六、逻辑回归(Logistic Regression)
6.1 分类问题
算法的性质是:它的输出值永远在0到 1 之间。
当 h θ ( x ) > = 0.5 {h_\theta}\left( x \right)>=0.5 hθ(x)>=0.5时,预测 y = 1 y=1 y=1。
当 h θ ( x ) < 0.5 {h_\theta}\left( x \right)<0.5 hθ(x)<0.5时,预测 y = 0 y=0 y=0 。
6.2 逻辑函数
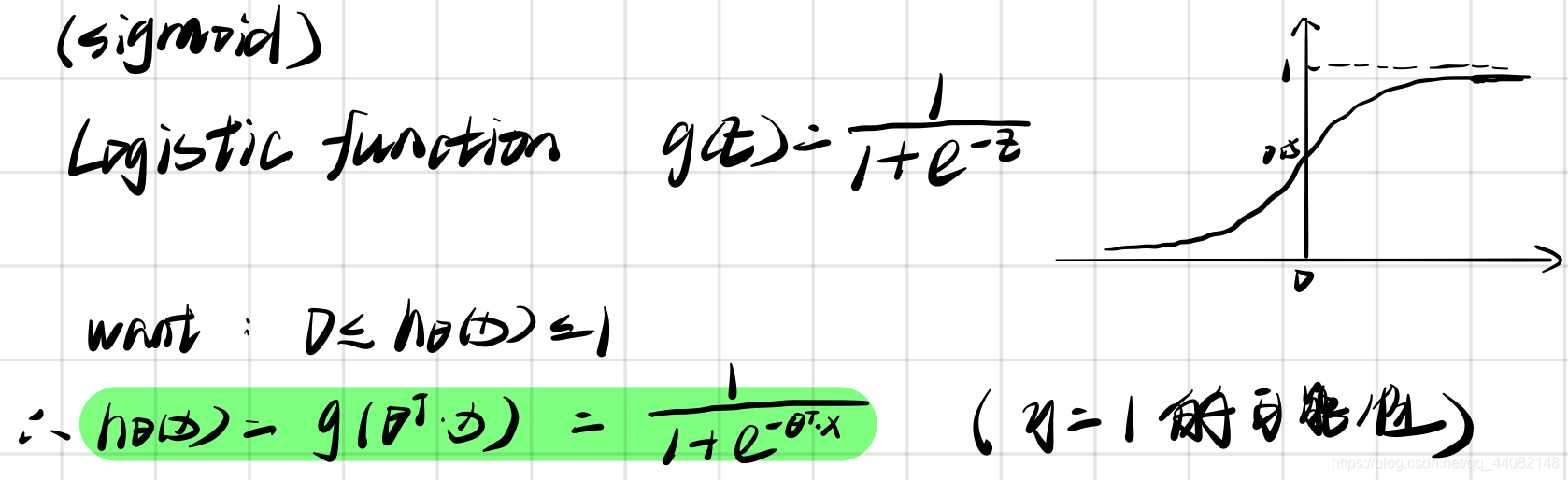
h θ ( x ) = g ( θ T X ) h_\theta \left( x \right)=g\left(\theta^{T}X \right) hθ(x)=g(θTX)
g ( z ) = 1 1 + e − z g\left( z \right)=\frac{1}{1+{ {e}^{-z}}} g(z)=1+e−z1
python代码实现:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
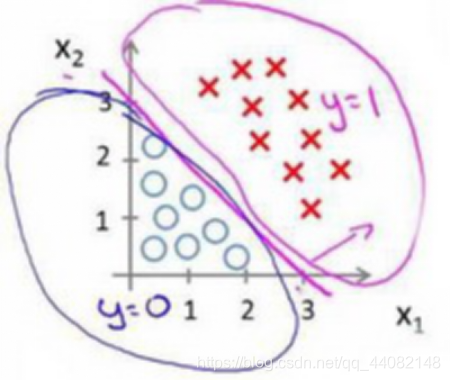
6.3 判定边界
面对不同的训练集,我们需要用不同的参数来拟合,也就是我们所说的 decision boundary(判定边界)

而这样的需要用曲线拟合的

6.4 代价函数(cost function)
由于sigmoid function的出现,会让以前的cost function出现很多个局部最小值
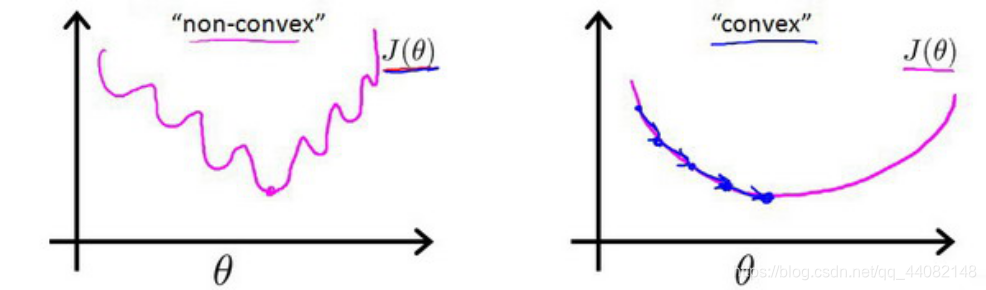 我们希望的是得到一个差不多像是右边的那一条曲线而不是左边那一条
我们希望的是得到一个差不多像是右边的那一条曲线而不是左边那一条
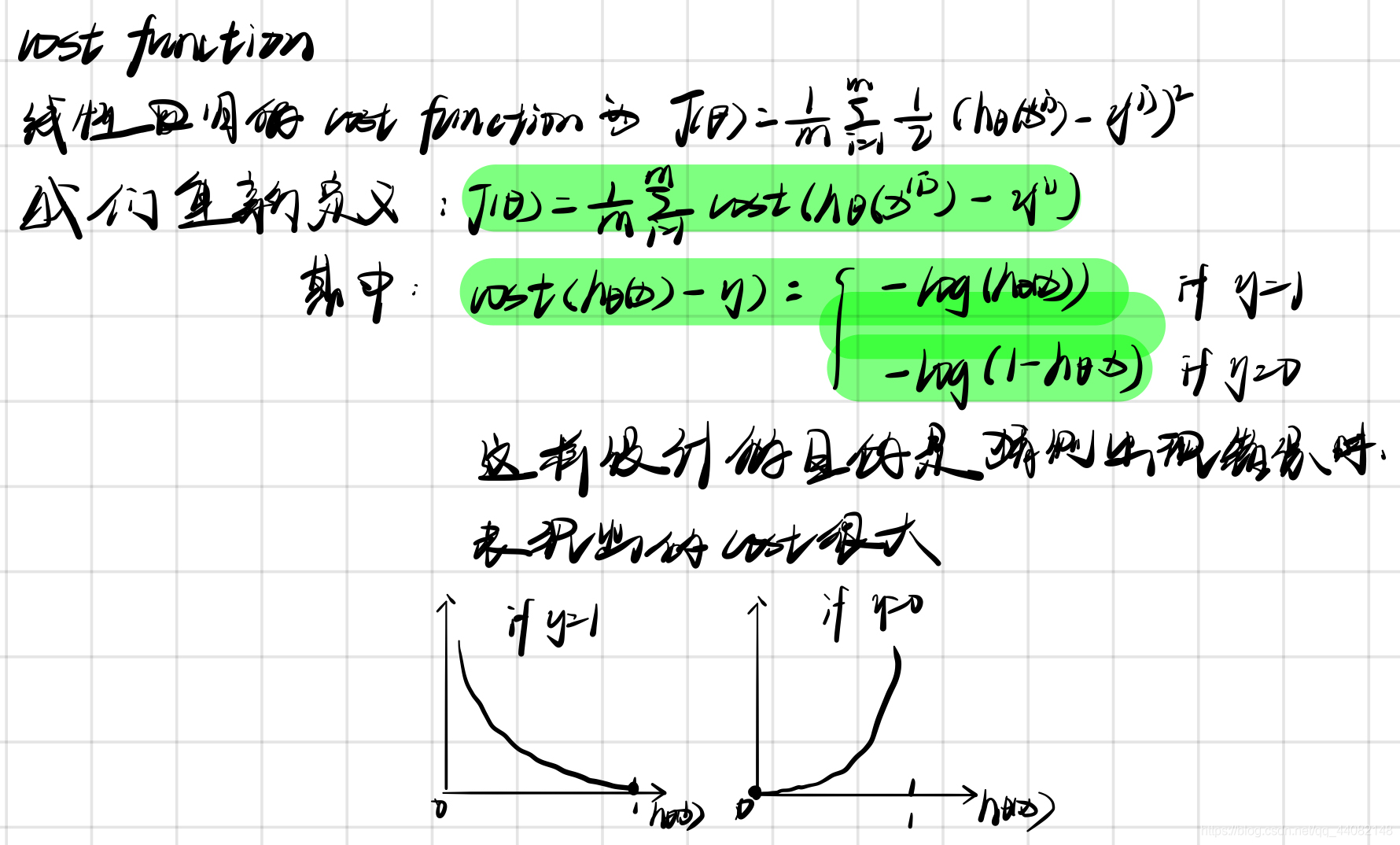
通过这样的操作,我们可以得到可以使用的cost function
J ( θ ) = 1 m ∑ i = 1 m 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{1}{2}{ {\left( {h_\theta}\left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ)=m1i=1∑m21(hθ(x(i))−y(i))2
6.5 简化的成本函数和梯度下降
