-tuning,实现联合调节。
-
双向性是BERT模型的一个重要特点,体现在两个方面:
a. 输入表示的双向性:BERT模型采用了双向Transformer结构,即在处理输入序列时同时考虑了左侧和右侧的上下文信息。这是通过在Transformer中引入多头自注意力机制实现的,每个位置的表示会受到左侧和右侧所有位置的影响,从而使模型能够捕捉全局的语义信息。
b. 预训练的双向性:在BERT的预训练阶段,采用了两种预测任务:Masked Language Model (MLM)和Next Sentence Prediction (NSP)。MLM任务要求模型在输入序列中随机遮盖一些单词,然后预测这些被遮盖的单词;NSP任务要求模型判断两个句子是否是连续的。这两个任务都涉及到双向性的建模,即模型需要从上下文中推断被遮盖的单词或者判断两个句子的关系。通过这种预训练方式,BERT模型能够学习到双向的语义信息,并在后续的任务中受益于这种双向性。