-
简化cost function(其实就是把原本两行的写成一行)
重新定义逻辑回归的代价函数为:
J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x ( i ) ) , y ( i ) ) J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{ {Cost}\left( {h_\theta}\left( {x}^{\left( i \right)} \right),{y}^{\left( i \right)} \right)} J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))C o s t ( h θ ( x ) , y ) = − y × l o g ( h θ ( x ) ) − ( 1 − y ) × l o g ( 1 − h θ ( x ) ) Cost\left( {h_\theta}\left( x \right),y \right)=-y\times log\left( {h_\theta}\left( x \right) \right)-(1-y)\times log\left( 1-{h_\theta}\left( x \right) \right) Cost(hθ(x),y)=−y×log(hθ(x))−(1−y)×log(1−hθ(x))
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{ {y}^{(i)}}\log \left( {h_\theta}\left( { {x}^{(i)}} \right) \right)-\left( 1-{ {y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( { {x}^{(i)}} \right) \right)]} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
= − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] =-\frac{1}{m}\sum\limits_{i=1}^{m}{[{ {y}^{(i)}}\log \left( {h_\theta}\left( { {x}^{(i)}} \right) \right)+\left( 1-{ {y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( { {x}^{(i)}} \right) \right)]} =−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
Python代码实现:
import numpy as np def cost(theta, X, y): theta = np.matrix(theta) X = np.matrix(X) y = np.matrix(y) first = np.multiply(-y, np.log(sigmoid(X* theta.T))) second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T))) return np.sum(first - second) / (len(X)) -
梯度下降函数
Repeat {
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \frac{\partial}{\partial\theta_j} J(\theta) θj:=θj−α∂θj∂J(θ)
(simultaneously update all )
}求导后得到:
Repeat {
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j := \theta_j - \alpha \frac{1}{m}\sum\limits_{i=1}^{m}{ {\left( {h_\theta}\left( \mathop{x}^{\left( i \right)} \right)-\mathop{y}^{\left( i \right)} \right)}}\mathop{x}_{j}^{(i)} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
(simultaneously update all )
}
即使更新参数的规则看起来基本相同,但由于假设函数(h(x))的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
6.6 高级优化
共轭梯度法 BFGS (变尺度法) 和L-BFGS (限制变尺度法)
例如可以使用 scipy.optimize.minimize 来寻找参数